读取数据库内容,并在页面渲染
一、准备过程
- 安装MySQL并且配置环境。
- 准备SpringBoot的编译环境(由于之前一直使用的社区版IDEA,但是社区版暂未找到支持SpringBoot的相关插件,所以重新安装的旗舰版)。
二、计划安排
- 由于大二学习的知识储备有限,本次作业目标需要使用Spring Boot,axios以及vue的相关知识,所以通过b站上的教学视频进行入门学习。
- 由于时间比较紧张,没办法把视频全部看完, 所以只好先通过关键的章节学习最基础的知识,之后边学边做,在实现目标的过程中再通过视频,百度,CSDN等网站进行补充。
三、实现过程
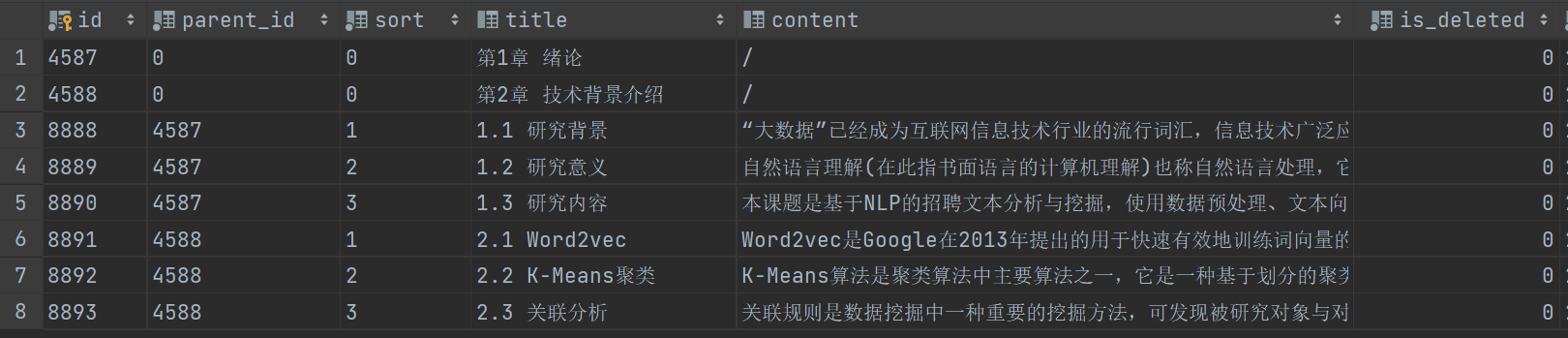
1.通过mySQL创建表。
DROP TABLE IF EXISTS `edu_paper`;
CREATE TABLE `edu_paper` (
`id` char(19) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '本段ID',
`parent_id` varchar(19) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '父段落ID',
`sort` varchar(19) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '排序',
`title` varchar(19) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '标题',
`content` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL COMMENT '内容',
`is_deleted` tinyint UNSIGNED NOT NULL DEFAULT 0 COMMENT '逻辑删除 1(true)已删除, 0(false)未删除',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modified` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '论文' ROW_FORMAT = Dynamic;
INSERT INTO `edu_paper` VALUES ('4587', '0', '0', '第1章 绪论', '/', 0, '2021-07-19 23:07:45', '2021-07-19 23:07:47');
INSERT INTO `edu_paper` VALUES ('4588', '0', '0', '第2章 技术背景介绍', '/', 0, '2021-07-19 23:11:34', '2021-07-19 23:11:36');
INSERT INTO `edu_paper` VALUES ('8888', '4587', '1', '1.1 研究背景', '“大数据”已经成为互联网信息技术行业的流行词汇,信息技术广泛应用。大数据带来的信息风暴正在变革我们的生活、工作和思维[1]。大数据的数据来源众多,数据类型丰富,包括结构化和非结构化数据。但面对如此众多的数据,如何通过一系列的分析与挖掘,解决各种各样的难题,从数据中得到对我们有帮助的信息,需要通过长时间的研究才能得到答案。', 0, '2021-07-19 23:08:43', '2021-07-19 23:08:46');
INSERT INTO `edu_paper` VALUES ('8889', '4587', '2', '1.2 研究意义', '自然语言理解(在此指书面语言的计算机理解)也称自然语言处理,它是计算语言学的分支,是人工智能研究中一个十分活跃的领域,自然语言理解从简单的语言信息处理到理解篇章,会话,走向认知科学,经历了二十年的发展历程[2]。随着高科技的迅速发展,其应用深入人们生活的各个方面[3]。对于本课题来说,使用自然处理技术对招聘文本进行分析的价值在于,一是对于大学生学习来说,这个模型可以帮助他们加强技术的学习;二是对于大学生就业,当面对海量招聘信息无法确定最合适自己的岗位时,这个模型可以根据自身所学的技术推荐合适的岗位;三是对于学院的学科建设,由于计算机技术每年变动较大,这个模型可以帮助老师调整教学计划,跟上社会的技术变动。', 0, '2021-07-19 23:09:24', '2021-07-19 23:09:26');
INSERT INTO `edu_paper` VALUES ('8890', '4587', '3', '1.3 研究内容', '本课题是基于NLP的招聘文本分析与挖掘,使用数据预处理、文本向量化、自然语言处理(NLP)、关联分析等技术对招聘文本进行分析与挖掘。主要内容为:提取所需数据,去除“脏数据”,对数据进行分句分词操作。进行文本向量化操作。利用K-Means聚类算法获取技术名词列表。', 0, '2021-07-19 23:10:39', '2021-07-19 23:10:42');
INSERT INTO `edu_paper` VALUES ('8891', '4588', '1', '2.1 Word2vec', 'Word2vec是Google在2013年提出的用于快速有效地训练词向量的模型[4]。通过将文本数据输入到一个学习模型中,Word2vec输出的词向量可以表示为一大段文本,甚至整篇文章[5]。word2vec有连续词袋模型(Continuous bag-of-words,CBOW)和Skip - Gram两种模型。word2vec能够将文本词语转化为向量空间中的向量,而向量的相似度可以表示文本语义的相似度[6]。Xxxxxxx', 0, '2021-07-19 23:12:22', '2021-07-19 23:12:25');
INSERT INTO `edu_paper` VALUES ('8892', '4588', '2', '2.2 K-Means聚类', 'K-Means算法是聚类算法中主要算法之一,它是一种基于划分的聚类算法[7]。K-Means算法因其在大型数据集聚类方面的效率而闻名[8]。', 0, '2021-07-19 23:13:26', '2021-07-19 23:13:29');
INSERT INTO `edu_paper` VALUES ('8893', '4588', '3', '2.3 关联分析', '关联规则是数据挖掘中一种重要的挖掘方法,可发现被研究对象与对研究对象有影响的各因素之间的关联关系[9]。', 0, '2021-07-19 23:14:17', '2021-07-19 23:14:19');
SET FOREIGN_KEY_CHECKS = 1;
2.使用SpringBoot框架搭建后端接口
本接口的目标是接收从前端传入的id,返回该章节的标题及其子章节的详细内容。
首先是配置配置文件。
# springboot 核心配置文件
# 更改项目端口号
server.port=3000
#数据库相关配置
spring.datasource.url=jdbc:mysql://localhost:3306/paper?serverTimezone=GMT%2B8
spring.datasource.username=root
spring.datasource.password=0000
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.jpa.properties.hibernate.hbm2ddl.auto=update
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect
spring.jpa.show-sql= true
由于是跳过Spring的学习直接观看SpringBoot的教学视频,很多知识点不知道调用原理,暂时只能模仿视频中的做法来。关于Spring中的@RestController,@RequestMapping等标签,都还停留在“能跑起来就算成功”的水平。
本接口的主要目的是返回查询的id内容,因此主要是通过调用SQL查询语句实现。虽然以前学过JDBC,但是由于上网查找资料时找到为SpringBoot封装的jdbcTemplate类,还是尝试使用了新知识实现。
遇到的问题:
在调用jdbcTemplate下的方法时,直接通过String传入SQL指令可能会导致注入等问题。虽然可以直接查找全表然后用循环对表内所有数据进行查找,但明显效率会降低。
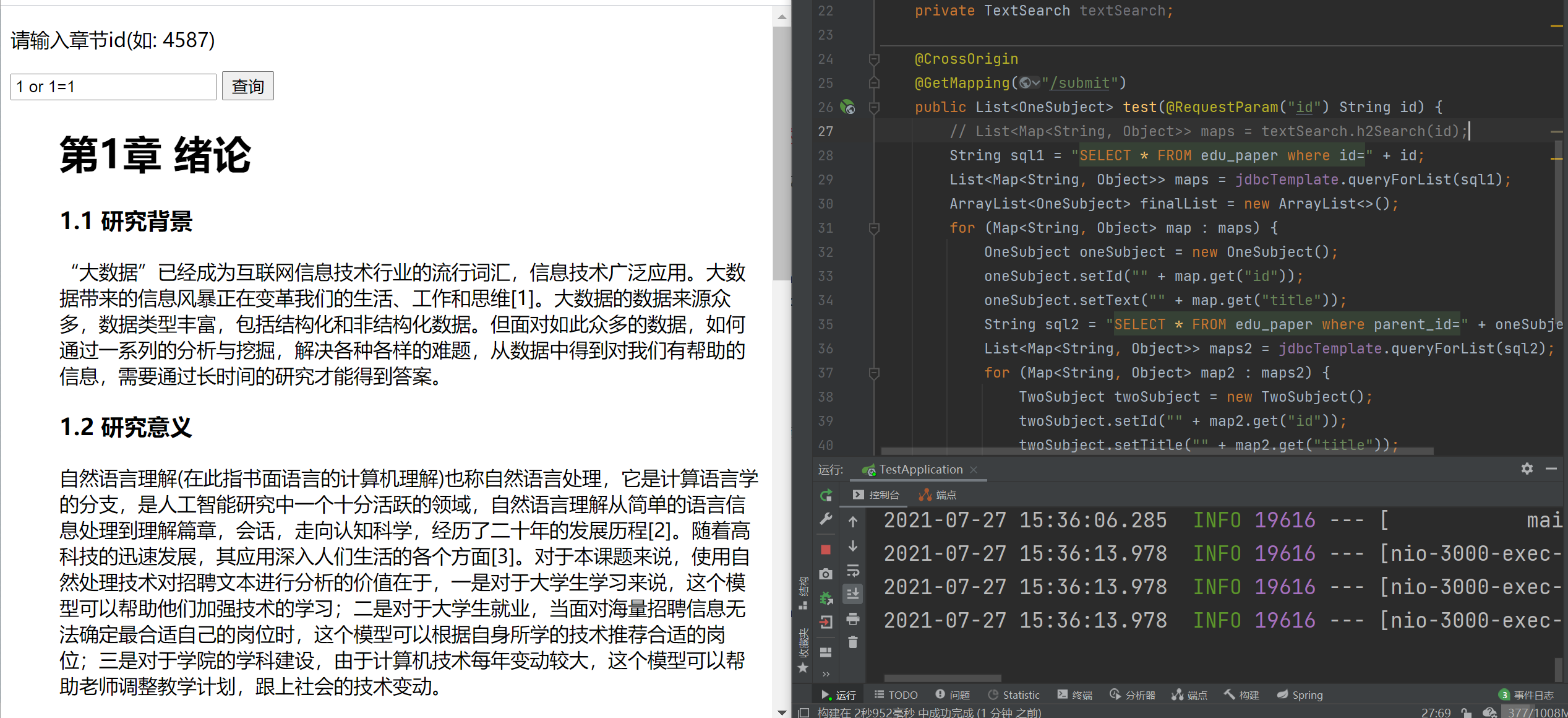
最后的解决方案是在调用jdbcTemplate中的queryForList方法时,直接通过重载的方法导入占位符。这样不仅可以防止SQL注入,同时也解决了传入参数不符合条件时的SQLSyntaxErrorException异常问题。

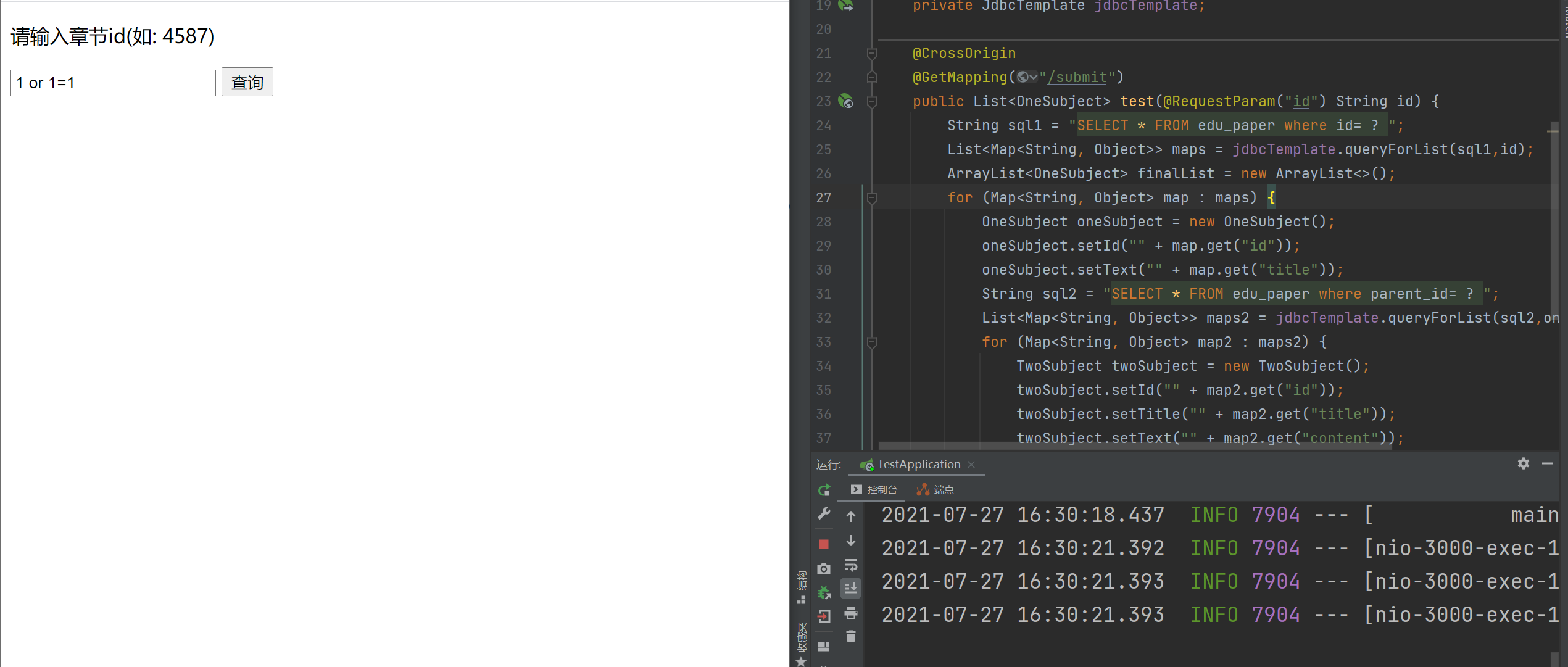
由于最终要返回筛选出来的内容,因此最终返回的应该是一个包含所需数据的对象。由于对象的内部还包含有树状层次的集合对象,所以封装了两个POJO类,分别存储不同级别的数据。
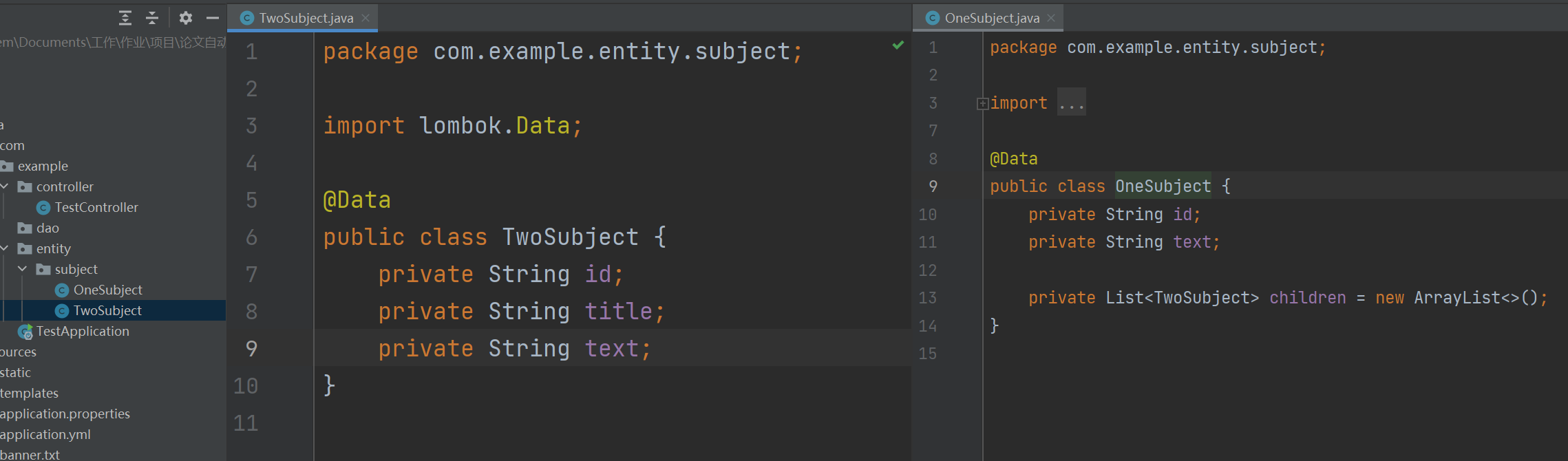
本题其实返回一个对象数据即可,不过考虑到未来可能会需要筛选出多个结果,我还是将筛选的对象封装到集合中传出。
@RestController
public class TestController {
@Autowired
private JdbcTemplate jdbcTemplate;
@CrossOrigin
@GetMapping("/submit")
public List<OneSubject> test(@RequestParam("id") String id) {
String sql1 = "SELECT * FROM edu_paper where id= ? ";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql1,id);
ArrayList<OneSubject> finalList = new ArrayList<>();
for (Map<String, Object> map : maps) {
OneSubject oneSubject = new OneSubject();
oneSubject.setId(map.get("id").toString());
oneSubject.setText(map.get("title").toString());
String sql2 = "SELECT * FROM edu_paper where parent_id= ? ";
List<Map<String, Object>> maps2 = jdbcTemplate.queryForList(sql2,oneSubject.getId());
for (Map<String, Object> map2 : maps2) {
TwoSubject twoSubject = new TwoSubject();
twoSubject.setId(map2.get("id").toString());
twoSubject.setTitle(map2.get("title").toString());
twoSubject.setText(map2.get("content").toString());
List<TwoSubject> children = oneSubject.getChildren();
children.add(twoSubject);
}
finalList.add(oneSubject);
}
return finalList;
}
}
3.搭建界面以及使用Axios实现前后端交互
界面的搭建需要导入vue和axios两个js文件。通过axios实现前后端数据的交互,然后通过vue将结果渲染到界面上。
首先在方法里通过get方法将数据传入url指向的后端接口,再利用then接收返回的结果。
对界面上的主要难点是在axios的交互与渲染网页时的问题。这里出现的问题是在标签上。一开始我尝试使用li标签,将结果在界面上显示。但是由于我返回的是一个多层嵌套的集合,子对象下还有一层集合需要显示。由于li元素之间的独立性(这块原理我其实不清楚),导致两层循环之间的数据无法交互。
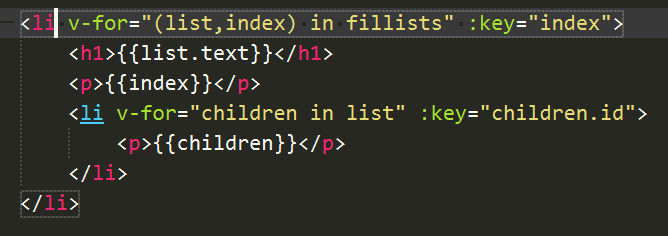

解决方案是将容器换成div,就可以正常执行了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号