面向对象第四单元及学期总结
本单元架构设计
本单元立足于对UML图的理解,编写程序实现对UML图的查询操作。重点其实是对UML图的理解而非是查询算法的实现。
第一次作业
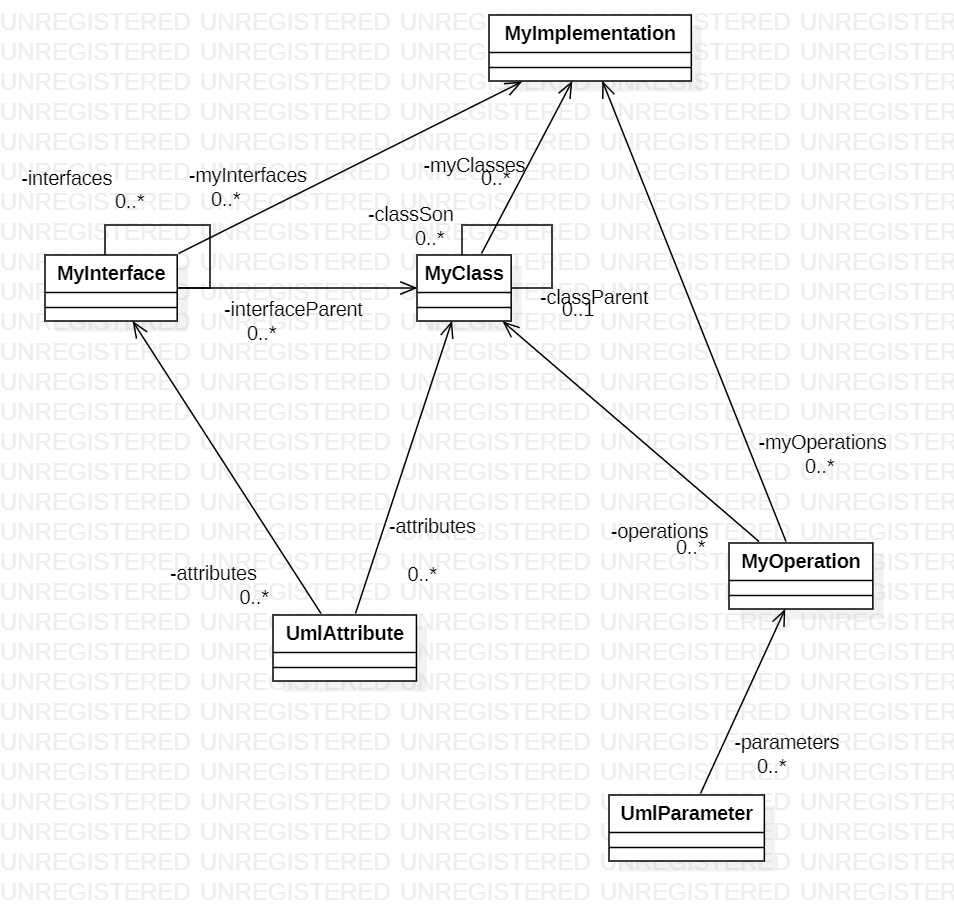
范围限定在了UML类图,通过每个元模型的id和parent_id,可以直接找到各元模型的包含关系,一个元模型的父亲只有唯一的一个,所以整体的UML架构是树。
基于以上思路,可以直接以各类元模型的类型作为新建的类,1个UMLClass类中可以包含有多个UMLAttribute对象和UMLOperation对象,而1个UMLOperation对象又可以包含多个UMLParameter对象。官方包给出的类中并不能展现出这种包含关系,于是就只能自己建类。起初本想建立一个MyClass类,以UMLClass为父类,但UMLClass的公有构造方法涉及到了对json文件的解析,我也只好放弃,打算直接构造一个全新的类,每个类中至少包含有id和name两个属性。部分类中也含有parent_id和visibility属性。
而要想达到将每个元模型准确地放在对应的父目录下,必须要进行多次循环遍历。
第二次作业
个人感觉本次作业是三次作业中最简单的一次,只需要照着第一次作业依葫芦画瓢即可。本次作业范围新增了UML状态图和UML顺序图。
同样的,根据各类元模型的包含关系建类并循环遍历使得要求的元模型一个个入坑。
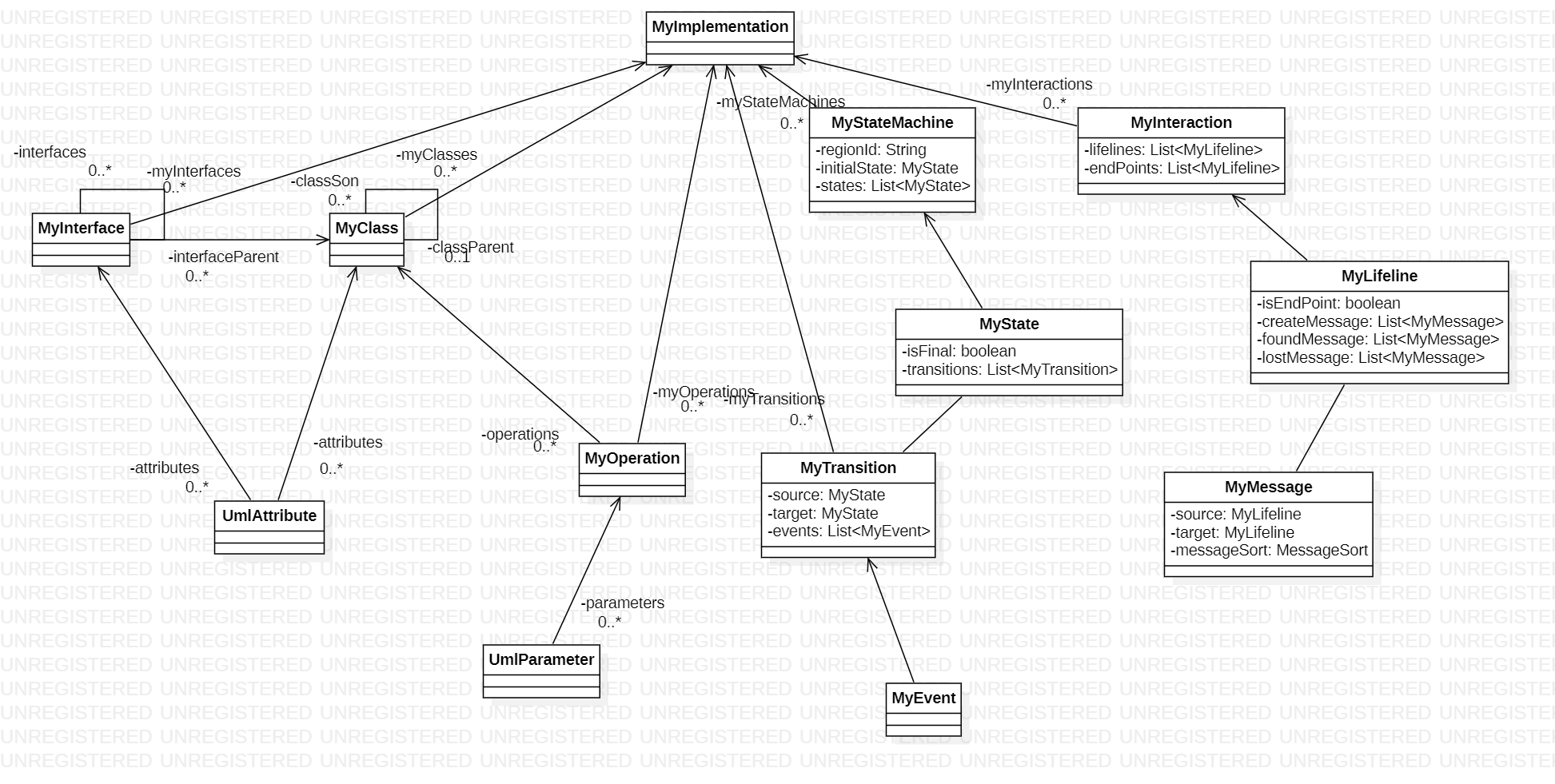
第三次作业
本次作业需要检查UML模型中矛盾或错误的地方并指出错误类型。算法实现时,这些错误类型可以分为两大类,一类是在循环遍历时进行检查,另一类是在遍历完所有元模型后进行检查。理论上讲,所有错误都可以在循环遍历过程中一边遍历,一边检查,但部分错误类型在遍历完后进行检查会更加方便,譬如检查是否存在循环继承和重复继承。但部分错误类型只能在遍历过程中进行检查,譬如检查是否一个Lifeline销毁后仍接收消息。
在实现过程中,我认为本次作业难点在于循环继承和重复继承,因为它们都需要考虑到所有循环/重复继承情况,并将其全部打印出来。而其中又以接口的循环继承为首,因为接口是可以多继承的。两者的本质实际上是图的检验,循环继承需要把各回路的节点全都找到,重复继承则是判断某两个节点间是否存在大于1条的路径。具体对每个节点都采用DFS算法,并维护已找到的有问题节点。
为更好的实现检查错误功能,将循环遍历等初始化操作移至MyParser类中。减少MyImplementation中的代码量。UML类图与第二次作业相似,在每个类中都增加了一些检验是否错误的操作。
四个单元中架构设计思维及OO方法理解的演进
第一单元
回首往昔,第一单元至今仍是印象深刻。其实刚开始真的啥也不会,幸好有实验代码可以借鉴借鉴,照猫画虎也是有点难度的,在这个单元里用了最多的时间。表达式、项、因子,这三个类层层关联,就是把每一次操作下放到另一个类的操作里,表达式因子的存在则需要让我们想到递归这个逻辑。在把操作下放的过程中,要分析好调用者如何利用被调用者返回的值。从面向过程的角度来讲,就是多个函数来回调用,但面向对象的优势在于它通过设置变量的可见性,能够清晰表明变量不会被滥用,继承和实现关系也方便了我们的优化和扩展。
第二单元
java的多线程对我而言又是一个新概念。我们可以将同步运行的一些类作为单独的线程,用锁或者同步块的形式实现对临界区的访问。这个单元学到了很多模式,单例模式、生产者消费者模式、策略模式、状态模式。值得注意的是notifyAll()的使用必须要仔细思考,当时的理解不是特别深,但后来OS学到进程时才有这个感触,这个唤醒操作几乎是造成所有轮询和死锁的罪魁祸首。
第三单元
JML规格是一个很有用的语言,因为它消除了自然语言的二义性。本单元整体的架构都是按照规格来的,具体的实现可以多种多样不必细说,规格里设置的方法倒很有讲究,addMoney()明显是比setMoney()更好的一个方法。要想更好的实现JML规格,必须能有一些变通之法。已计算过的值或许可以用新的属性保存起来,可以大大节省时间。本单元的社交网络架构或许是我学到最多的一个东西了,后两次作业的扩展都很少改变前次作业的代码。
第四单元
理清要实现的架构是编写代码的先验条件。每个元模型的含义、内部属性、与其他元模型的关系是我们要深入研究的对象。除了对UML模型更加了解外,再一次体会到了不同类依次向下调用方法的清晰思路,这减少了很多顶层的代码量,并且依次调用的逻辑清晰,在debug时也能很快定位到究竟是哪一个方法出了问题。
四个单元中测试理解与实践的演进
第一单元实在是没什么时间做测试机,这样一来也只能自己手动构造数据,主要还是针对优化的部分做测试,如果没有任何优化单纯去括号的话几乎不会有太多bug,三角函数的合并我就果断放弃了。因此多构造一些含有同类项的数据或许会有更大的发现bug几率。
第二单元主要难点在于评测,测试数据的生成可以十分简单,比如100个人同时从A栋2层出发到B栋5层。期间时不时的加几部电梯就可以hack到别人了。评测需要考虑的东西太多了,人是否全部到达终点,开关门是否有问题,电梯是否突然跳跃等,所以只能设置一些自己最可能出错的条件来判断。在互测时几乎不太会看大家的代码,直接覆盖性轰炸就是了。
第三单元的测试手段多了个JUnit,不过涉及到图的算法时还是需要更加准确地判断。JUnit用起来十分方便,但最主要的是自己能否想到所有可能的条件,这需要结合JML的前置条件进行思考,这么一来,在情况不多时,或许直接用标准输入输出进行比较也有较高的效率。
第四单元就直接在starUML上构造数据了,手动硬搓,所以不能太复杂,不能用一次大数据覆盖性测试,不然自己都不知道答案几何了。
课程收获
java让我体验到了c语言体验不到的乐趣,正则表达式简直就跟开挂一样,java有很多方法能对字符串进行处理,当初学c语言的时候字符串让人十分头大。
面向对象本身就十分实用于迭代开发,设计类时会思考需要暴露什么给外界,什么东西又是自己特有的。在创建类的同时就也在思考整个框架的构建。规范化和层次化是后两个单元主要学习的东西,在面向对象的程序编写中,我也会自然而然的从这些顶层框架入手,这是我们在大型开发过程中不会出现删库跑路情况的重要步骤。继承和接口是实现顶层框架的重要元素。
OO课程组也带来了很多帮助,每一次实验代码都凝聚着助教们的经验,每次答疑都会用心的告诉我们可以怎样解决,自我检索能力是一个必要的学习技能, 不得不说在难受到抓狂的时候也还考验着我们的心态。
改进建议
2.互测是否可以有更大的限制呢?互测的目的是锻炼大家阅读他人代码的能力,但如果凭借着覆盖性测试去寻找bug的话,和强测就没什么区别了,也会对debug带来不必要的麻烦。比如第二单元不同的策略有不同的适应环境,而如果拿极端的数据进行测试很有可能会让某个策略的电梯超时,每个电梯输入都会有一个理论上的最佳策略,但这个最佳策略却不一定能够满足所有的电梯输入。所以测试数据最好可以尽量满足生活吧,一次性接收到100个人请求的这种数据就是为了测试而测试。虽然有人觉得互测应该和公测限制一样,但这样子跟强测就没区别了,当然,这都是个人看法哈。
3.理论课和实验课感觉有点脱节,虽然我觉得理论课讲的确实很有深度和价值,但实验课仍然是需要自己去自学很多东西,当然我不反对这种模式,因为自己也可以学到更多东西。但个人觉得第四单元的作业相比于其他三个单元不是特别有必要,知道怎么应用UML图就可以了吧,对UML图的查询和有效性检查不如放在第一单元起到一个过渡的作用,因为第一单元是在是太难了啊。
4.checkstyle得吐槽一下,为什么import后面不能有*

 浙公网安备 33010602011771号
浙公网安备 33010602011771号