【综述】自我演进的智能代理综述:连接基础模型与终身智能系统的新范式
https://arxiv.org/abs/2508.07407
摘要
近年来,大语言模型(LLMs)的快速发展激发了人们对能够解决复杂现实任务的 AI 智能体的广泛兴趣。然而,现有大多数智能体系统依赖于人工设计的静态配置,部署后难以适应动态变化的环境。为了解决这一局限,最新研究提出了智能体“进化”技术,旨在基于交互数据和环境反馈自动优化智能体系统。这一新兴方向为“自进化 AI 智能体”奠定了基础,使其能够将基础模型的静态能力与“终身智能体系统”所需的持续适应性相结合。本文系统性地回顾了自进化智能体系统的现有技术。我们首先提出了一个统一的概念框架,抽象总结了自进化智能体系统设计中的反馈循环。该框架强调了四个关键组成部分:系统输入、智能体系统、环境和优化器,为理解和比较不同策略提供了基础。基于该框架,我们系统性地梳理了针对智能体系统不同组件的自进化技术,包括基础模型、智能体提示词、记忆、工具、工作流以及智能体间的通信机制。我们还探讨了在生物医学、编程、金融等专业领域中发展出的领域特定进化策略,这些领域的智能体行为和优化目标与领域约束紧密相关。此外,本文还专门讨论了自进化智能体系统的评估、安全与伦理问题,这对于确保系统的有效性和可靠性至关重要。本综述旨在为研究者和实践者提供自进化 AI 智能体的系统性理解,为开发更具适应性、自主性和终身学习能力的智能体系统奠定基础。
引言
近年来,大语言模型(LLMs)的进展极大推动了人工智能(AI)的发展。得益于大规模预训练、有监督微调和强化学习,LLMs 在规划、推理和自然语言理解方面展现出卓越能力。这些进步激发了人们对“基于 LLM 的智能体”(即以 LLM 作为决策/策略模块的 AI 智能体)的广泛兴趣。基于 LLM 的智能体是指:以 LLM 为核心推理组件,能够在开放、真实世界环境中理解输入、规划行动并生成输出的自主系统。一个典型的 AI 智能体通常包含多个组件,以支持其自主完成复杂、目标导向任务。基础模型(如 LLM)是核心,负责理解目标、制定计划和执行动作。为增强这些能力,智能体还集成了感知、规划、记忆和工具等模块,帮助其感知输入、分解任务、保留上下文信息并与工具交互。
虽然单智能体系统在多种任务中展现出强泛化和适应能力,但在动态复杂环境下,往往难以实现任务专精和高效协作。为此,研究者提出了多智能体系统(MAS),即多个智能体协作解决复杂问题。与单智能体系统相比,MAS 支持功能专精,每个智能体可针对特定子任务或领域设计。同时,智能体之间能够交互、信息交换并协调行为以实现共同目标。这种协作使系统能够应对单智能体无法完成的任务,并模拟更真实、动态和互动的环境。基于 LLM 的智能体系统已广泛应用于代码生成、科学研究、网页导航,以及生物医学、金融等领域的专业任务。
尽管智能体系统取得了显著进展,无论是单智能体还是多智能体,大多数系统仍高度依赖人工设计的配置。部署后,这些系统通常保持静态架构和固定功能。然而,真实世界环境是动态且持续变化的,例如用户意图变化、任务需求调整、外部工具或信息源不断更新。例如,客服智能体需应对新产品、最新政策或陌生用户需求;科学研究助手可能需要集成新发表的算法或分析工具。在这些场景下,人工重构智能体系统既耗时又费力,难以规模化。
这些挑战促使研究者探索新的范式——“自进化 AI 智能体”,即能够自主适应和持续自我优化的新型智能体系统,连接基础模型与终身学习智能体系统。自进化 AI 智能体是指能够通过与环境交互,持续且系统性地优化其内部组件的自主系统,旨在在保持安全性和提升性能的前提下,适应不断变化的任务、环境和资源。受艾萨克·阿西莫夫(Isaac Asimov)提出的“机器人三定律”的启发,我们提出了一套用于安全高效自进化的指导原则:
- 坚守(安全适应)
自进化 AI 智能体在任何修改过程中必须保持安全与稳定; - 卓越(性能保持)
在遵循第一定律的前提下,自进化 AI 智能体必须保持或提升现有任务性能; - 进化(自主优化)
在遵循第一和第二定律的前提下,自进化 AI 智能体必须能够根据任务、环境或资源的变化自主优化其内部组件。
我们将自进化 AI 智能体的出现视为 LLM 系统发展范式转变的一部分。该转变涵盖了早期的模型离线预训练(MOP)、模型在线适应(MOA),到近期的多智能体编排(MAO),最终迈向多智能体自进化(MASE)。如图1 和表1 所示,每一阶段都在前一阶段基础上演进,从静态、冻结的基础模型逐步发展为完全自主、自进化的智能体系统。
- MOP(Model Offline Pretraining):初始阶段侧重于在大规模静态语料上预训练基础模型,并以固定、冻结的状态进行部署,后续不再适应或更新。
- MOA(Model Online Adaptation):在 MOP 基础上,加入部署后的模型适应能力,通过有监督微调、低秩适配器或人类反馈强化学习(RLHF)等技术,利用标签、评分或指令提示对基础模型进行更新。
- MAO(Multi-Agent Orchestration):突破单一基础模型限制,通过多智能体协作,多个 LLM 智能体通过消息传递或辩论提示进行沟通与协作,解决复杂任务,无需修改底层模型参数。
- MASE(Multi-Agent Self-Evolving):最终阶段引入终身自进化循环,智能体群体能够根据环境反馈和元奖励,持续优化自身的提示词、记忆、工具使用策略,甚至交互模式。

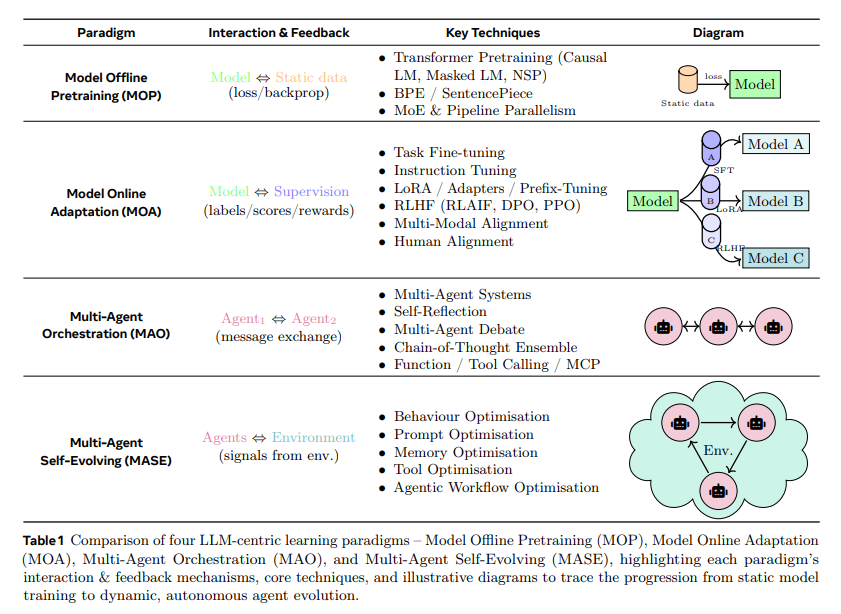
从 MOP 到 MASE 的演进,标志着 LLM 系统开发范式的根本转变:从静态、人工配置的架构,迈向能够根据需求和环境变化自适应、数据驱动的进化系统。自进化 AI 智能体将基础模型的静态能力与“终身智能体系统”所需的持续适应性相结合,为更具自主性、韧性和可持续性的 AI 奠定了基础。
尽管自进化 AI 智能体代表了未来 AI 系统的宏伟愿景,实现这一水平的自主性仍是长期目标。目前系统距离安全、鲁棒、开放式自进化的完整能力尚有差距。实际上,通往这一愿景的路径依赖于更为具体的技术,即智能体进化与优化。当前的研究进展主要通过智能体进化与优化技术实现,让智能体系统能够基于交互数据和环境反馈,迭代优化自身组件,从而提升在真实任务中的有效性。相关研究主要有几个方向:一是提升底层 LLM 的核心能力,如规划、推理和工具使用;二是针对智能体系统的辅助组件(如提示词、工具、记忆等)进行优化,使智能体更好地泛化到新任务和动态环境;三是在多智能体系统中,优化智能体拓扑结构和通信协议,寻找最适合当前任务的智能体结构,提升协作与信息共享能力。
现有关于 AI 智能体的综述主要聚焦于智能体架构与功能的通用介绍,或针对规划、记忆、协作机制与评估等具体组件展开讨论。另一些综述则关注智能体在特定领域的应用,如操作系统智能体和医疗健康智能体。尽管这些综述为理解智能体系统的各个方面提供了有价值的参考,但对于智能体自进化与持续适应的最新进展尚未充分覆盖,而这正是实现终身自主 AI 系统的核心能力。因此,当前文献在帮助研究者和实践者系统性理解支撑自适应与自进化智能体系统的新型学习范式方面,仍存在关键空白。
为填补这一空白,本文聚焦并系统性回顾了支持智能体基于交互数据和环境反馈自我进化与优化的技术。具体而言,我们提出了一个统一概念框架,抽象总结了自进化智能体系统设计中的反馈循环。该框架明确了四个核心组成部分:系统输入、智能体系统、环境和优化器,突出智能体系统的进化闭环。在此基础上,我们系统性梳理了针对智能体系统不同组件的进化与优化技术,包括底层 LLM、提示词、记忆、工具、工作流拓扑以及通信机制。此外,我们还探讨了在专业领域中发展出的领域特定进化策略。本文还专门讨论了自进化智能体系统的评估、安全与伦理问题,这对于确保系统的有效性和可靠性至关重要。
作为同期工作,有综述围绕“进化什么”、“何时进化”、“如何进化”三大维度组织了自进化智能体的研究。虽然其分类法提供了有益视角,本文则致力于提出更为全面和整合性的观点,即统一概念框架,系统阐述构建终身自进化智能体系统的机制与挑战。
本文旨在为自进化智能体系统的现有技术提供全面、系统性的回顾,为研究者和实践者开发更高效、可持续的智能体系统提供参考与指导。图 2 展示了现有智能体进化策略在单智能体、多智能体及领域特定优化方向上的视觉化分类,并突出各方向的代表性方法。
主要贡献如下:
- 形式化了“三定律”,并将以 LLM 为中心的学习范式从静态预训练到完全自主、终身自进化智能体系统的演变进行了映射。
- 引入了统一的概念框架,抽象总结了自进化智能体系统背后的反馈循环,为系统性理解和比较不同的进化与优化方法提供了基础。
- 对单智能体、多智能体和领域特定场景中的现有进化与优化技术进行了系统性回顾。
- 全面回顾了自进化智能体系统的评估、安全性和伦理问题,强调了它们在确保这些系统的有效性、安全性和负责任部署中的关键作用。
- 识别了关键的开放性挑战,并概述了智能体自进化领域中一些有前景的研究方向,旨在促进未来的探索并推动更具适应性、自主性和自进化的智能体系统的发展。
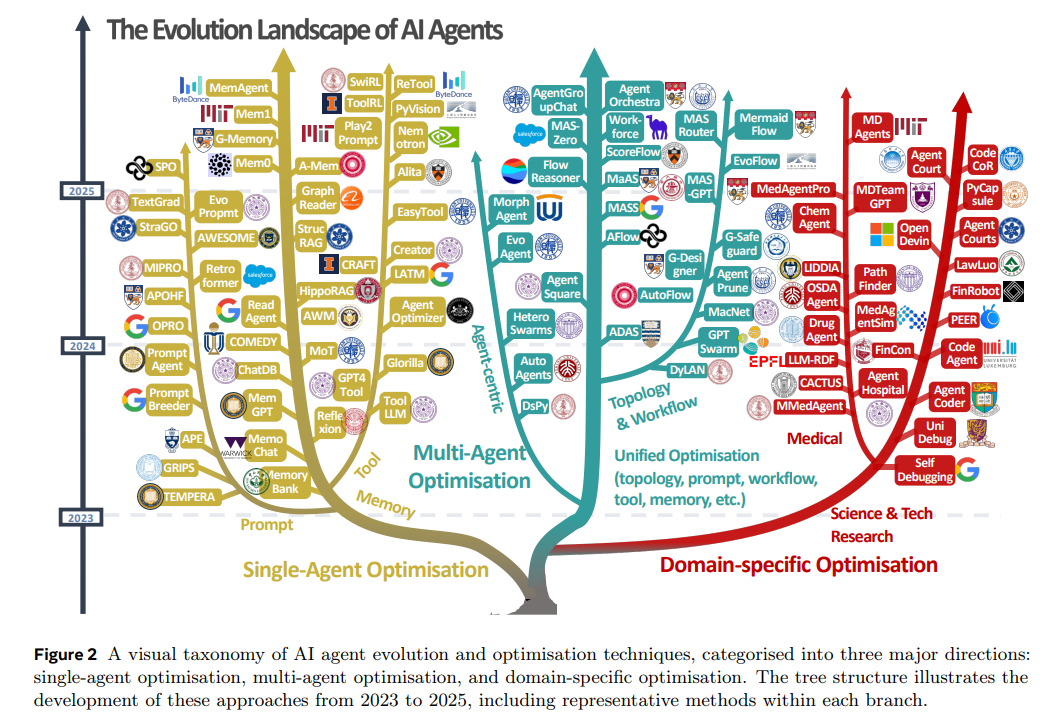
AI智能体系统基础
为帮助读者清晰理解智能体进化与优化,本节将对现有AI智能体系统进行概述。
AI智能体
AI智能体是指能够自主感知输入、推理目标并与环境交互以完成任务的系统。本节聚焦于单智能体系统,它们是AI智能体研究的基础。由于本节仅作简要介绍,读者可参考现有综述以获得更全面的智能体架构与能力讨论。
一个AI智能体通常由多个组件协同工作,实现自主决策与执行。智能体的核心组件是基础模型,最常见的是大语言模型(LLM),其作为中心推理引擎,负责解释指令、生成计划并输出可执行响应。此外,智能体还包含一些辅助模块,以增强其在复杂动态环境中的能力:
-
感知模块(Perception Module)
负责从环境中获取和解释信息,包括处理文本输入、音频信号、视频帧或其他感知数据,以构建适合推理的表示。 -
规划模块(Planning Module)
使智能体能够将复杂任务分解为可执行的子任务或操作序列,并指导其跨多个步骤的执行。支持分层推理,确保任务连贯完成。常见方法包括线性任务分解(如链式思维 Chain-of-Thought)、动态规划与执行(如 ReAct 框架),以及分支式策略(如 Tree-of-Thought、Graph-of-Thought),支持智能体探索多条推理路径。 -
记忆模块(Memory Module)
使智能体能够保留和回忆过去的经验,实现上下文感知推理和长期一致性。记忆分为短期记忆(任务执行过程中的上下文信息)和长期记忆(跨任务保存的知识和经验)。许多系统采用检索增强生成(RAG)模块,从记忆库中检索相关信息并整合到 LLM 输入上下文中。记忆模块设计需考虑结构化表示、信息存储与检索、以及与推理过程的集成。 -
工具使用(Tool Use)
能够调用外部工具是智能体高效运行的关键。通过工具扩展,智能体可突破静态知识和推理能力的限制,与真实世界环境交互。常见工具包括搜索引擎、代码解释器、浏览器自动化等。工具使用涉及工具选择、输入构建、API 调用及结果整合回推理流程。
多智能体系统
虽然单智能体系统在多种任务中展现出强大能力,但许多现实任务需要超越单一智能体能力的专精与协作。这一局限推动了多智能体系统(MAS)的发展,MAS 模仿了生物和社会系统中的分布式智能。
MAS 正式定义为一组自主智能体在共享环境中相互作用,以实现单一智能体无法完成的目标。与仅依赖个体推理和能力的单智能体系统不同,MAS 通过结构化的协调与协作实现集体智能。实现这种协调的核心机制是智能体拓扑,即定义智能体在系统中如何连接和通信的结构配置。拓扑决定了信息流动和协作策略,直接影响任务的分配与执行。因此,MAS 通常以多智能体工作流的形式实现,系统拓扑编排智能体间的交互,以完成复杂的共同目标。关键洞察在于:当多个智能体通过此类工作流协作时,系统整体性能能够超越所有智能体单独能力之和。
MAS 相较于单智能体系统具有诸多显著优势。首先,MAS 能够将复杂任务分解为可管理的子任务,并分配给专门的智能体,从而提升整体性能。这种方法类似于人类组织协作,使 MAS 能够处理单一智能体无法胜任的任务。其次,MAS 支持并行执行,允许多个智能体同时工作以完成任务,这对于对时效性要求高的应用尤为有利,可大幅加快问题解决速度。第三,MAS 的去中心化特性增强了系统的鲁棒性:当某个智能体失效时,其他智能体可以动态重新分配任务并进行补偿,确保系统优雅降级而非完全崩溃。第四,MAS 具备天然的可扩展性,新智能体可无缝集成,无需重新设计整个系统。最后,协作机制如辩论和迭代优化,使 MAS 能够通过多元视角和批判性评估,生成更具创新性和可靠性的解决方案。CAMEL 和 AutoGen 等框架进一步通过模块化架构、角色扮演模式和自动编排能力,简化了 MAS 的开发流程,降低了工程复杂度。
系统架构
MAS 的架构设计决定了智能体如何组织、协调和执行任务。常见结构包括层级结构、中心化结构和去中心化结构,体现了对控制权、自主性和协作的不同理念:
-
层级结构
采用静态层级组织,通常为线性或树状结构,任务被明确分解并顺序分配给特定智能体。例如,MetaGPT 引入标准操作流程(SOP)以简化软件开发,HALO 结合蒙特卡洛树搜索提升推理性能。该方法具有模块化、易开发和领域优化等优势,广泛应用于软件开发、医学、科学研究和社会科学等领域。 -
中心化结构
遵循管理者-执行者范式,由中心智能体或高层协调者负责规划、任务分解和分配,下属智能体则执行具体子任务。该设计有效平衡了全局规划与具体执行,但中心节点易成为性能瓶颈,并带来单点故障风险,影响系统鲁棒性。 -
去中心化结构
智能体作为分布式网络中的平等节点协作,广泛应用于世界模拟场景。由于没有中心控制,任一节点损坏不会导致系统瘫痪,从而消除瓶颈并增强鲁棒性。但也带来了信息同步、数据安全和协作成本增加等挑战。最新研究探索区块链技术以解决这些协调难题。
通信机制
多智能体系统(MAS)的有效性在很大程度上取决于智能体之间的信息交换与协作方式。MAS 的通信方法已从简单的消息传递发展为兼顾表达性、效率与互操作性的复杂协议,主要包括:
-
结构化输出
采用如 JSON、XML 和可执行代码等格式进行智能体间通信。显式结构和明确参数保证了高度的机器可读性与可解释性,标准化格式促进了跨平台协作。结构化通信非常适用于对精确性和效率要求较高的应用场景,如问题求解和推理任务,紧凑的信息表达进一步提升了计算效率。 -
自然语言
自然语言通信保留了丰富的上下文和语义细节,尤其适用于创意任务、世界模拟和写作等场景。其表达力支持捕捉细微的含义和意图,但也带来了歧义、误解和执行效率降低等挑战。 -
标准化协议
最新进展提出了专门用于标准化 MAS 通信的协议,推动更具包容性和互操作性的智能体生态系统。例如,A2A 通过结构化的点对点任务委托模型标准化横向通信,使智能体能够协作完成复杂、长周期任务,同时保持执行过程的透明性。ANP 通过分层架构和内置去中心化身份(DID)及动态协议协商,实现安全、开放的横向通信,支持去中心化“智能体互联网”。MCP 标准化了智能体与外部工具或数据资源的纵向通信,采用统一的客户端-服务器接口。Agora 作为横向通信的元协议,使智能体能够动态协商并进化通信方式,在灵活的自然语言与高效的结构化流程间无缝切换。
终身自进化智能体系统的愿景
从模型离线预训练(MOP)、模型在线适应(MOA)到多智能体编排(MAO),这一演进轨迹持续减少了 LLM 系统中的人工配置。然而,即使是当前最先进的多智能体框架,仍然依赖于手工设计的工作流、固定的通信协议和人工构建的工具链。这些静态元素限制了系统的适应性,使智能体难以在动态、开放式环境中持续保持高性能——而这些环境的需求、资源和目标会不断变化。
多智能体自进化(MASE)系统的新兴范式正是为了解决这些局限。MASE 系统通过闭环反馈,将部署与持续优化紧密结合。系统中的智能体群体能够自主优化自身的提示词、记忆、工具使用策略,甚至交互拓扑结构——这一过程由环境反馈和更高层次的元奖励信号驱动。智能体不再只是一次性适应,而是能够在生命周期内持续进化,主动应对任务、领域和操作约束的变化。
终身自进化智能体系统通过将持续改进循环嵌入架构核心,突破了传统系统的适应性瓶颈。在 自我演进智能体三大定律(坚守:安全适应,卓越:性能保持,进化:自主优化)指导下,这类系统具备以下能力:
- 在运行过程中主动监控自身性能与安全状态;
- 通过受控、渐进式更新,保持或提升系统能力;
- 能够根据任务、环境和资源变化,自动优化提示词、记忆结构、工具使用策略,甚至智能体间的拓扑结构。
与其要求人类设计者手工构建每一个交互模式,终身自进化系统能够自动生成、评估并优化自身的智能体配置,实现环境反馈、元层推理与结构自适应的闭环。这一机制将智能体从静态执行者转变为持续学习、协同进化的生态参与者。
这一愿景具有深远影响。在科学发现领域,自进化智能体生态系统能够自主生成假设、设计实验并迭代研究流程。在软件工程中,它们可以协同进化开发管道,动态集成新工具。在人机协作场景下,系统能够学习个体偏好,持续个性化交互风格。进一步扩展至物理世界,这类系统可通过机器人、物联网设备和网络–物理基础设施与环境交互,感知变化、采取行动,并将现实反馈纳入进化循环。将智能体视为可重构、具备自进化、协同与长期适应能力的计算实体,MASE 为可扩展、可持续、可信赖的 AI 提供了新路径——AI 不再只是一次性训练,而是能够“生长”、“学习”并“持久”存在。
MASE 概念框架
为全面梳理自进化智能体系统,我们提出了一个高层次的概念框架,抽象总结了智能体进化与优化方法的关键要素。该框架以抽象且可泛化的视角覆盖了现有主流优化方法,有助于系统性理解该领域并促进不同方法的比较分析。
自进化过程概述
我们首先介绍智能体系统的自进化过程,其本质通常通过迭代优化实现。在这一过程中,智能体系统会根据性能评估和环境交互获得的反馈信号不断更新。 如图3 所示,流程起始于任务规范,包括高层描述、输入数据、上下文信息或具体示例。
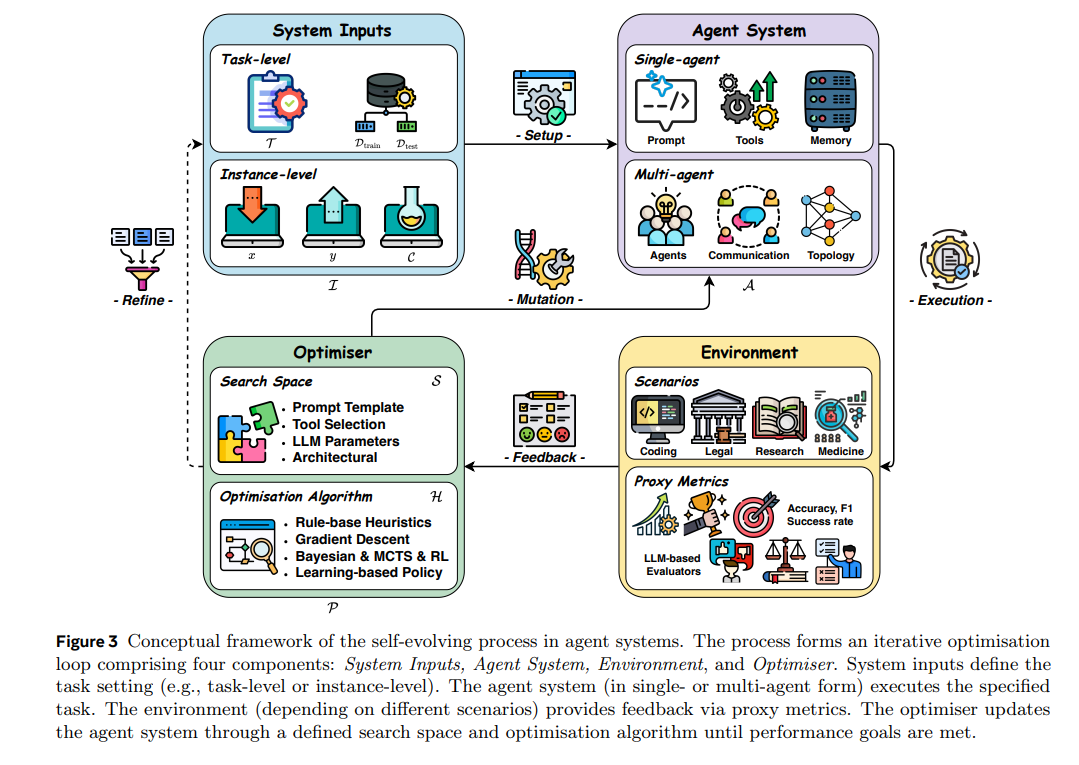
这些元素构成了系统输入,定义了智能体系统的问题设定。随后,智能体系统(可为单智能体或多智能体架构)被部署到环境中执行任务。环境为系统提供运行上下文,并根据预设评估指标生成反馈信号,用于衡量系统效果并指导后续优化。基于环境反馈,优化器采用特定算法和策略对智能体系统进行更新,如调整 LLM 参数、修改提示词或优化系统结构。在部分场景下,优化器还会优化系统输入,例如通过合成训练样本扩充数据集,从而为后续优化循环提供更多数据。更新后的智能体系统再次部署到环境中,开启新一轮迭代。该过程形成了一个迭代闭环反馈机制,智能体系统在多轮迭代中持续优化和提升。循环在达到预设性能阈值或收敛标准后终止。基于这一 MASE 概念框架,EvoAgentX 是首个开源实现该自进化智能体流程的框架,支持智能体系统的自动生成、执行、评估与优化。
在上述综述的基础上,智能体优化过程可分为四个关键组成部分:系统输入、智能体系统、环境和优化器。下文将分别介绍每个组件,突出其在优化框架中的角色、特性及相互作用。
系统输入
系统输入指的是提供给优化过程的上下文信息和数据。形式上,我们将系统输入集合记为 \(\mathcal{I}\),其可包含一个或多个元素,用于指定任务需求、约束条件和可用数据。这些输入定义了智能体系统的问题设定,并决定了优化的范围。
根据不同场景,\(\mathcal{I}\) 可以有不同的形式:
-
任务级优化
现有研究最常见的设定是提升智能体系统在特定任务上的整体性能。在此情境下,系统输入 \(\mathcal{I}\) 可能包括任务描述 \(\mathcal{T}\) 和用于训练或验证的数据集 \(\mathcal{D}_{\text{train}}\),即 \(\mathcal{I} = \{\mathcal{T}, \mathcal{D}_{\text{train}}\}\)。此外,还可引入独立的测试集 \(\mathcal{D}_{\text{test}}\) 用于评估优化后的智能体性能。在某些场景下,任务特定的标注数据(即 \(\mathcal{D}_{\text{train}}\))可能不可用。为支持此类优化,近期方法提出通过 LLM 生成合成训练样本,动态构建代理数据集以实现迭代提升。 -
实例级优化
最新研究还探索了更细粒度的设定,即提升智能体系统在某个具体样例上的表现。在此情境下,系统输入可由输入输出对 \((x, y)\) 及可选的上下文信息 \(\mathcal{C}\) 组成,即 \(\mathcal{I} = \{x, y, \mathcal{C}\}\)。
智能体系统
智能体系统是反馈循环中的核心组件,也是优化的对象。它定义了智能体在给定输入下的决策过程和功能。形式上,我们用 \(\mathcal{A}\) 表示智能体系统,可以是单一智能体,也可以是多个协作智能体的集合。智能体系统 \(\mathcal{A}\) 可进一步分解为多个组件,如底层大语言模型(LLM)、提示策略、记忆模块、工具使用策略等。优化方法可针对其中一个或多个组件展开,具体取决于目标范围。在现有多数工作中,优化通常聚焦于 \(\mathcal{A}\) 的单一组件,例如通过微调 LLM 提升推理与规划能力,或调整提示词与工具选择以提升任务性能而无需修改 LLM 本身。此外,近期研究也探索了多组件联合优化。例如,在单智能体系统中,有方法联合优化 LLM 与提示策略,以更好地对齐模型行为与任务需求;在多智能体系统中,已有研究联合优化提示词与智能体间拓扑结构,以提升整体协作效果。
环境
环境是智能体系统运行并产生输出的外部上下文。具体而言,智能体系统通过感知环境输入、执行动作并获得相应结果与环境交互。根据任务不同,环境可以是基准数据集,也可以是完全动态的真实世界场景。例如,在代码生成任务中,环境可能包括代码执行与验证组件,如编译器、解释器和测试用例;在科学研究中,环境可能由文献数据库、仿真平台或实验设备构成。
除了提供运行上下文外,环境还在生成 反馈信号、指导优化过程中发挥关键作用。这些信号通常由 评估指标 得出,用于量化智能体系统的有效性或效率。多数情况下,评估指标是任务相关的,如准确率、F1值或成功率等,能为性能提供定量衡量。但在缺乏标注数据或真实标签的场景下,常采用基于LLM的评估器来估算性能。这类评估器可生成代理指标,或通过评估正确性、相关性、连贯性及与任务指令的对齐度等方面,提供文本反馈。
优化器
优化器(\(\mathcal{P}\))是自进化反馈循环的核心组件,负责根据环境的性能反馈优化智能体系统 \(\mathcal{A}\)。其目标是通过专门的算法和策略,在给定的评估指标下搜索出最佳的智能体配置。形式化地表示为:
其中,\(\mathcal{S}\) 表示可探索和优化的配置空间,\(\mathcal{O}(\mathcal{A}; \mathcal{I}) \in \mathbb{R}\) 是评估函数,将智能体 \(\mathcal{A}\) 在系统输入 \(\mathcal{I}\) 上的表现映射为一个标量分数,\(\mathcal{A}^*\) 表示最优的智能体配置。
一个优化器通常由两个核心部分组成:
- 搜索空间(\(\mathcal{S}\)):定义可探索和优化的智能体配置集合。\(\mathcal{S}\) 的粒度取决于智能体系统中被优化的部分,范围从智能体提示词、工具选择策略,到连续的 LLM 参数或架构结构。
- 优化算法(\(\mathcal{H}\)):指定用于探索 \(\mathcal{S}\) 并选择或生成候选配置的策略。可包括基于规则的启发式方法、梯度下降、贝叶斯优化、蒙特卡洛树搜索(MCTS)、强化学习、进化策略或基于学习的策略。\((\mathcal{S}, \mathcal{H})\) 共同决定了优化器的行为,以及其将智能体系统高效适应到更优性能的能力。
在后续章节中,将分别介绍三种不同场景下的典型优化器:单智能体系统、多智能体系统以及领域特定智能体系统。每种场景具有不同的特性和挑战,导致优化器的设计和实现各异。单智能体优化主要关注通过调整 LLM 参数、提示词、记忆机制或工具使用策略提升个体智能体性能;多智能体优化则扩展到优化个体智能体、结构设计、通信协议和协作能力;领域特定智能体优化则需考虑特定领域的特殊需求和约束,导致优化器设计更加定制化。各类优化设置及代表性方法的分层分类见图5。
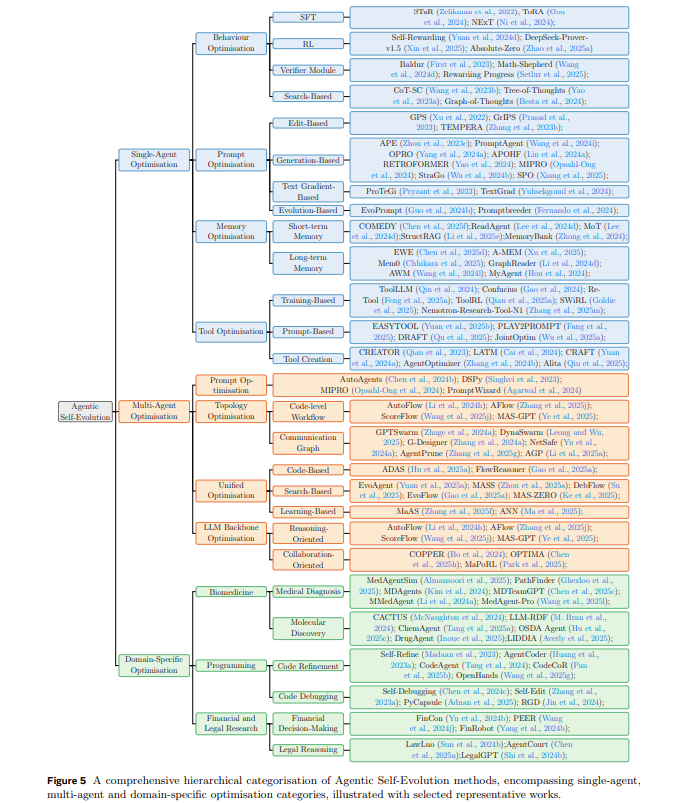
单智能体优化
单智能体优化聚焦于提升单一智能体系统的性能。根据前文介绍的优化反馈循环,核心挑战在于优化器的设计,即确定需要优化的智能体系统组件(搜索空间)、明确需提升的具体能力,并选择合适的优化策略(优化算法)以高效实现这些改进。
本节按照智能体系统中被优化的组件对单智能体优化方法进行分类,因为这决定了搜索空间的结构和优化方法的选择。具体包括四大类:
(1) LLM行为优化,通过参数微调或推理时扩展技术提升LLM的推理与规划能力;
(2) 提示词优化,通过调整提示词引导LLM生成更准确、与任务相关的输出;
(3) 记忆优化,增强智能体存储、检索和利用历史信息或外部知识的能力;
(4) 工具优化,提升智能体高效利用现有工具,或自主创建/配置新工具以完成复杂任务的能力。
如图4所示,展示了单智能体优化方法的主要类别。
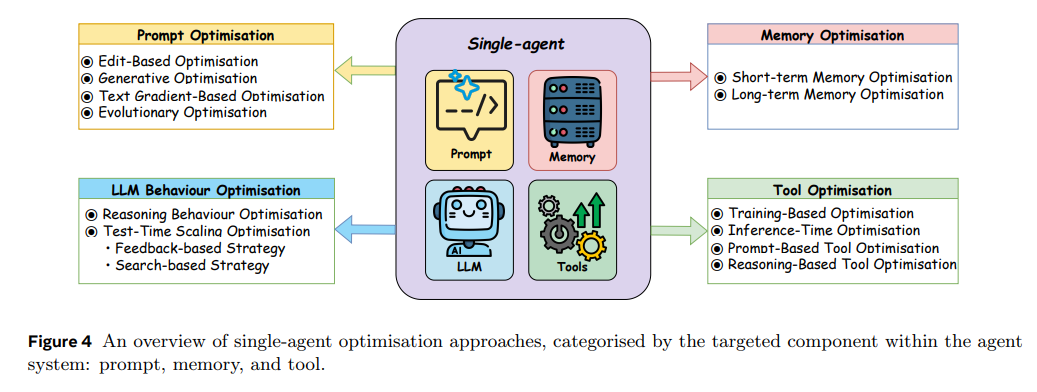
LLM行为优化
基础LLM是单智能体系统的核心,负责规划、推理和任务执行。因此,提升LLM的规划与推理能力是提高智能体系统整体效能的关键。近期相关研究主要分为两类:(1)训练型方法,通过直接更新模型参数以提升推理能力和任务表现;(2)推理时方法,在不修改模型参数的前提下优化LLM在推理阶段的行为。下文将分别综述两类代表性方法。
训练型行为优化
尽管LLM在自然语言处理方面表现优异,最新研究发现其在复杂推理任务中的能力仍存在显著差距。这一不足限制了基于LLM的智能体在多步推理和复杂决策任务中的有效性。为此,近期工作探索了以推理为导向的训练方法,主要包括有监督微调(SFT)和强化学习(RL),以帮助模型系统性地评估和优化自身输出。
有监督微调
有监督微调的核心思想是利用包含详细推理步骤的标注数据对智能体进行训练,使模型能够学习从输入问题、经过中间推理过程,到最终答案的完整映射。该方法通常依赖于精心构建的推理轨迹,这些轨迹可以来源于(1)智能体自身在执行过程中的rollout,以及(2)更强教师智能体生成的示范。通过模仿这些轨迹,智能体能够获得结构化的逐步推理能力。
STaR提出了迭代微调流程,模型在已正确解决的实例上训练,并对错误轨迹进行修正以生成更优轨迹。基于此思想,NExT利用自生成轨迹并通过单元测试正确性筛选,实现程序修复任务中的智能体自进化。类似地,Deepseek-Prover通过迭代训练策略模型与已验证的证明,不断进化智能体,使其能够生成越来越准确的定理证明。另一类工作则在由专有LLM生成的轨迹上进行微调,涵盖数学、科学等领域。除此之外,部分研究基于OpenAI o1生成的推理轨迹训练模型,旨在进一步提升智能体骨干的推理能力。
强化学习
强化学习(RL)将推理视为一个序列决策过程,模型通过生成正确或高质量的推理路径获得奖励。
其中一种策略是基于偏好的优化,例如 DPO 通过使用来自多种来源的偏好对进行优化,这些来源包括测试用例表现、最终结果的正确性或由训练好的过程奖励模型(PRMs)生成的伪标签。相关工作进一步提出了自进化框架,策略模型利用自身判断能力迭代提升推理能力。
类似地,Agent Q 结合了 MCTS 引导的搜索与自我批评机制,通过 DPO 在网页环境中利用成功与失败轨迹迭代提升智能体决策能力。
另一方向,Tülu 3 在数学与指令跟随任务中应用强化学习,奖励可验证,无需训练奖励模型。值得注意的是,DeepSeek-R1 进一步展示了在可验证真值的情况下,使用群体相对策略优化(Group Relative Policy Optimisation)实现纯 RL 的可行性。
在此基础上,相关工作将该思路扩展到 DeepSeek-Prover,通过引入来自证明助手的反馈进行强化学习优化。
除了在固定数据集上使用可验证奖励外,Absolute Zero 训练了一个模型,交替扮演任务提出者与求解者角色,通过自我生成与解决问题实现自进化。
类似地,R-Zero 采用双模式框架,挑战者根据求解者当前能力生成任务,使双方能够在无外部监督的情况下迭代进化。
测试时行为优化
随着训练资源日益受限,且API模型无法进行微调,测试时计算成为解决这些限制的方案,使模型能够在推理阶段“无需额外训练”地优化或扩展其推理能力。通过增加推理预算,模型可以“思考得更久”。
测试时能力的扩展主要有两种策略。第一种是“通过引入外部反馈引导推理”,帮助模型优化其输出。第二种是“采用更高效的采样算法生成多个候选输出”,再通过验证器筛选最优结果。值得注意的是,这两种方法本质上密切相关:前者用于生成的反馈也可作为后者的验证器。
反馈驱动策略
一种自然的方法是根据模型生成结果的质量调整其行为。该过程通常依赖于“验证器”提供的精确或估算分数来指导模型。反馈分为两类:结果级反馈仅根据最终输出给出单一分数,无论推理过程有多少步。对于易获取真实标签的任务,验证器可由外部工具实现,提供准确反馈。例如,CodeT 和 LEVER 利用编译器执行生成代码,并通过测试用例验证正确性。Baldur 则利用证明助手的错误信息进一步修复LLM生成的错误证明。然而,大多数任务在推理时无法获得真实标签,因此更通用的方法是训练一个模型作为验证器,对每个候选响应打分并排序。但这种反馈较为稀疏,仅评估最终输出。相比之下,过程级反馈在生成过程中对每一步进行评估,提供更细粒度的监督。仅依赖结果反馈容易导致“非真实推理”问题,即错误推理链也可能得到正确答案。为此,近期工作越来越关注训练过程奖励模型,在推理过程中检测和纠正错误,通常比仅用结果级反馈效果更好。
搜索驱动策略
复杂推理任务往往存在多条有效路径通向正确解。搜索类方法利用这一特性,允许模型并行探索多个推理轨迹,更好地覆盖解空间。在批评模型的辅助下,发展出多种搜索策略引导解码过程。例如,CoT-SC 采用 best-of-N 策略:生成多条推理路径,最终答案由多数投票决定。DBS 结合 beam search 与过程级反馈优化中间推理步骤;CoRe 和 Tree-of-Thoughts 将推理过程显式建模为树结构,利用蒙特卡洛树搜索(MCST)在探索与利用间取得平衡。Forest-of-Thought 进一步推广该思路,允许多棵树独立决策,并通过稀疏激活机制筛选最相关树的输出。除树结构外,其他方法也探索了推理的结构化表达。例如,Graph-of-Thoughts 将中间思路作为图节点,通过图操作实现灵活推理与信息流动;Buffer-of-Thoughts 引入动态记忆缓冲区,在推理过程中存储和实例化元级思路。
提示词优化
在单智能体系统中,提示词在定义智能体目标、行为和任务策略方面起着关键作用。提示词通常包含指令、示例和上下文信息,引导底层大语言模型(LLM)生成合适的输出。然而,众所周知,LLM 对提示词极为敏感:即使是措辞、格式或词序的微小变化,也可能导致模型行为和输出发生显著变化。这种敏感性使得设计鲁棒且可泛化的 AI 智能体系统变得困难,促使研究者开发自动搜索高质量提示词的优化技术。提示词优化方法可根据探索提示空间和识别高质量提示词的策略进行分类,以提升模型性能。本节将综述和总结四类代表性方法:基于编辑的方法、生成式方法、文本梯度方法和进化式方法。
基于编辑的提示词优化
早期的提示词优化尝试主要聚焦于基于编辑的方法,通过预定义的编辑操作(如插入、删除或替换 token)对人工编写的提示词进行迭代优化。这类方法将提示词优化视为提示空间上的局部搜索问题,旨在逐步提升提示词质量,同时保持原始指令的核心语义。例如,GRIPS 将指令拆分为短语,并应用短语级编辑操作(删除、交换、释义和添加),以逐步提升提示词质量。Plum 在 GRIPS 的基础上引入了模拟退火、变异和交叉等元启发式策略。TEMPERA 则将编辑过程建模为强化学习问题,训练策略模型高效地执行不同编辑技术,构建与查询相关的提示词。
生成式提示词优化
与基于编辑的方法通过局部修改提示词不同,生成式方法利用大语言模型(LLM)根据基础提示词和多种优化信号,迭代生成全新的提示词。相比局部编辑,生成式方法能够探索更广泛的提示空间,生成更丰富且语义多样的候选提示词。
提示词生成过程通常由多种优化信号驱动,引导 LLM 生成更优提示词。这些信号包括预定义的重写规则、输入输出示例、数据集或程序描述,还可以结合历史提示词及其评估分数、指定任务目标和约束的元提示词,以及指示优化方向的信号。此外,一些方法还利用成功与失败案例,突出有效或有问题的提示词模式。例如,ORPO 通过将先前生成的候选提示词及其评估分数输入 LLM,生成新的指令。StraGo 则结合成功与失败案例,识别获得高质量提示词的关键因素。优化信号还可与高级搜索策略结合,如 Gibbs 采样、蒙特卡洛树搜索(MCTS)、贝叶斯优化和神经 bandit 方法。这些搜索策略提升了提示空间的探索效率和可扩展性。例如,PromptAgent 将提示词优化建模为策略规划问题,并利用 MCTS 高效搜索专家级提示空间。MIPRO 则采用贝叶斯优化,寻找指令候选与 few-shot 示例的最优组合。
虽然大多数生成式方法使用冻结的 LLM 生成新提示词,近期研究也探索了利用强化学习训练策略模型进行提示词生成。例如,Retroformer 训练策略模型,通过总结先前失败案例的根本原因,迭代优化提示词。
基于文本梯度的提示词优化
除了直接编辑和生成提示词外,最新研究还探索了利用“文本梯度”指导提示词优化的方法。这类方法受到神经网络中梯度学习的启发,但并非对模型参数计算数值梯度,而是生成自然语言反馈(即“文本梯度”),用于指导提示词如何更新以优化目标。当获得文本梯度后,提示词会根据反馈进行更新。此类方法的关键在于如何生成文本梯度,以及如何据此更新提示词。例如,ProTeGi 通过批评当前提示词生成文本梯度,随后按照梯度的反方向编辑提示词。这样的“梯度下降”步骤结合了束搜索和 bandit 策略,以高效寻找最优提示词。类似地,TextGrad 将这一思想推广到复合 AI 系统,将文本反馈视为“自动微分”,利用 LLM 生成的建议迭代优化提示词、代码或其他符号变量。近期工作还探索了复合 AI 系统中的提示词优化,目标是自动优化包括模型参数、提示词、模型选择和超参数在内的异构组件配置。
进化式提示词优化
除了上述优化技术外,进化算法也被广泛应用于提示词优化,作为一种灵活且高效的方法。这类方法将提示词优化视为进化过程,维护一组候选提示词,通过变异、交叉和选择等进化算子不断优化。例如,EvoPrompt 采用遗传算法(GA)和差分进化(DE)两种主流进化算法,引导优化过程以寻找高性能提示词。其核心操作包括变异和交叉:新候选提示词通过组合两个父提示词的片段,并对特定元素进行随机修改生成。PROMPTBREEDER 也采用类似思路,通过迭代变异任务提示词种群来进化提示词。其关键特性是引入“变异提示词”,即用于指定任务提示词如何变异的指令。这些变异提示词既可以预定义,也可由 LLM 动态生成,从而为提示词进化提供了灵活且自适应的机制。
记忆优化
记忆对于智能体在长任务中进行推理、适应和高效操作至关重要。然而,AI 智能体常常受到有限上下文窗口和遗忘现象的限制,导致上下文漂移和幻觉等问题。这些局限推动了记忆优化技术的发展,以实现智能体在动态环境中的泛化和一致性行为。本文综述聚焦于推理阶段的记忆优化策略,这些方法无需修改模型参数,而是在推理过程中动态决定保留、检索和丢弃哪些信息。
我们将现有方法分为两类优化目标:短期记忆,关注在当前活动上下文中保持连贯性;长期记忆,支持跨会话的持久检索。这种以优化为导向的视角,将关注点从静态记忆结构(如内部记忆与外部记忆)转向动态记忆控制,强调如何调度、更新和复用记忆以支持决策。下文将分别介绍每一类别中的代表性方法,突出它们在提升推理准确性和长时序任务中的有效性方面的作用。
短期记忆优化
短期记忆优化关注于管理 LLM 工作记忆中的有限上下文信息,通常包括最近的对话轮次、中间推理轨迹以及任务相关的即时内容。随着上下文扩展,记忆需求显著增加,使得在固定上下文窗口内保留所有信息变得不切实际。为此,研究提出了多种技术用于压缩、摘要或选择性保留关键信息。常见策略包括摘要、选择性保留、稀疏注意力和动态上下文过滤。例如,某些方法提出递归摘要技术,逐步构建紧凑且全面的记忆表示,从而在长时间交互中保持一致性响应。MemoChat 通过对话历史维护对话级记忆,支持连贯且个性化的交互。COMEDY 和 ReadAgent 进一步将提取或压缩的记忆轨迹融入生成过程,使智能体能够在长对话或文档中保持上下文。此外,部分方法通过动态调整上下文或检索中间状态轨迹,促进多跳推理。例如,MoT 和 StructRAG 检索自生成或结构化记忆以指导中间步骤。MemoryBank 受艾宾浩斯遗忘曲线启发,分层摘要事件并根据新近性与相关性更新记忆。Reflexion 使智能体能够反思任务反馈并存储情景洞察,促进长期自我提升。
这些方法显著提升了局部连贯性和上下文效率。然而,仅依赖短期记忆难以跨会话保留知识或实现长期泛化,因此亟需补充长期记忆机制。
长期记忆优化
长期记忆优化通过提供持久且可扩展的存储空间,突破了短上下文窗口的限制,使智能体能够跨会话保留和检索事实知识、任务历史、用户偏好和交互轨迹,从而支持长期连贯的推理与决策。该领域的核心目标是管理日益复杂和扩展的记忆空间,同时保持记忆存储与推理过程的清晰分离。外部记忆既可以是非结构化的,也可以组织为元组、数据库或知识图等结构化格式,并可涵盖多种来源和模态。
长期记忆优化的关键范式是“检索增强生成”(Retrieval-Augmented Generation, RAG),即通过检索将相关外部记忆融入推理过程。例如,EWE 为语言模型增加显式工作记忆,动态存储检索到的片段的潜在表示,重点在于每一步解码时组合静态记忆条目。A-MEM 则通过动态索引与链接构建互联知识网络,使智能体能够形成不断演化的记忆。另一重要方向是智能体自主检索(agentic retrieval),即智能体自主决定何时、检索哪些内容,以及轨迹级记忆(trajectory-level memory),利用过往交互指导未来行为。高效索引、记忆剪枝和压缩等技术进一步提升了系统的可扩展性。例如,相关工作提出了基于 RAG 的轻量级遗忘框架,通过修改检索用的外部知识库,系统可模拟遗忘效应而无需调整底层 LLM。另有研究提出自进化记忆系统,无需预定义操作即可维护长期记忆。除了检索策略和记忆控制机制外,记忆结构与编码方式也显著影响系统性能。基于向量的记忆系统将记忆编码为稠密潜在空间,支持快速动态访问,如 MemGPT、NeuroCache、G-Memory 和 AWESOME 实现了跨任务的记忆整合与复用。Mem0 进一步提出了面向生产的记忆中心架构,实现持续抽取与检索。部分方法借鉴生物或符号系统以提升可解释性,如 HippoRAG 通过轻量级知识图实现海马体式索引,GraphReader 和 Mem0 利用图结构捕捉对话依赖并指导检索。在符号领域,ChatDB 通过 SQL 查询结构化数据库,另有神经符号框架同时以自然语言和符号形式存储事实与规则,支持精确推理与记忆追踪。
近期研究还强调了推理阶段的记忆控制机制的重要性,这些机制决定了何时、如何存储、更新或丢弃记忆。例如,MATTER 能够从多种异构记忆源中动态选择相关片段以支持问答任务,AWM 支持在线和离线场景下的持续记忆更新。MyAgent 赋予智能体记忆感知的回忆机制,解决了 LLM 在时间认知上的局限。MemoryBank 提出了认知启发的记忆更新策略,通过周期性回顾过去知识来缓解遗忘并增强长期记忆。强化学习和优先级策略也被用于引导记忆动态。例如,MEM1 利用强化学习维护不断演化的内部记忆状态,有选择地巩固新信息并丢弃无关内容。A-MEM 提出了一种智能体记忆架构,能够根据使用情况自主组织、更新和剪枝记忆。MrSteve 引入了“what-where-when”情景记忆,将长期知识分层结构化,支持目标导向的规划与任务执行。这些方法使智能体能够主动管理记忆,补充短期记忆机制。同时,MIRIX 在多智能体协作场景下提出了包含六种专用记忆类型的智能体记忆系统,实现了协同检索,并在长时序任务中取得了最先进的性能。
工具优化
工具是智能体系统中的关键组件,作为智能体感知和与现实世界交互的接口。它们使智能体能够访问外部信息源、结构化数据库、计算资源和 API,从而增强智能体解决复杂现实问题的能力。因此,工具使用已成为 AI 智能体的核心能力,尤其是在需要外部知识和多步推理的任务中。然而,仅仅让智能体能够访问工具还远远不够。高效的工具使用要求智能体能够识别何时以及如何调用合适的工具,理解工具输出,并将其整合到多步推理过程中。因此,近期研究聚焦于工具优化,旨在提升智能体智能且高效地使用工具的能力。
现有关于工具优化的研究主要分为两个互补方向。第一个方向研究较多,重点在于提升智能体与工具交互的能力。具体方法包括{训练策略、提示工程和推理算法},旨在增强智能体理解、选择和执行工具的能力。第二个方向较新且仍在发展,关注于优化工具本身,通过修改现有工具或创造新工具,使其更好地契合目标任务的功能需求。
基于训练的工具优化
基于训练的工具优化旨在通过学习更新底层 LLM 的参数,从而提升智能体使用工具的能力。这一方法的动机在于,LLM 仅在文本生成任务上进行预训练,未曾接触过工具使用或交互式执行,因此缺乏调用外部工具和理解工具输出的内在能力。基于训练的方法通过显式地教会 LLM 如何与工具交互,将工具使用能力直接嵌入到智能体的内部策略中。
有监督微调工具优化
该方向的早期工作主要依赖于有监督微调(SFT),即在高质量的工具使用轨迹上训练LLM,明确演示工具应如何被调用和集成到任务执行中。这类方法的核心在于收集高质量的工具使用轨迹,通常包括输入查询、中间推理步骤、工具调用和最终答案。这些轨迹为智能体提供了明确的监督信号,教会其如何规划工具使用、执行调用以及将结果整合到推理过程中。例如,ToolLLM和GPT4Tools等方法利用更强大的LLM生成指令及相应的工具使用轨迹。受人类学习过程启发,STE引入模拟的试错交互以收集工具使用示例,而TOOLEVO则采用MCTS实现更主动的探索并收集更高质量的轨迹。
此外,最新研究表明,即使是先进的LLM在多轮交互中的工具使用也面临挑战,尤其是在涉及复杂函数调用、长期依赖或请求缺失信息时。为生成高质量的多轮工具调用训练轨迹,Magnet提出合成一系列查询和可执行的工具函数调用,并利用图结构构建可靠的多轮查询。BUTTON通过两阶段流程生成合成的组合式指令微调数据,底层阶段组合原子任务构建指令,顶层阶段采用多智能体系统模拟用户、助手和工具生成轨迹数据。为实现更真实的数据生成,APIGen-MT提出两阶段框架,先生成工具调用序列,再通过模拟人机交互转化为完整的多轮交互轨迹。
收集到工具使用轨迹后,通常采用标准语言建模目标对LLM进行微调,使模型学习到工具调用和集成的成功模式。除了这一常规范式外,一些研究还探索了更高级的训练策略以进一步提升工具使用能力。例如,Confucius引入由易到难的课程学习范式,逐步让模型接触越来越复杂的工具使用场景。Gorilla则在训练流程中集成文档检索器,使智能体能够通过检索文档动态适应不断变化的工具集,从而实现工具使用的知识支撑。
强化学习工具优化
虽然有监督微调在教会智能体使用工具方面取得了良好效果,但其性能往往受限于训练数据的质量和覆盖范围。低质量的轨迹会导致性能提升有限,而在有限数据集上微调也可能影响泛化能力,尤其是在智能体推理时遇到未见过的工具或任务配置。为了解决这些问题,近期研究开始采用强化学习(RL)作为工具使用的优化范式。通过交互和反馈,RL能够促使智能体学习更具适应性和鲁棒性的工具使用策略。相关工作如 ReTool 和 Nemotron-Research-Tool-N1(Tool-N1)均展示了在交互式环境下通过轻量级监督获得更强泛化能力的工具使用策略。在此基础上,后续研究进一步探索了更有效的奖励函数设计,以及利用合成数据生成和过滤提升 RL 训练的稳定性与效率。
推理时工具优化
除了基于训练的方法外,另一类工作关注于在推理阶段提升工具使用能力,而无需修改 LLM 参数。这些方法通常通过优化提示中的工具相关上下文信息,或在测试时通过结构化推理引导智能体的决策过程来实现。该范式下主要有两个方向:(1)基于提示的方法,通过优化工具文档或说明的表达方式,帮助智能体更好地理解和使用工具;(2)基于推理的方法,利用测试时推理策略,如 MCTS 和其他树搜索算法,在推理过程中更有效地探索和选择工具。
基于提示的工具优化
工具相关信息通常通过工具文档在提示中提供给智能体。这些文档描述工具的功能、使用方式和调用格式,帮助智能体理解如何与外部工具交互以解决复杂任务。因此,提示中的工具文档是智能体与可用工具之间的关键桥梁,直接影响工具使用决策的质量。近期研究聚焦于优化文档的呈现方式,包括重构原始文档或通过交互式反馈进行精炼。例如,EASYTOOL 将不同工具文档转化为统一且简洁的说明,使 LLM 更易于理解和使用。DRAFT 和 PLAY2PROMPT 等方法则借鉴人类试错过程,提出交互式框架,通过反馈迭代优化工具文档。
此外,最新方向探索同时优化工具文档和智能体提示指令的方法。例如,某些工作提出了联合优化框架,同时精炼智能体的提示指令和工具描述,统称为上下文,以提升二者的交互效果。优化后的上下文不仅降低了计算开销,还提升了工具使用效率,凸显了上下文设计在推理时工具优化中的重要作用。
基于推理的工具优化
推理与规划技术在推理阶段提升智能体工具使用能力方面展现出强大潜力。早期工作如 ToolLLM 验证了 ReAct 框架在工具使用场景中的有效性,并提出了深度优先树搜索算法,使智能体能够快速回溯到最近一次成功状态而非从头开始,大幅提升了效率。ToolChain 通过引入成本函数对分支未来成本进行估算,从而在树搜索中提前剪枝低价值路径,避免了传统 MCTS 中常见的低效回滚。Tool-Planner 则将功能相似的工具聚合为工具包,并利用树状规划方法快速重选和调整工具。
工具功能优化
除了优化智能体的行为外,另一条重要研究方向关注于直接修改或生成工具本身,以更好地支持任务相关的推理与执行。受人类不断开发新工具以满足任务需求的启发,这类方法旨在通过动态调整工具集来扩展智能体的动作空间,而不是让任务适应固定工具集。例如,CREATOR 和 LATM 提出框架,可针对新任务自动生成工具文档和可执行代码。CRAFT 利用以往任务中的可复用代码片段,为未见场景创造新工具。AgentOptimiser 将工具和函数视为可学习权重,允许智能体通过 LLM 迭代优化工具实现。最新工作 Alita 更进一步,将工具创建扩展为多组件程序(MCP)格式,显著提升了工具的复用性和环境管理能力。
多智能体优化
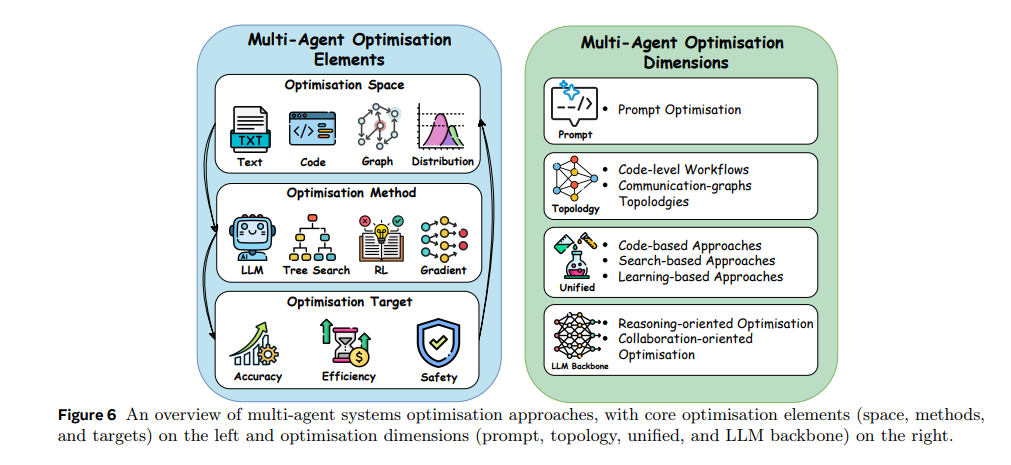
多智能体工作流定义了多个智能体通过结构化拓扑和交互模式协作解决复杂任务的方式。该领域经历了根本性转变:从人工设计的智能体架构(研究者显式指定协作模式和通信协议),到能够自动发现高效协作策略的自进化系统。这一演变将工作流设计重新定义为在三个互相关联空间上的搜索问题:智能体拓扑的结构空间、智能体角色与指令的语义空间,以及LLM骨干模型的能力空间。最新方法通过进化算法、强化学习等多种优化技术探索这些空间,在准确性、效率和安全等多重优化目标之间实现不同权衡。
本节将沿四个关键维度梳理多智能体工作流优化的进展。首先介绍人工设计范式,奠定协作基础原理;随后讨论提示级优化,在固定拓扑下细化智能体行为;接着介绍拓扑优化,聚焦于发现多智能体完成任务的最优架构;进一步探讨综合方法,联合优化提示、拓扑及其他系统参数,实现一体化优化;最后分析LLM骨干优化,通过针对性训练提升智能体的推理与协作能力。通过这一视角,展示了该领域如何不断扩展可搜索与可优化参数的边界,从智能体指令、通信结构到底层模型核心能力。图6展示了多智能体工作流优化的核心要素与关键维度概览。
人工设计的多智能体系统
人工设计的工作流构成了多智能体协作研究的基础。这些架构将研究者对任务分解、智能体能力和协调机制的理解编码为显式的交互模式。通过分析这些手工设计的范式,我们可以理解指导智能体协作的设计原则,以及塑造系统架构的工程考量。
并行工作流
并行工作流采用并发执行与集体决策机制。最简单的形式是多个独立智能体并行生成解决方案,随后通过多数投票选出最终输出。实证研究表明,采用小型LLM的并行生成可以达到甚至超越单一大型LLM的性能。多层聚合进一步降低了误差界限并提升了鲁棒性。近期扩展方法引入了动态任务图和异步线程,实现了近线性扩展和更低的决策延迟。然而,尽管计算吞吐量可水平扩展,协调与一致性管理的工程成本却呈指数增长。
层级工作流
当子任务存在严格的上下文依赖时,层级工作流提供了结构化的替代方案。这类框架将智能体组织为多层自顶向下结构或顺序管道,系统在各层分解任务,每层负责不同的子任务。该设计在复杂的目标驱动任务(如深度研究和代码生成)中表现优异。但其固定的拓扑限制了适应性,尤其在面对动态目标或资源约束时。
多智能体辩论
为兼顾准确性与可解释性,研究者提出了辩论范式,即智能体通过对抗—协商—仲裁循环,讨论并纠正推理错误。早期工作探索了对称辩手机制,近期研究则引入了角色不对称、可调节辩论强度和以说服力为导向的策略。此外,置信度门控辩论策略表明,仅在单一模型置信度较低时触发多智能体辩论,可显著降低推理成本且不影响性能。
尽管人工设计的工作流和结构化多智能体范式取得了成功,最新实证研究发现,配合精心设计提示的大型LLM在多个推理基准上可达到复杂多智能体讨论框架的性能。该发现,加之手工多智能体工作流的高实现与维护成本,推动了自进化多智能体系统的发展——这些系统能够自动学习、适应并重构自身工作流,而不依赖于固定架构和静态协调协议。
自进化多智能体系统
手工设计的多智能体工作流工程成本高、适应性有限,推动了自动化、自进化系统的发展。这类系统能够根据性能反馈自动设计、评估和优化智能体工作流,通过调整提示词、拓扑结构和协作策略实现自我改进。与硬编码配置不同,自进化系统将工作流优化视为搜索问题,在多层次配置空间中探索和优化,从局部提示到全局拓扑结构。
为高效探索搜索空间,研究者提出了多种搜索算法,包括强化学习、蒙特卡洛树搜索、生成模型等高效探索方法,以及进化算子等鲁棒搜索技术。优化目标也从单一性能提升扩展到多维目标,如任务准确率、计算效率和安全性。随着搜索能力提升,核心挑战也从“找到最优解”转向“如何定义动态多智能体场景下的最优性”。
多智能体提示词优化
实现自进化的一条重要路径是提示词优化,提示词既定义了智能体角色,也规定了任务指令。最新方法将这些提示词编码的配置视为形式化搜索空间,进行系统性优化。事实上,多智能体工作流中的提示词优化往往基于第~\ref{subsec:prompt_optimisation}节介绍的单智能体技术,并进一步扩展到多智能体协作与任务依赖场景。例如,DSPy Assertions 引入了运行时自进化机制,将管道模块的中间输出作为搜索空间,通过断言驱动的回溯和显式反馈,引导 LLM 自动修正违反程序约束的输出。AutoAgents 则将提示词优化从单智能体扩展到整个多智能体团队配置,通过专用元智能体的结构化对话,优化智能体角色分工和执行计划。
拓扑优化
拓扑优化代表了多智能体系统设计中的范式转变:不再将通信结构视为固定约束,而是将拓扑本身作为强大的优化目标。这一洞察源于一个基本观察——即使最优提示词也无法弥补糟糕的架构选择。从表示中心视角来看,现有工作主要分为两大互补方向:程序/代码级工作流拓扑与通信图拓扑;这一分类强调了“优化什么”——即拓扑的表示方式。这不仅是技术进步,更是概念上的转变——媒介(拓扑)与信息(提示词)同等重要。
代码级工作流
将工作流表示为可执行程序或类型化代码图,使智能体协调变得显式且可验证,支持组合复用与自动检查。AutoFlow 将搜索空间设为自然语言程序(CoRE),并通过强化学习训练生成器 LLM,支持微调与上下文使用。与 AutoFlow 相比,AFlow 用类型化、可复用算子替代自然语言程序空间,形成代码图;结合蒙特卡洛树搜索(MCTS)与 LLM 引导扩展及软概率选择,在庞大设计空间中实现更结构化、高效的探索。ScoreFlow 更进一步,将代码表示提升到连续空间,并采用基于梯度的优化(Score-DPO,一种结合定量反馈的直接偏好优化变体)来改进工作流生成器,从而解决了 RL/MCTS 探索效率低下的问题,实现任务级自适应工作流生成。与基于搜索的优化方法不同,MAS-GPT 在一致性导向语料(包括智能体间和内部一致性)上进行有监督微调,使单次推理即可生成完整、可执行的 MAS 代码库,牺牲广泛搜索覆盖以换取一次性高效和更依赖数据质量。
通信图拓
与代码级程序不同,这一方向将工作流视为多智能体通信图,其连接关系成为优化目标。
GPTSwarm 将搜索空间定义为智能体计算图中的连接关系,并将离散空间松弛为连续边概率,同时采用强化学习(RL)学习最优连接方案。
在 GPTSwarm 基础上,DynaSwarm 将搜索空间从单一优化图扩展为图结构组合,通过 Actor–Critic(A2C)优化和轻量级图选择器实现实例级拓扑选择,解决了不同查询需要不同图结构以获得最优性能的关键问题。
G-Designer 不再在固定空间中屏蔽边,而是采用变分图自动编码器直接生成任务自适应通信图,通过调节结构复杂度在质量与 token 成本间取得平衡。
MermaidFlow 将拓扑表示为类型化、声明式图,并通过安全约束进化算子仅探索语义有效区域,实现静态验证。
除静态图生成外,部分方法在执行过程中动态调整通信图结构。
DyLAN 将搜索空间视为跨层的活跃智能体,并引入提前停止的时间轴;通过 LLM 排序器剪枝低价值智能体,并利用智能体重要性分数进行自动团队优化(传播–聚合–选择)。
Captain Agent 将搜索空间定义为子任务特定的智能体与工具集合(检索、过滤,必要时生成);通过嵌套群组对话与反思,现场迭代优化团队构成,而非从头合成固定图结构。Flow 与 DyLAN 的剪枝和 Captain Agent 的团队重组不同,通过动态调整 AOV 图结构实现:先根据并行性/依赖性指标选择初始图,再在线优化工作流与子任务分配,实现模块化并发与最小协调成本。
正交于图生成方法,剪枝方法通过移除冗余或高风险通信,优化并保留关键协作。AgentPrune 将搜索空间视为时空通信图,空间边表示对话内部通信,时间边表示对话间通信,剪枝目标涵盖两者。其采用可训练的低秩图掩码,实现一次性剪枝,识别并消除冗余通信,优化 token 成本。在此基础上,AGP(自适应图剪枝)将搜索空间扩展为智能体数量(硬剪枝)与通信边(软剪枝),通过两阶段训练策略联合优化这两个维度,针对每个任务动态确定最优智能体数量及连接,实现任务自适应拓扑生成。上述方法以效率与适应性为目标进行剪枝,而 G-Safeguard 则以安全为目标:其以通信边为搜索空间,利用 GNN 检测高风险节点,并通过确定性规则在模型驱动阈值下剪除外部边缘,实现对抗攻击防御。相关工作 NetSafe 总结了拓扑安全风险,并提出基于图的检测与干预原则,作为补充的安全视角。
联合优化
联合优化源于一个关键洞察:提示词与拓扑结构并非独立设计选择,而是智能体系统中深度互联的两个方面。精心设计的提示词若配合糟糕的通信结构难以发挥作用,而优雅的拓扑结构若智能体指令不佳也难以带来收益。这种相互依赖推动了该领域沿三条技术路径发展:基于代码的统一优化、结构化优化方法和学习驱动架构。每种方法从不同角度解决联合优化难题,展现了效率与性能之间的不同权衡。
基于代码的方法
最直接的联合优化方法将代码视为提示词与拓扑结构的通用表示。ADAS 首创了这一思路,通过 Meta Agent Search 框架,将提示词、工作流和工具使用统一表示为 Python 代码,实现智能体的迭代生成与评估。这种以代码为中心的视角自然支持协同进化,修改智能体逻辑会同时影响指令和结构。FlowReasoner 进一步推动了代码范式,聚焦于查询级适应,每个查询生成一个 MAS(多智能体系统),而非每个任务。其在 DeepSeek-R1 的推理能力蒸馏基础上,结合 GRPO 和外部执行反馈优化元智能体,实现性能与效率的提升。上述方法表明,代码为联合优化提供了灵活的基础,但适应粒度各有不同。
基于搜索的方法
另一类方法不依赖代码隐式协同进化,而是开发显式机制协调提示词与拓扑结构设计。EvoAgent 将搜索空间定义为文本化的智能体配置(角色、技能、提示词),并采用进化算法(变异、交叉、选择算子)生成多样化智能体种群。与代码隐式协同进化相比,EvoAgent显式进化配置级特征,而非合成程序。相较于 EvoAgent 的文本配置搜索,EvoFlow 也采用进化搜索,但对象是算子节点工作流图。其引入预定义复合算子(如 CoT、辩论),并通过算子库与标签选择约束变异/交叉,缩小搜索空间。EvoFlow 还将 LLM 选择作为决策变量,平衡性能与成本;多样性选择保持种群多样性,多目标适应度驱动成本–性能的帕累托优化。
补充于进化搜索,MASS 提出了一种三阶段、条件耦合的优化框架:首先对每个智能体的提示词进行局部微调,然后在剪枝后的空间中搜索工作流拓扑,最后在选定的拓扑上进行全局提示词优化;该过程交替进行,而非完全解耦,是联合优化的实用近似。最新的 DebFlow 将搜索空间表示为算子节点的工作流图,并采用多智能体辩论进行优化。通过对执行失败的反思引导,DebFlow 避免了穷举搜索,同时在自动化智能体设计中开创了辩论机制。这些结构化方法以牺牲部分灵活性为代价,换取更有针对性的优化策略。在算子节点表示的基础上,MAS-ZERO 将统一优化视为纯推理时搜索,通过可解性引导的迭代重组智能体团队和任务分解,无需梯度更新或离线训练。
基于学习的方法
最新一波研究采用复杂的学习范式联合优化提示词与拓扑结构。MaAS 从优化单一架构转向学习智能体超级网络——即多智能体系统的概率分布。其控制器网络通过蒙特卡洛和文本梯度优化采样查询特定架构,在显著降低推理成本的同时取得更优性能。ANN 将多智能体协作概念化为分层神经网络,每一层由专门的智能体团队组成。其采用两阶段优化流程:前向任务分解与后向文本梯度优化。该方法联合进化智能体角色、提示词和层间拓扑结构,实现训练后对新任务的自适应。
LLM骨干优化
智能体背后的LLM骨干的进化是多智能体进化中的关键环节,尤其体现在智能体如何通过交互提升其协作与推理能力。
面向推理的优化
一类重要工作聚焦于通过多智能体协作提升LLM骨干的推理能力。例如,多智能体微调(multi-agent finetuning)利用从多智能体辩论中采集的高质量协作轨迹进行有监督微调,使智能体实现(1)角色专属能力提升,(2)底层骨干模型推理能力增强。类似地,Sirius和MALT采用自我博弈(self-play)收集高质量协作轨迹,并在各自的多智能体协作框架下训练智能体。两者均在一定程度上利用失败轨迹,但方法有所不同:Sirius仅依赖SFT,并通过自我纠错将错误轨迹整合进训练集;MALT则采用DPO,自然利用负样本。这些方法为多智能体系统自我提升提供了早期证据,尽管目前主要应用于较简单场景(如多智能体辩论或“生成-验证-回答”系统)。进一步,MaPoRL引入任务特定奖励塑造,通过强化学习显式激励智能体间沟通与协作。MARFT则建立了传统多智能体强化学习(MARL)与基于LLM的多智能体强化微调之间的桥梁。在此基础上,MARTI提出了更可定制的多智能体强化微调框架,支持灵活设计智能体结构与奖励函数。实证结果显示,LLM骨干在协作训练过程中协作能力显著提升。
面向协作的优化
除推理能力外,另一类工作关注于提升多智能体系统中的沟通与协作能力。核心假设是LLM智能体并非天然具备高效团队协作能力,其协作沟通技能需通过专门训练获得。早期代表如COPPER,采用PPO训练共享反思器,为多智能体协作轨迹生成高质量、角色感知的个性化反思。OPTIMA则更直接地以多智能体系统中的沟通效率(如token消耗与沟通可读性)为目标,探索通过SFT、DPO及混合方法实现效果与效率的权衡。在高强度信息交换任务中,其报告性能提升2.8倍,token成本不足10%,充分展现了智能体协作能力扩展的潜力。进一步,MaPoRL指出,直接提示原生LLM并依赖其固有协作能力的主流范式存在局限,因而在多智能体辩论框架下引入精心设计的强化学习信号,显式激发协作行为,鼓励智能体更频繁且高质量地沟通。
域特定优化
前文主要聚焦于通用领域下的智能体优化与进化技术,而在特定领域(如生物医学、编程、金融与法律研究)中,智能体系统面临独特挑战,需要定制化的优化策略。这些领域通常具有专门的任务结构、领域知识库、特定数据模态和操作约束,这些因素显著影响智能体的设计、优化与进化方式。本节系统梳理了近期在域特定智能体优化与进化方面的进展,重点介绍了针对各领域独特需求而发展的高效技术。
生物医学领域的智能体优化
在生物医学领域,智能体优化聚焦于使智能体行为与真实临床环境的流程和操作需求相契合。最新研究表明,域特定智能体设计在医疗诊断和分子发现两大应用场景中取得了显著成效。下文将分别介绍这两个领域中的代表性智能体优化策略。
医学诊断
医学诊断旨在根据临床信息(如症状、病史和诊断检测结果)判断患者的健康状况。近年来,越来越多的研究探索了自主智能体在医学诊断中的应用,使系统能够自动进行诊断对话、提出澄清性问题并生成合理的诊断假设。这类智能体通常在信息不完整或模糊的情况下做出决策,诊断过程往往涉及多轮交互,智能体通过追问补充缺失信息。为了支持稳健的临床推理,智能体还需集成外部知识库或与专业医疗工具交互,实现信息检索和循证推理。
针对这些领域特定需求,近期研究聚焦于专为医学诊断优化的智能体架构。其中,多智能体系统在建模医学诊断的复杂性和多步推理方面展现出强大潜力,相关方法主要分为“仿真驱动”和“协作型设计”两类。仿真驱动系统通过为智能体分配特定角色,并在模拟医疗环境中交互学习诊断策略,力求还原真实临床场景。例如,MedAgentSim 提出自进化仿真框架,结合经验回放、链式思维集成和基于 CLIP 的语义记忆,支持诊断推理。PathFinder 通过多智能体协作,模拟专家在超高分辨率医学图像上的诊断流程。协作型多智能体系统则强调智能体间的集体决策与协作。例如,MDAgents 支持多智能体自适应协作,由主持智能体整合多方建议并在必要时查询外部知识。MDTeamGPT 将该范式扩展至多学科会诊,通过反思性讨论机制实现团队式自进化诊断流程。
另一类诊断智能体优化工作聚焦于工具集成与多模态推理。例如,MMedAgent 针对现有多模态大模型泛化能力有限的问题,动态集成不同模态的专业医疗工具。为提升临床可靠性,MedAgent-Pro 引入基于临床标准的诊断规划,并通过任务特定工具智能体整合多模态证据。与固定架构不同,最新研究探索了根据诊断表现动态调整的灵活智能体设计。例如,某些工作提出基于图结构的智能体框架,推理过程可根据诊断结果反馈持续优化。
这些方法强调了专业化、多模态和交互式推理,是医学诊断智能体系统发展的关键原则。
分子发现与符号推理
生物医学领域的分子发现任务要求智能体能够对化学结构、反应路径和药理约束进行精确的符号推理。为支持分子发现,最新的智能体系统引入了多项定制技术,包括集成化学分析工具、增强记忆以实现知识保留,以及多智能体协作。核心方法之一是领域特定工具集成,使智能体能够通过可执行的化学操作进行化学推理。例如,CACTUS 为智能体集成了 RDKit 等化学信息学工具,确保生成的输出在化学上有效。通过将推理过程与领域工具集紧密结合,CACTUS 在化学任务上显著优于未集成工具的智能体。类似地,LLM-RDF 通过协调多个专用智能体自动化化学合成,每个智能体负责特定任务,并配备相应工具用于文献挖掘、合成规划或反应优化。
另一重要研究方向是基于记忆的推理,智能体通过记录以往问题的解决过程进行学习。ChemAgent 将复杂化学任务分解为更小的子任务,并存储在结构化记忆模块中,实现高效检索与优化。OSDA Agent 在此基础上引入自反思机制,将失败的分子设计抽象为结构化记忆更新,指导并提升后续决策能力。与此同时,多智能体协作也带来了显著优势。DrugAgent 提出协调器架构,整合机器学习预测器、生物医学知识图谱和文献检索智能体的证据,采用链式思维(Chain-of-Thought)和 ReAct 框架,支持可解释的多源推理。LIDDIA 进一步推广了该设计,分配模块化角色(如推理者、执行者、评估者和记忆模块),共同模拟药物化学中的迭代工作流,支持分子的多目标评估。
编程领域的智能体优化
在编程领域,智能体优化聚焦于使智能体行为与既有软件工程工作流的流程和操作需求相契合。近期研究表明,面向特定领域的智能体设计在代码优化和代码调试两个关键应用场景中取得了显著成效。下文将分别介绍这两个领域中的代表性智能体优化策略。
代码优化
代码优化指在保持原有功能的前提下,迭代提升代码质量、结构和正确性。最新研究越来越多地关注基于智能体的系统,支持该任务的领域特定优化,重点在于自我改进、协作工作流以及与编程工具的集成。这些系统旨在模拟人类参与的优化流程,强化对软件工程最佳实践的遵循,并确保代码在迭代开发周期中始终保持健壮、可读和可维护。关键优化策略之一是自我反馈机制,即智能体对自身输出进行批评和修订。例如,Self-Refine 提出了一种轻量级框架,语言模型能够对自身输出生成自然语言反馈,并据此修订代码。类似地,CodeCriticBench 提供了一个全面的基准,用于评估 LLM 的自我批评与优化能力,智能体需通过结构化自然语言反馈识别、解释并修复代码缺陷。LLM-Surgeon 则提出系统性框架,语言模型诊断自身代码输出中的结构和语义问题,并根据学习到的修复模式进行有针对性的编辑,从而在保持功能的前提下优化代码质量。这些方法无需针对具体任务重新训练,能够持续提升代码质量。
另一类研究探索了基于经验驱动的学习,智能体通过记忆增强推理,系统性记录并复用以往任务的解决方案,从而提升问题解决能力。例如,AgentCoder 和 CodeAgent 通过为智能体分配专门角色(如编码者、审阅者、测试者),模拟协作开发工作流,智能体通过结构化对话周期迭代优化代码。这些系统支持集体评估与修订,促进角色专精和深度决策。此外,CodeCoR 和 OpenHands 等工具增强框架通过集成外部工具和模块化智能体交互,实现动态代码剪枝、补丁生成和上下文感知优化。VFlow 将 Verilog 代码生成任务的工作流优化问题建模为 LLM 节点的代码表示图上的搜索任务,采用协作进化与历史经验蒙特卡洛树搜索(CEPE-MCTS)算法。这些进展强调了迭代反馈、模块化设计和交互式推理是构建自适应代码优化智能体系统的核心原则。
代码调试
代码调试面临复杂挑战,需要精准的故障定位、执行感知推理和迭代修正,这些能力通常在通用 LLM 中缺失。为应对这些挑战,领域特定优化聚焦于将智能体角色和工作流与人类调试实践中的结构化推理模式和工具使用相结合。关键策略之一是利用运行时反馈实现自我修正。例如,Self-Debugging 和 Self-Edit 通过将执行轨迹融入调试流程,实现智能体在内部循环中自动定位错误、自然语言推理并有针对性地修复代码,无需外部监督即可实现自主调试。
近期研究还探索了专为支持多阶段调试流程设计的模块化智能体架构。例如,PyCapsule 将编码智能体与执行智能体分离,区分代码生成与语义验证。更高级的系统如 Self-Collaboration 和 RGD 采用协作管道,智能体被分配为测试者、审阅者或反馈分析者等专门角色,模拟专业调试流程。此外,FixAgent 通过分层智能体激活,根据 bug 的复杂性和分析深度动态调度不同智能体,进一步扩展了该范式。
金融与法律领域的智能体优化
在金融和法律领域,智能体优化聚焦于针对领域特定工作流的流程和操作需求,定制多智能体架构、推理策略和工具集成。最新研究在金融决策和法律推理两个关键应用场景中展示了此类设计的有效性,其中模块化设计、协作交互和规则驱动推理对于可靠性能至关重要。下文将分别介绍这两个领域中的代表性智能体优化策略。
金融决策
金融决策要求智能体在不确定且快速变化的环境下运行,需对市场动态进行推理,并整合多源异构信息,如数值指标、新闻情绪和专家知识。针对这些领域特定需求,近期研究聚焦于开发适应金融环境流程和认知需求的多智能体架构。关键策略之一是概念化与协作型智能体设计。例如,FinCon 提出基于 LLM 的多智能体系统,采用概念性语言强化和领域自适应微调,提升决策稳定性和策略一致性。PEER 通过模块化智能体架构(专家、检索者、控制者)及统一微调机制,实现任务专精与通用适应性的平衡。FinRobot 进一步集成外部工具,实现模型驱动推理,使智能体能够将高层策略与可执行金融模型和实时数据流连接起来。
另一类金融决策智能体优化工作聚焦于情感分析与报告生成。异构 LLM 智能体架构通过结合专用情感模块与规则验证器,提升金融报告的鲁棒性,确保符合领域规范。类似地,基于模板的报告框架将报告生成流程分解为智能体驱动的检索、验证和合成阶段,通过真实反馈实现迭代优化。这些方法展示了自进化多智能体系统在复杂金融环境中实现可靠、可解释和上下文感知决策支持的潜力。
法律推理
法律推理要求智能体能够解释结构化法律规则、分析案件证据,并生成符合制度规范和司法标准的输出。为满足这些领域特定需求,最新研究探索了适应法律场景流程和解释需求的多智能体系统。重要方向之一是协作型智能体框架,模拟司法流程并支持结构化论证。例如,LawLuo 提出协同运行的多智能体架构,法律智能体被分配为文档起草、法律论证生成和合规验证等专门角色,由中央控制器监督以确保流程一致性和法律正确性。Multi-Agent Justice Simulation 和 AgentCourt 将该范式扩展到模拟对抗性庭审流程,智能体通过角色分配参与互动,模拟真实法庭动态。AgentCourt 尤其引入自进化律师智能体,通过反思性自博弈不断优化策略,提升辩论质量和程序真实性。
另一类工作聚焦于结构化法律推理和领域可解释性。LegalGPT 在多智能体系统中集成法律链式思维框架,引导法律推理过程以实现可解释和规则对齐。AgentsCourt 结合法庭辩论模拟与法律知识增强,使智能体能够基于编码规则和案例判例进行司法决策。这些方法强调了规则驱动、模块化角色设计和协作推理在构建健壮、透明且符合法律要求的智能体系统中的重要性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号