
提分杀器:模型集成(Ensemble)
参考博客
https://blog.csdn.net/dugudaibo/article/details/79145417
https://zhuanlan.zhihu.com/p/42229791
正文
把多个模型跑的结果综合起来,一般都会比一个模型的效果好上两三个点(视具体情况而定啊,反正阅读理解比赛是这样)
主要总结一下常用的模型Ensemble方法和原理。
从结果文件融合
不需要重新训练模型,只需要把不同模型在相同数据集上的测试结果弄出来,然后采取某种措施得出一个最终结果。
多数表决融合
直接投票,结果的差异性越高,最终模型融合出来的结果也会越好。
加权表决融合
多数表决的融合方式默认了所有模型的重要度是一样的,但通常情况下我们会更重视表现较好的模型而需要赋予更大的权值。在加权表决的情况下,表现较差的模型只能通过与其他模型获得一样的结果来增强自己的说服力。
对结果取平均
对结果取平均,可以在一定程度上减轻过拟合现象。
Stacking
也使用了投票的思想,在最后训练一个分类器来决定权重,整合结果。
训练数据也要分一部分来训练分类器。一般采用交叉验证的方法(K折交叉验证)
示例如下图:
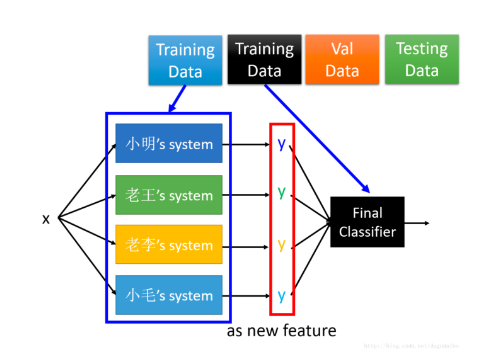
我们将这四个模型的输出作为 Final Classifier 的输入,将 Final Classifier 的输出作为最后的分类结果。在训练的过程中,将数据分为如上的四分,使用第一份数据训练这个简单的模型,之后使用黑色的数据输入之前训练的模型,然后再用他们训练 Final Classifier ,这里 Final Classifier 采用的是一个较为简单的模型,比如说逻辑回归。然后再用后面的数据进行验证和测试。
Blending
Blending与Stacking大致相同,只是Blending的主要区别在于训练集不是通过K-Fold的CV策略来获得预测值从而生成第二阶段模型的特征,而是建立一个Holdout集,例如说10%的训练数据,第二阶段的stacker模型就基于第一阶段模型对这10%训练数据的预测值进行拟合。说白了,就是把Stacking流程中的K-Fold CV 改成 HoldOut CV。
简单来说,Blending直接用不相交的数据来训练模型和分类器。
Bagging
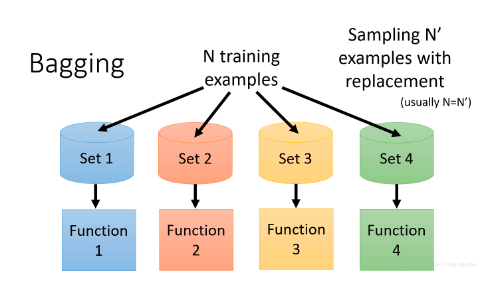
每个模型的训练数据都是不同的,利用可放回抽样总共获得N个样本,之后训练N个分类器,
对于回归问题取这N个分类器的均值,对于分类问题让这N个分类器进行投票。
这种方法主要用在抑制模型过拟合的问题
Boosting
Boosting的目的不是为了抑制过拟合,而是为了提高弱的分类器的性能
核心思想:首先他会获得第一个分类器 f1(x),然后找到第二个分类器 f2(x)来帮助第一个分类器 f1(x)。这个第二个分类器是什么样的机器学习算法都好,只要能够帮到第一个分类器 f1(x) 提高整体的性能;然而如果 f2(x) 与 f1(x)是很相似的话,那么它们就没有办法帮助他很多,我们希望我们得到的 f2(x)与 f1(x) 是互补的。然后我们就得到了第二个分类器 f2(x) ,最后组合所有的分类器。然而这其中有很重要的是,分类器是需要按顺序学习的,不像之前的分类器是可以分开学习的。
如何获得不同的分类器
关键的思想在于获得不同的训练数据。
重采样虽然可以获得不同的训练数据,但是每一个数据被采样的次数一定是整数,我们没有办法将一个数据采样2.1次或者0.1次。所以这个时候就要采用对数据重新赋权重的方法来获得不同的数据。如下图所示:

假设原始的权重都是1,更新之后的权重为图中所示的数,那么损失函数也要进行同样的改变,在计算某一个数据的损失值之后还要乘以他的权重。
Adaboost
Adaboost的思想在于它使用令分类器 f1(x)失败的数据进行训练得到 f2(x),之所以 f2(x) 所用的数据要使 f1(x)失败,其主要原因是为了使 f1(x)和 f2(x)互补 。
而所谓的是原来的分类器在新的数据上失败的含义就是,原来的分类器在新的数据集(调整完权重的数据集)上的分类的正确率为50%,使 f1(x)的效果在 f2(x) 所对应的新数据集上如同是在随机猜测一样。
Adaboost的详细见:https://blog.csdn.net/dugudaibo/article/details/79145417(反正我也没用过)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号