第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目作业 |
| 这个作业的目标 | 论文查重项目、PSP表格、单元测试、性能分析、异常处理 |
Github链接:点我
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 50 | 30 |
| Estimate | · 估计这个任务需要多少时间 | 40 | 35 |
| Development | 开发 | 300 | 225 |
| Analysis | · 需求分析 (包括学习新技术) | 40 | 35 |
| Design Spec | · 生成设计文档 | 25 | 23 |
| Design Review | · 设计复审 | 20 | 17 |
| Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| Design | · 具体设计 | 20 | 30 |
| Coding | · 具体编码 | 25 | 40 |
| Code Review | · 代码复审 | 40 | 23 |
| Test | · 测试(自我测试,修改代码,提交修改) | 35 | 47 |
| Reporting | 报告 | 40 | 55 |
| Test Repor | · 测试报告 | 20 | 25 |
| Size Measurement | · 计算工作量 | 20 | 15 |
| Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 35 |
| 合计 | 685 | 655 |
计算模块接口的设计与实现
实现流程
在查看许多资料后,了解到有很多用于计算文本相似度的算法,例如余弦定理、海明距离、欧氏距离, SimHash 算法等,最后还是选择用 MinHash 算法来实现本次的作业。
python 中有写好的 MinHash 库可以调用,做起来比较容易,不需要自己去实现。
MinHash 中认为,随机从所有特征中抽样来进行比较,和用全部特征进行比较,在数学上,能得到一样的效果。
计算的主要流程
- 先从命令行的参数中获取三个文件的绝对路径,并且打开文件,得到文件中的数据
- 将文件中的数据进行处理(除去 html 标签,标点符号等),分词后,提取器中的关键字
- 调用 MinHash 中的函数,计算两个文档的关键字的相似度
关键函数
命令行参数获取文件路径

提取关键字
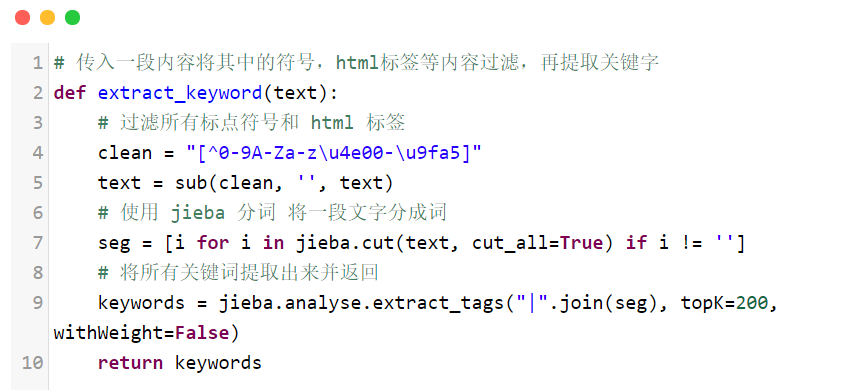
使用正则表达式将文章中的标点符合和 html 标签都过滤了,并且用 jieba 分词库 进行分词,提取关键词后返回。
MinHash 算法

计算模块接口部分的性能改进
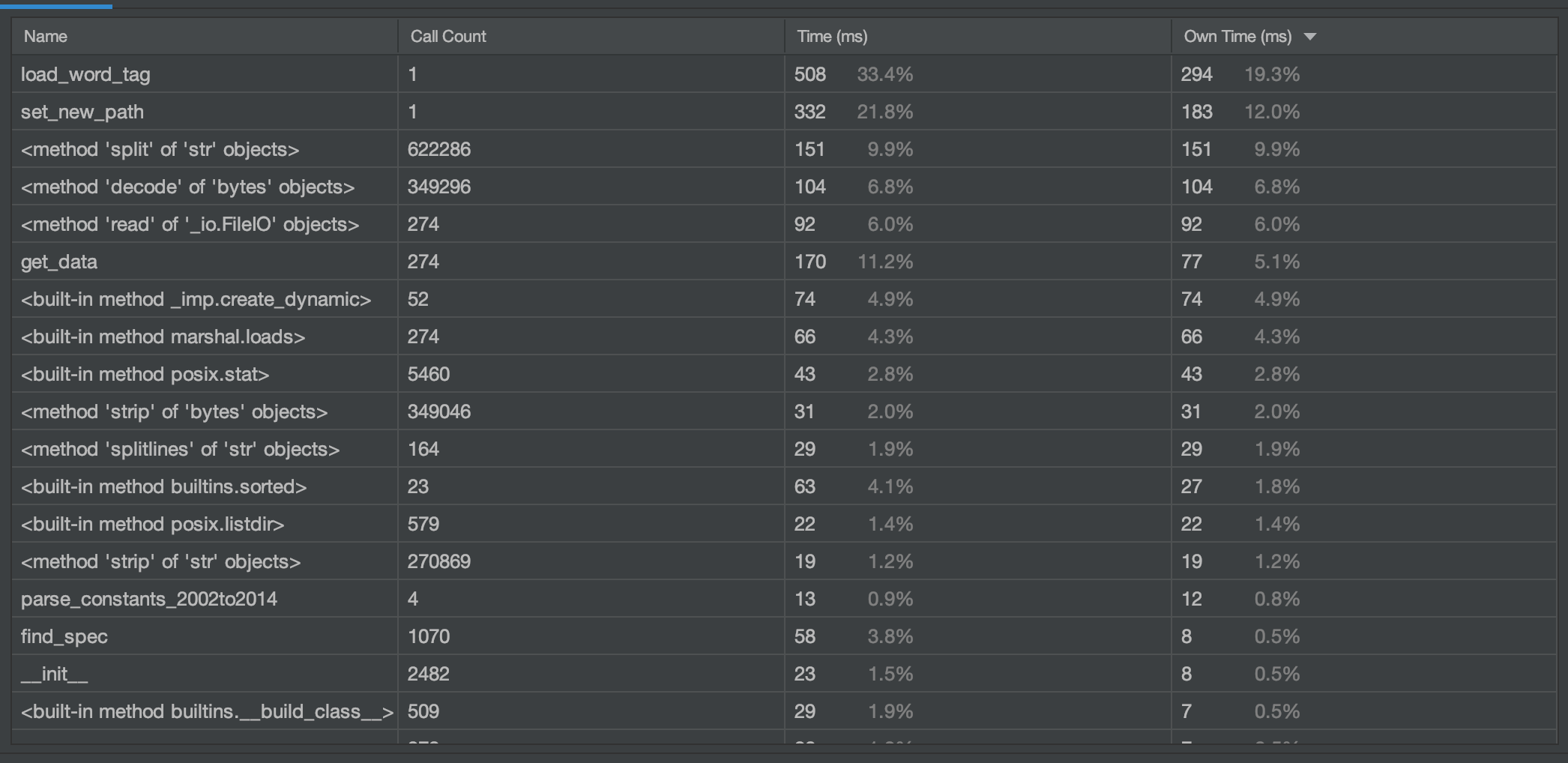
性能分析图
消耗较大的函数
计算模块部分单元测试展示
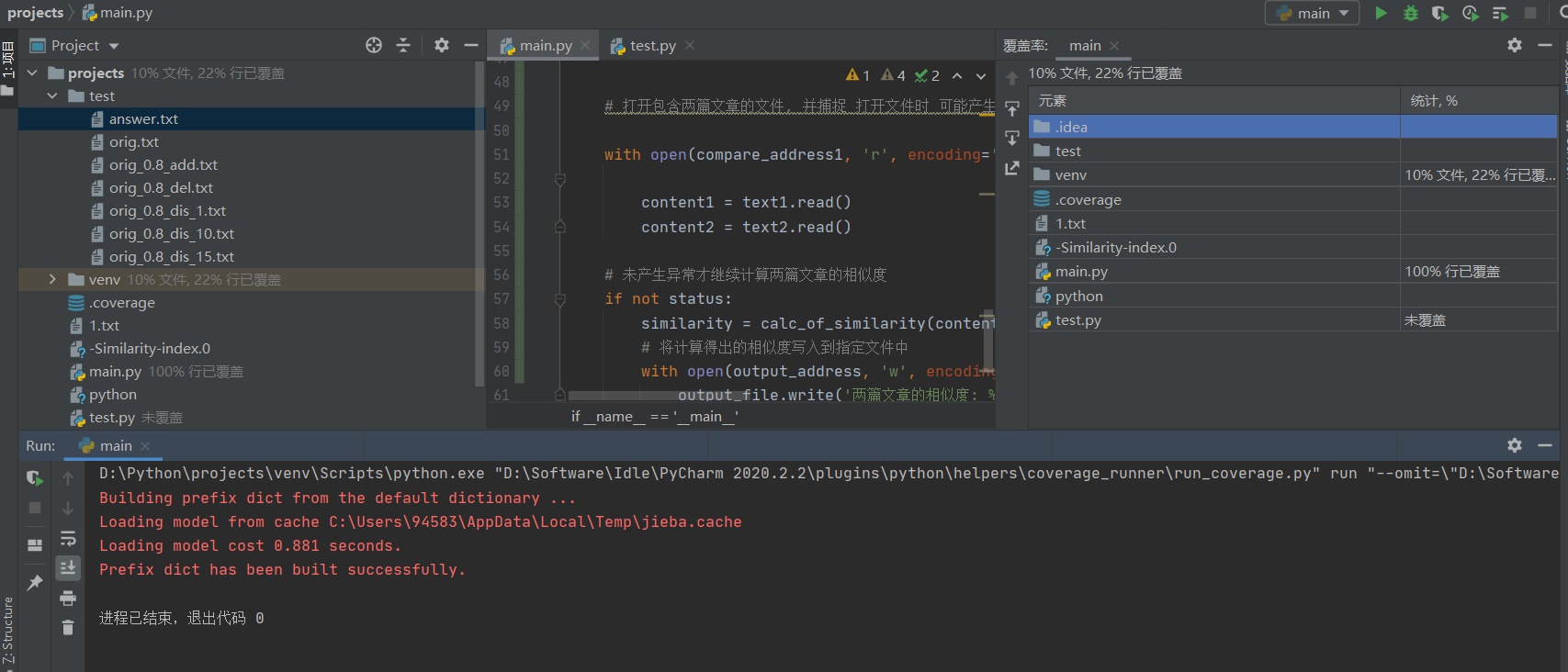
单元测试代码

使用的是 pycharm 自带的单元测试 unittest , 计算两个字符串的相似度。
测试结果

两个字符串的相似度为0, 符合预期结果。
代码覆盖率
计算模块部分异常处理说明
命令行参数没有输入三个完整文件的路径
处理方法
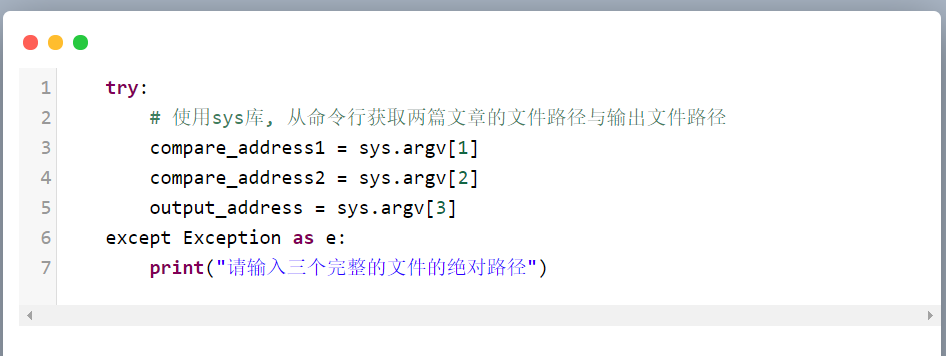
测试样例
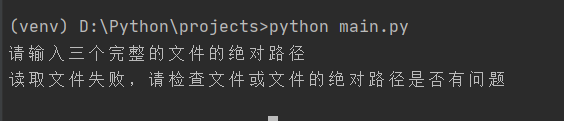
输入的三个文件路径有问题
处理方法

测试样例


 浙公网安备 33010602011771号
浙公网安备 33010602011771号