面向对象第三单元总结
代码架构设计
本单元主要学习了JML(Java Modeling language)的语法及使用。可根据函数要求自行编写JML规格,也可以通过已有的JML规格编写具体的实现代码。一般来说这种规格并不限制我们的具体实现,但实际上我们在实现有的方法时几乎就是完全按照规格的写法来写的,或许也是因为部分方法较为简单的缘故(一般都是这种\* pure *\纯纯的方法不费脑子了)这样照着规格写很直白。事实上我们也的确需要做一些变通,如果数组大小会变的话,就需要使用大小可变的容器,如果两个属性是一一对应的话,可以考虑用map容器把两者关联起来。
JML是一种契约式设计规格,调用者需要保证前置条件满足,而被调用者则需要保证后置条件满足。事实上本单元相关的JML已经将所有情况都考虑到了,若调用者没有满足正常情况下的前置条件,则被调用者会通过抛出异常的方式提醒调用者。异常是逐渐往上传递的,直到被try/catch块捕获。所以一个适应性强的代码一定会在调用函数前考虑到所有情况,并在本级通过捕获异常来进行解决,否则若出现莫名的运行时异常逐级向上报告极有可能导致整个程序瘫痪。当然,若本级无法处理该异常,或者这个异常是由上一级函数考虑不周所引发的,则必须把异常抛给上层函数,这样一来代价也是较大的。
第1次作业
这次作业初步了解JML的样式和风格,手册上的东西还是很好理解的。
本次作业实现了3个类,分别是Network、Group、Person类。目的是构建一个社交网络,这三个类之间相互是有一定关联关系(Association)的。Network理解为社交网络,其中包含了Group数组表示所有群组,包含了Person数组表示所有人。Group群组中自然也会有Person数组表示这个群里的人,而Person中有一个Person数组表示好友列表中的人。这一切的构造与当下的社交网络十分相似,这也使得我在理解JML时更加轻松。
如果是按照正常社交平台管理的话,Person类中应该还会有Group数组,表示这个人所加入的群组,这或许能让后面一些指令的实现变得容易一些。
本次作业的难点在判断两个人是否能通过彼此的好友直接或间接的联系,判断整个社交网络被分成了多少块。从图的角度理解的话就是判断两个节点是否可达,整个图有多少连通块。
针对本次作业,并查集是一个较好的数据结构。考虑到只有加边加点的情况,直接维护一个ArrayList<ArrayList<Person>>数据结构,不用父节点,内层List代表同属一个连通块的人,外层List代表不同的连通块。
第2次作业
新增一个要实现的类Message,表示发送的消息,这个消息也很灵性,有群发和私发两种类别,完全符合当下的社交网络。
Message的实现给Network带来了一定的复杂度,像sendMessage这个方法的JML就一大片,考验人的耐心。
本次作业的难点在于实现最小生成树,不过这个功能在社交网络中貌似没有对应的用处。
最小生成树的得出有Prim和kruskal算法,两者应该都行,可以新生成一个Node或Edge类便于排序等等。
第3次作业
细化了Message的类型,有通知消息,红包消息,表情消息。值得一提的是,根据消息类型的不同,第二次作业实现的sendMessage方法会更加复杂,三种消息都有各自的特点,均继承于Message类。但群发红包的设定和算年龄方差不能有小数点会有点不合实际。
本次作业难点在于最短路径的生成,这可以理解为两个人之间取得联系至少需要多少的社交价值。
堆优化的迪杰斯特拉算法是官方给的正解,为此我也专门去看了PriorityQueue容器,这必须得生成一个额外的类保存边或顶点的信息了。
代码测试部分
本次代码测试使用了自己构造数据和JUnit两种方法。
针对于自己构造的数据,主要是检验图的算法的正确性,数据没必要花里胡哨,只要实用就行。
def useInput():
i = 1
while i <= 200:
print('ap %d %s %d' % (i, generate_random_str(i % 3 + 3), i % 30))
i += 1
i = 1
while i <= 1450:
if i % 10 == 0:
print("qbs")
print("qlc %d" %(random.randint(1,200)))
res = random.sample(range(1, 200), 2)
print("ar %d %d %d" % (res[0],res[1],random.randint(1,10)))
i += 1
i = 1
while i <= 50:
res = random.sample(range(1, 100), 2)
print("qci %d %d" %(res[0],res[1]))
i += 1
for i in range(50):
print("qv %d %d" %(random.randint(1,100),random.randint(1,100)))
print("qps")
for i in range(100):
print("ag %d" %(random.randint(1,100)))
for i in range(50):
print("atg %d %d" %(random.randint(1,100),random.randint(1,100)))
for i in range(50):
print("dfg %d %d" %(random.randint(1,100),random.randint(1,100)))
for i in range(100):
print("am %d %d %d %d %d" %(i,random.randint(1,10),0,random.randint(1,200),random.randint(1,200)))
print("sm %d" %(i))
for i in range(100):
print("qsv %d" %(random.randint(1,200)))
print("qrm %d" %(random.randint(1,200)))检验连通块的个数:
import networkx as nx
import matplotlib.pyplot as plt
def countBlocks():
if G.edges == 0:
print(0)
return
blocks = 0
for c in nx.connected_components(G):
blocks += 1
print(blocks)检验最小生成树的大小,用邻接表存最短路径,因为不是所有的节点都处于该连通块上,所以结束条件变为遍历完所有的边:
class Node:
def __init__(self, node, length):
self.node = node
self.length = length
class Edge:
def __init__(self, x, y, length):
self.x = x
self.y = y
self.length = length
class Prim:
"""Prim算法"""
def __init__(self, n, m):
self.n = n # 输入的点个数
self.m = m # 输入的边个数
self.v = [[] for i in range(n+1)] # 存放所有节点之间的可达关系与距离
self.e = [] # 存放与当前已选节点相连的边
self.s = [] # 存放最小生成树里的所有边
self.vis = [False for i in range(n+1)] # 标记每个点是否被访问过,False未访问
def graphy(self):
for i in range(self.m):
x, y, length = list(map(int, input().split()))
self.v[x].append(Node(y, length))
self.v[y].append(Node(x, length))
def insert(self, point):
for i in range(len(self.v[point])):
if not self.vis[self.v[point][i].node]:
self.e.append(Edge(point, self.v[point][i].node, self.v[point][i].length))
self.vis[point] = True
self.e = sorted(self.e, key=lambda e: e.length)
def run(self, start):
self.insert(start) # start为选择的开始顶点,即为测试命令的起点
flag = 1;
while flag == 1: # 一直循环直到边被遍历完
for i in range(len(self.e)):
if not self.vis[self.e[i].y]:
self.s.append(self.e[i])
self.insert(self.e[i].y)
break
if i == len(self.e) - 1:
flag = 0
def print(self):
print(f'当前录入总边数为:{len(self.e)}\n其中构成最小生成树的边为:')
edge_sum = 0
for i in range(len(self.s)):
print(f'边<{self.s[i].x},{self.s[i].y}> = {self.s[i].length}')
edge_sum += self.s[i].length
print(f'最小生成树的权值为:{edge_sum}')至于第三次作业的最短路径,恕我直言这个单元就不应该自己写评测系统,思路和自己写的代码都是一模一样的,不如直接找人对拍。
JUnit方法可以自动生成测试框架,研讨课上一位同学说得好呀,这跟计组课里Verilog自动生成TestBench一样,只是个架子,具体数据还是要自己充分理解规格要求才可以写出来。熟悉了一下assert的使用,这个函数在OS实验代码上还是经常用的,简单方便。根据自己的要求对每个函数进行测试,这种白盒测试需要对代码和规格理解较深才行,规格越大,这种理论上的验证就越困难,但相比于黑盒测试来说,白盒无疑更能发现bug,因为是自己钻研的死角和临界条件。但从时间的角度上来讲,其效率还是比随机生成数据找人对拍更低,毕竟自己能想到的边界条件都肯定写在代码里了,如果再去一个个测试会是一个漫长的工作。
代码性能问题及修复情况
第一次作业没有性能问题。
第二次作业强测没有问题,但互测让我意识到了计算平均值和方差也是需要很多时间的,如果实时不保存平均数的话,求方差就是一个O(n^2)的算法。之前一直认为图才是最耗时的,没想到求方差更耗时。其实求平均数和方差的这两个方法我是完全按照JML规格来写的,直接复制粘贴,结果就出问题了,这规格语言当真误我。这次作业也让我意识到对代码的评估需要考虑到诸多细节,不能真的直接抄JML的代码,应该要分析JML规格具体想要这个方法达到什么目的,对症下药。
第三次作业的问题出在最短路径上,答案是没有问题的,但超时了。其实我一直百思不得其解,我也是用的堆优化呀,怎么就能超时呢?一个互测的hack数据是这样的,一共有编号从1到2000共2000个人,1999条边把编号1到2000的人串起来,求500次编号1到编号2000的最短路径。这只能挨个遍历呀,堆优化还不如不优化,或许是这数据太强了,也或许是某个步骤有问题。值得一提的是互测房里针对这个样例要么WA,要么TLE,整得我借鉴都没法借鉴,搞笑的是提出这个样例的人也有这个bug,要不是不能自刀,这直接就团灭对手和自己。
Network类扩展
要求
假设出现了几种不同的Person
-
Advertiser:持续向外发送产品广告
-
Producer:产品生产商,通过Advertiser来销售产品
-
Customer:消费者,会关注广告并选择和自己偏好匹配的产品来购买 -- 所谓购买,就是直接通过Advertiser给相应Producer发一个购买消息
-
Person:吃瓜群众,不发广告,不买东西,不卖东西
如此Network可以支持市场营销,并能查询某种商品的销售额和销售路径等 请讨论如何对Network扩展,给出相关接口方法,并选择3个核心业务功能的接口方法撰写JML规格(借鉴所总结的JML规格模式)
JML规格
Producer类
在Producer类中设置一个Product数组,用于存放生产者生产出来的产品。其中Product类中包含产品的价格,种类,id等信息,每生产出一个产品,Product数组内的products就增加一个元素。
/*@ public normal_behavior
@ requires contains(producerId) && (getPerson(producerId) instanceof Producer);
@ assignable getProducer(producerId).products;
@ ensures getProducer(producerId).getProductCount() ==
@ \old(getProducer(producerId).getProductCount()) + 1;
@ ensures \exists(int i; 0 < i && i < getProducer(producerId).getProductCount();
@ getProducer(producerId).products[i] == product);
@ ensures \forall(int i; 0 < i && i < \old(getProducer(producerId).getProductCount());
@ \exists(int j; 0 < i && i < getProducer(producerId).getProductCount();
@ getProducer(producerId).products[j] == \old(getProducer(producerId).products[i]));
@ also
@ public exceptional_behavior
@ signals (PersonIdNotFoundException e) !contains(producerId);
@
@*/
public void produce(int producerId, Product product) throws
PersonIdNotFoundException;Advertiser类
针对宣传者和生产者以及产品本身进行特定的宣传。该方法的作用是给定宣传者将给定生产者的给定产品包装成ProductMessage类的实例,用于发送至所有与给定宣传者相互联系的好友列表中。产品信息包含产品本身及生产者信息。
/*@ public normal_behavior
@ requires contains(advertiserId) && getPerson(advertiserId) instanceof Advertiser &&
@ contains(producerId) && getPerson(producerId) instanceof Producer &&
@ getPerson(producerId).hasProduct(product);
@ assignable people[*].messages;
@ ensures (\forall int i; 0 <= i && i <= people.length &&
@ people[i].isLinked(getPerson(advertiserId)) && people[i].getId() != advertiserId;
@ \old(people[i].messages.length) == people[i].messages.length - 1));
@ ensures (\forall int i; 0 <= i && i <= people.length &&
@ !people[i].isLinked(getPerson(advertiserId));
@ \old(people[i].messages.length) == people[i].messages.length));
@ ensures (\forall int i; 0 <= i && i <= people.length &&
@ people[i].isLinked(getPerson(advertiserId)) && people[i].getId() != advertiserId);
@ (\forall int j; 0 <= j && j <= \old(people[i].messages.length);
@ (\exists int k; 0 <= k && k <= people[i].messages.length;
@ \old(people[i].messages[j]) == people[i].messages[k])));
@ ensures (\forall int i; 0 <= i && i <= people.length &&
@ people[i].isLinked(getPerson(advertiserId)) && people[i].getId() != advertiserId;
@ (\exists int k; 0 <= j && j <= people[i].messages.length;
@ getPerson(advertiserId).messages[j] == getProductMessage(product)));
@ also
@ public exceptional_behavior
@ signals (PersonIdNotFoundException e) !contains(advertiserId) || !(getPerson(advertiserId) instanceof Advertiser) ||
@ !contains(producerId) || !(getPerson(producerId) instanceof Producer);
@ signals (ProductNotFoundException e) contains(advertiserId) && getPerson(advertiserId) instanceof Advertiser &&
@ contains(producerId) && getPerson(producerId) instanceof Producer &&
@ !getPerson(producerId).hasProduct(product);
@*/
public void advertise(int advertiserId, int producerId, Product product) throws PersonIdNotFoundException, ProductNotFoundException;Customer类
购买者通过接受到的产品消息直接进行购买。购买者将钱支付给生产者,生产者的库存相应减少对应的产品。
/*@ public normal_behavior
@ requires contains(customerId) && getPerson(customerId) instanceof Customer;
@ requires productMessage.getProducer().hasProduct(productMessage.getProduct());
@ assignable productMessage.getProducer().products;
@ assignable getPerson(customerId).money;
@ assignable productMessage.getProducer().money;
@ ensures getPerson(customerId).money = \old(getPerson(customerId).money) - productMessage.getProduct().getValue;
@ ensures productMessage.getProducer().money = \old(productMessage.getProducer().money) + productMessage.getProduct().getValue;
@ ensures productMessage.getProducer().getProductCount() ==
@ \old(getProducer(producerId).getProductCount()) - 1;
@ ensures \forall(int i; 0 < i && i < \old(productMessage.getProducer().getProductCount());
@ \old(productMessage.getProducer().products[i]) != productMessage.getProduct() ==>
@ \exists(int j; 0 < i && i < getProducer(producerId).getProductCount();
@ getProducer(producerId).products[j] == \old(getProducer(producerId).products[i]))));
@ ensures \forall(int i; 0 < i && i < productMessage.getProducer().getProductCount();
@ productMessage.getProducer().products[i] != productMessage.getProduct());
@ also
@ public exceptional_behavior
@ signals (PersonIdNotFoundException e) !contains(customerId) || !(getPerson(customerId) instanceof Customer)
@ signals (ProductNotFoundException e) !productMessage.getProducer().hasProduct(productMessage.getProduct())
@
@*/
public void purchase(int customerId, ProductMessage productMessage) throws PersonIdNotFoundException, ProductNotFoundException;学习体会
本单元的难度相较于前两个单元较为简单,而且答案唯一,自己思考的空间变少了。难点全是关于图的部分,在学习的过程中也逐渐拾起了忘记的东西,相比于第二单元百家争鸣的电梯策略组合,这个单元按部就班就可以了。
JML的规范与使用是我觉得最需要学到的东西,如何实现取决于大家各自的想法,但这种形式化语言却几乎就没有改变的空间,每个方法所想要达到的目的是没有二义性的,前置条件和后置条件的严格规范把方法限制得死死的。这样一来,自己在实现方法时思路会很清晰,编写测试样例时也能充分考虑到各种情况,只是就现如今的编程学习而言嘛,嘿嘿,还不如就用中文注释,尽管没那么规范,但却简明扼要。
继承关系中,子类方法的前置条件一定要满足父类的同名方法,而子类方法的后置条件却不一定要满足父类的同名方法,这为我们层次化设计带来了一个新的规范。在编写JML中,若传入的参数和最终想要得到的返回值没有直接的关系,则通常利用中间量进行表示,比如最短路径的规格描述中,需要有路径这个中间量,当所有路径都比某路径短时,那么就得到了最短路径,根据这个中间量才能表示出该最短路径的长度。
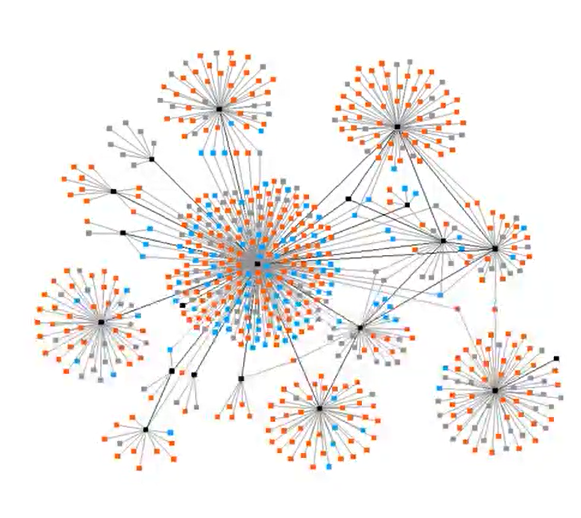
在实现这个社交网络过程中,我们不难看出正常的社交网络基本特征如下图所示,按照节点的连接关系特征将节点分在不同的聚合中,可以看到,聚合内连接紧密,聚合间连接稀疏。于是与查询和度量分析有关的操作可以不用遍历整个大图,社交网络的这种特性或许能在我们实现社交网络时带来一些额外的思考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号