redis应用
redis应用
一、介绍
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。
Redis是现在最受欢迎的NoSQL数据库之一,Redis是一个使用ANSI C编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库,其具备如下特性:
- 基于内存运行,性能高效
- 支持分布式,理论上可以无限扩展
- key-value存储系统
- 开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
相比于其他数据库类型,Redis具备的特点是:
- C/S通讯模型
- 单进程单线程模型
- 丰富的数据类型
- 操作具有原子性
- 持久化
- 高并发读写
- 支持lua脚本
redis单线程问题
所谓的单线程指的是网络请求模块使用了一个线程(所以不需考虑并发安全性),即一个线程处理所有网络请求,其他模块仍用了多个线程。
redis采用多路复用机制:即多个网络socket复用一个io线程,实际是单个线程通过记录跟踪每一个Sock(I/O流)的状态来同时管理多个I/O流.
Redis应用:token生成、session共享、分布式锁、自增id、验证码等。
Redis多数据库
Redis支持多个数据库,并且每个数据库的数据是隔离的不能共享,并且基于单机才有,如果是集群就没有数据库的概念。
Redis是一个字典结构的存储服务器,而实际上一个Redis实例提供了多个用来存储数据的字典,客户端可以指定将数据存储在哪个字典中。这与我们熟知的在一个关系数据库实例中可以创建多个数据库类似,所以可以将其中的每个字典都理解成一个独立的数据库。每个数据库对外都是一个从0开始的递增数字命名,Redis默认支持16个数据库(可以通过配置文件支持更多,无上限),可以通过配置databases来修改这一数字。客户端与Redis建立连接后会自动选择0号数据库,不过可以随时使用SELECT命令更换数据库。
然而这些以数字命名的数据库又与我们理解的数据库有所区别。首先Redis不支持自定义数据库的名字,每个数据库都以编号命名,开发者必须自己记录哪些数据库存储了哪些数据。另外Redis也不支持为每个数据库设置不同的访问密码,所以一个客户端要么可以访问全部数据库,要么连一个数据库也没有权限访问。最重要的一点是多个数据库之间并不是完全隔离的,比如FLUSHALL命令可以清空一个Redis实例中所有数据库中的数据。综上所述,这些数据库更像是一种命名空间,而不适宜存储不同应用程序的数据。比如可以使用0号数据库存储某个应用生产环境中的数据,使用1号数据库存储测试环境中的数据,但不适宜使用0号数据库存储A应用的数据而使用1号数据库B应用的数据,不同的应用应该使用不同的Redis实例存储数据。由于Redis非常轻量级,一个空Redis实例占用的内存只有1M左右,所以不用担心多个Redis实例会额外占用很多内存。
二、安装
Linux下安装
可从http://redis.io/download下载最新稳定版本,并安装。
$ wget http://download.redis.io/releases/redis-2.8.17.tar.gz
$ tar xzf redis-2.8.17.tar.gz
$ cd redis-2.8.17
$ make
$ cd src
$ ./redis-server
$ ./redis-server ../redis.conf
make完后 redis-2.8.17目录下会出现编译后的redis服务程序redis-server,还有用于测试的客户端程序redis-cli,两个程序位于安装目录 src 目录下。
redis.conf 是一个默认的配置文件。我们可以根据需要使用自己的配置文件。
ubuntu安装
$sudo apt-get update
$sudo apt-get install redis-server
$ redis-server
redis-cli使用
$ redis-cli -h host -p port -a password //远程
$ redis-cli
127.0.0.1:6379> auth 123456 // 默认没有密码,当设置密码时需要auth
OK
redis 127.0.0.1:6379>ping
PONG
127.0.0.1:6379> help
redis-cli 3.0.6
Type: "help @<group>" to get a list of commands in <group>
"help <command>" for help on <command>
"help <tab>" to get a list of possible help topics // 按tab可以切换不同topics
"quit" to exit
redis 127.0.0.1:6379> CONFIG SET loglevel "notice"
OK
redis 127.0.0.1:6379> CONFIG GET loglevel
1) "loglevel"
2) "notice"
redis 127.0.0.1:6379> CONFIG GET *
Redis Select 命令用于切换到指定的数据库,数据库索引号 index 用数字值指定,以 0 作为起始索引值。
127.0.0.1:6379> config get databases
1) "databases"
2) "16"
127.0.0.1:6379> get db_number
(nil)
127.0.0.1:6379> set db_number 0
OK
127.0.0.1:6379> get db_number
"0"
127.0.0.1:6379> select 3
OK
127.0.0.1:6379[3]> get db_number
(nil)
127.0.0.1:6379[3]> set db_number 3
OK
127.0.0.1:6379[3]> keys *
1) "db_number"
三、基础
redis通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。

key命令
支持的命令:keys, type, del, exists
127.0.0.1:6379> keys *
1) "chen"
2) "www"
3) "get"
4) "runoob"
5) "wwang"
127.0.0.1:6379> type chen
list
127.0.0.1:6379> type get
hash
127.0.0.1:6379> del www
(integer) 1
127.0.0.1:6379> exists www
(integer) 0
String类型
它是一个二进制安全的字符串,意味着它不仅能够存储字符串、还能存储图片、视频等多种类型, 最大长度支持512M。
支持的命令:SET、GET
127.0.0.1:6379> set wstrings wang
OK
127.0.0.1:6379> get wstrigns
(nil)
127.0.0.1:6379> get wstrings
"wang"
哈希类型
该类型是由field和关联的value组成的map,特别适合存储对象。其中,field和value都是字符串类型的。
支持的命令: hmset、hget、hgetall、hkeys
127.0.0.1:6379> hmset whash f1 v1 f2 v2 name wang id 100 score 100
OK
127.0.0.1:6379> hgetall whash
1) "f1"
2) "v1"
3) "f2"
4) "v2"
5) "name"
6) "wang"
7) "id"
8) "100"
9) "score"
10) "100"
127.0.0.1:6379> hget whash f1
"v1"
127.0.0.1:6379> hget whash name
"wang"
127.0.0.1:6379> hget whash score
"100"
列表类型
该类型是一个插入顺序排序的字符串元素集合, 基于双链表实现。
支持的命令:lpush、rpush、lrange、llen
127.0.0.1:6379> lpush wlist redis
(integer) 1
127.0.0.1:6379> lpush wlist mongodb
(integer) 2
127.0.0.1:6379> rpush wlist mysql
(integer) 3
127.0.0.1:6379> lrange wlist 0 3
1) "mongodb"
2) "redis"
3) "mysql"
集合类型
Set类型是一种无顺序集合, 它和List类型最大的区别是:集合中的元素没有顺序, 且元素是唯一的。Set类型的底层是通过哈希表实现的。Set类型主要应用于:在某些场景,如社交场景中,通过交集、并集和差集运算,通过Set类型可以非常方便地查找共同好友、共同关注和共同偏好等社交关系。
支持的命令:sadd、smembers
127.0.0.1:6379> sadd wset redis
(integer) 1
127.0.0.1:6379> sadd wset mysql
(integer) 1
127.0.0.1:6379> sadd wset redis
(integer) 0
127.0.0.1:6379> smembers wset
1) "redis"
2) "mysql"
127.0.0.1:6379> scard wset
(integer) 2
顺序集合类型
ZSet是一种有序集合类型,每个元素都会关联一个double类型的分数权值,通过这个权值来为集合中的成员进行从小到大的排序。与Set类型一样,其底层也是通过哈希表实现的。
支持的命令:zadd、zrange、zcard
127.0.0.1:6379> zadd wzset 0 redis
(integer) 1
127.0.0.1:6379> zadd wzset 3 mysql
(integer) 1
127.0.0.1:6379> zadd wzset 2 mongodb
(integer) 1
127.0.0.1:6379> zcard wzset
(integer) 3
127.0.0.1:6379> zrange wzset 0 3
1) "redis"
2) "mongodb"
3) "mysql"
127.0.0.1:6379> zrange wzset 0 4
1) "redis"
2) "mongodb"
3) "mysql"
127.0.0.1:6379> zrange wzset 0 4 withscores
1) "redis"
2) "0"
3) "mongodb"
4) "2"
5) "mysql"
6) "3"
发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。客户端可以订阅任意数量的频道。
支持的命令: subscribe、publish
127.0.0.1:6379> subscribe redischat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redischat"
3) (integer) 1
1) "message"
2) "redischat"
3) "redis is a great caching technique"
1) "message"
2) "redischat"
3) "redis is nosql db"
// another client
127.0.0.1:6379> publish redischat "redis is a great caching technique"
(integer) 1
127.0.0.1:6379> publish redischat "redis is nosql db"
(integer) 1
四、应用
golang中推荐go-redis和redigo库,其中edgex使用了redigo库,go-redis封装好。
github.com/go-redis/redis/v8
github.com/gomodule/redigo/redis -- redigo应用
// main.go
package main
import (
_ "fmt"
"log"
"time"
"testredis/gredis"
)
const RNETWORK = "tcp"
const RPASSWD = "123456"
const RADDRESS = "172.61.1.240:6379"
const RKEY = "wstring"
func main() {
cli, err := gredis.NewClient(RNETWORK, RADDRESS, RPASSWD)
if err != nil {
log.Fatal(err)
}
defer cli.Close()
log.Println("Client create...")
if _, err = cli.Exists(RKEY); err != nil {
log.Fatal(err)
}
{
log.Println(RKEY + " exists")
data, err := cli.Get(RKEY)
if err != nil {
log.Println(err)
} else {
log.Println("old data: ", data)
}
}
cli.Delete(RKEY)
cli.Set(RKEY, "CHINA", 3600)
data, _ := cli.Get(RKEY)
log.Println("new data: ", data)
time.Sleep(1 * time.Second)
}
// gredis/redis.go
package gredis
import (
_ "encoding/json"
"errors"
"log"
"sync"
"time"
"github.com/gomodule/redigo/redis"
)
var once sync.Once
type Client struct {
Pool *redis.Pool
}
func NewClient(network, address, passwd string) (*Client, error) {
var redisClient Client
once.Do(func() {
redisClient = Client{
Pool: &redis.Pool{
MaxIdle: 10, // Maximum number of idle connections in the pool
MaxActive: 10, // Maximum number of connections allocated by the poll at a given time.
IdleTimeout: 10 * time.Second, // close connection
Dial: func() (redis.Conn, error) {
c, err := redis.Dial(network, address)
if err != nil {
return nil, err
}
if passwd != "" {
if _, err := c.Do("AUTH", passwd); err != nil {
c.Close()
return nil, err
}
}
return c, nil
},
TestOnBorrow: func(c redis.Conn, t time.Time) error {
_, err := c.Do("PING")
return err
},
},
}
})
return &redisClient, nil
}
func (c *Client) Set(key string, data interface{}, time int) (err error) {
conn := c.Pool.Get()
defer conn.Close()
// value, err := json.Marshal(data)
value, ok := data.(string)
if !ok {
return errors.New("Set No string")
}
_, err = conn.Do("SET", key, value)
if err != nil {
return err
}
_, err = conn.Do("EXPIRE", key, time)
if err != nil {
return err
}
return nil
}
func (c *Client) Exists(key string) (bool, error) {
conn := c.Pool.Get()
defer conn.Close()
exists, err := redis.Bool(conn.Do("EXISTS", key))
if err != nil {
log.Println(err)
return false, err
}
return exists, nil
}
func (c *Client) Get(key string) (string, error) {
conn := c.Pool.Get()
defer conn.Close()
reply, err := redis.Bytes(conn.Do("GET", key))
if err != nil {
return "", err
}
return string(reply), nil
}
func (c *Client) Delete(key string) (bool, error) {
conn := c.Pool.Get()
defer conn.Close()
return redis.Bool(conn.Do("DEL", key))
}
func (c *Client) LikeDeletes(key string) error {
conn := c.Pool.Get()
defer conn.Close()
keys, err := redis.Strings(conn.Do("KEYS", "*"+key+"*"))
if err != nil {
return err
}
for _, key := range keys {
_, err = c.Delete(key)
if err != nil {
return err
}
}
return nil
}
func (c *Client) Close() {
c.Pool.Close()
once = sync.Once{}
}
注意: 使用go-redis库时,批量获取redis中的key值,有不存在的key,返回的会是redis.Nil,否则返回的是nil。
五、专题
1. redis的过期策略以及内存淘汰机制
分析:这个问题其实相当重要,到底redis有没用到家,这个问题就可以看出来。比如你redis只能存5G数据,可是你写了10G,那会删5G的数据。怎么删的,这个问题思考过么?还有,你的数据已经设置了过期时间,但是时间到了,内存占用率还是比较高,有思考过原因么?
回答:redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
在redis.conf中有一行配置
# maxmemory-policy allkeys-lru
该配置就是配内存淘汰策略的(什么,你没配过?好好反省一下自己)
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用。
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
2. redis和数据库双写一致性问题
分析:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
回答:首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
// 以下来自极客时间 蒋德钧
针对缓存和数据库不一致的问题,我们可以分成读写缓存和只读缓存两种情况进行分析。对于读写缓存来说,如果我们采用同步写回策略,那么可以保证缓存和数据库中的数据一致。(在业务应用中使用事务机制,来保证缓存和数据库的更新具有原子性,也就是说,两者要不一起更新,要不都不更新,返回错误信息,进行重试。否则,我们就无法实现同步直写。)
只读缓存的情况比较复杂,我总结了一张表,以便于你更加清晰地了解数据不一致的问题原因、现象和应对方案。
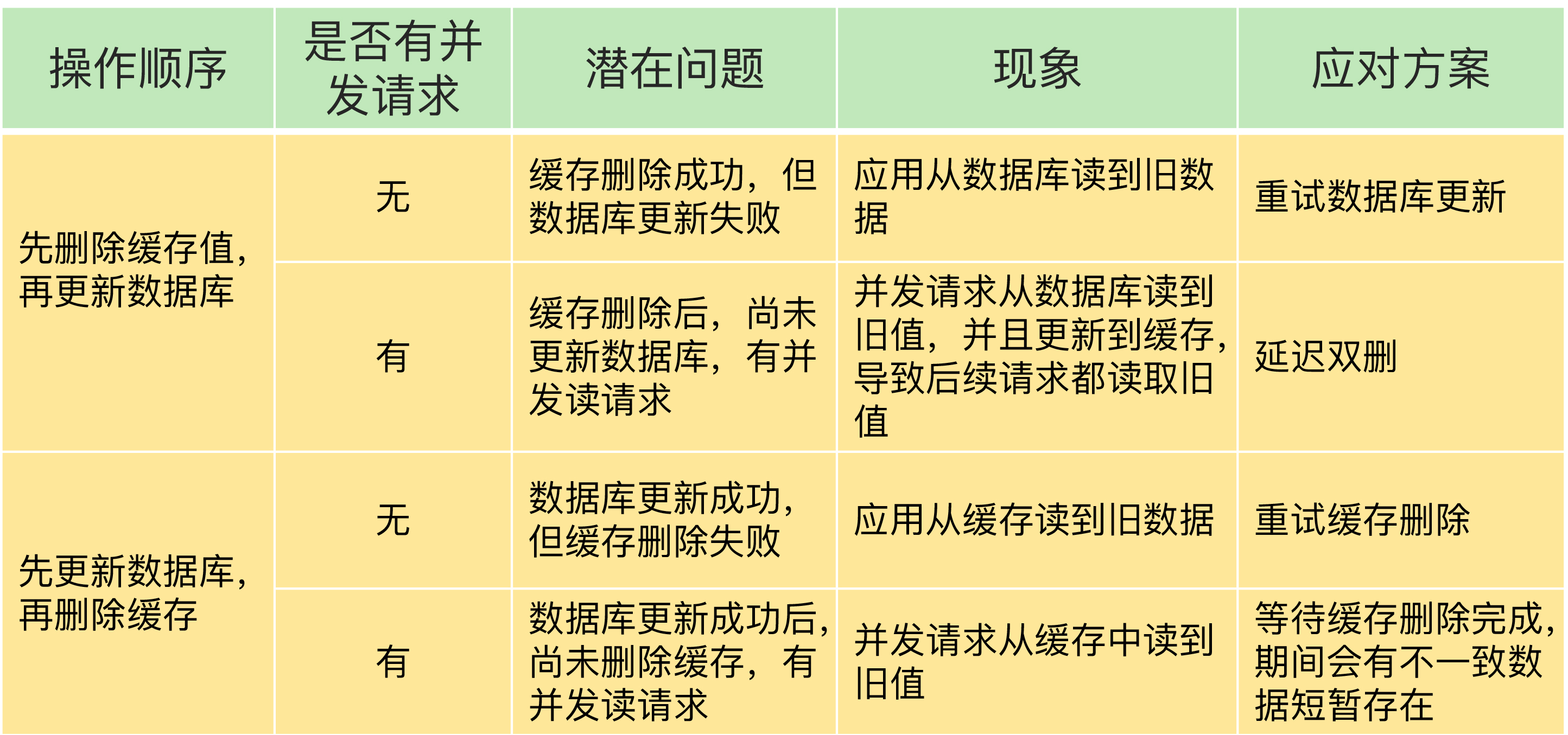
当使用先更新数据库再删除缓存时,也有个地方需要注意,如果业务层要求必须读取一致的数据,那么,我们就需要在更新数据库时,先在 Redis 缓存客户端暂存并发读请求,等数据库更新完、缓存值删除后,再读取数据,从而保证数据一致性。
ali答疑:Mysql 和 Redis 的同步?
一般的方案是监听 mysql 的 binlog 的变动,然后解析出原始数据操作,去 Redis更新数据。
ali答疑:缓存怎么和数据库保持强一致?
首先是很难保证的,应该尽量避免数据不一致。如果出现不一致,要以最可靠的数据库做一个兜底。要避免这个问题,主要是解决缓存在更新的时候。一种方式是只有一个线程写,定时从数据库更新数据到缓存,可以监听数据库 binlog 的修改,更新缓存。另一种方式是业务线程来更新,先持久化再删除缓存,然后读逻辑来更新缓存。缓存一般是要设置过期时间的。
3. 缓存雪崩、缓存击穿、缓存穿透
缓存雪崩:缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。缓存雪崩通常因为缓存服务器宕机、缓存的 key 设置了相同的过期时间等引起。
缓存击穿:一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到 DB ,造成瞬时DB请求量大、压力骤增。
缓存穿透:查询一个不存在的数据,因为不存在则不会写到缓存中,所以每次都会去请求 DB,如果瞬间流量过大,穿透到 DB,导致宕机。
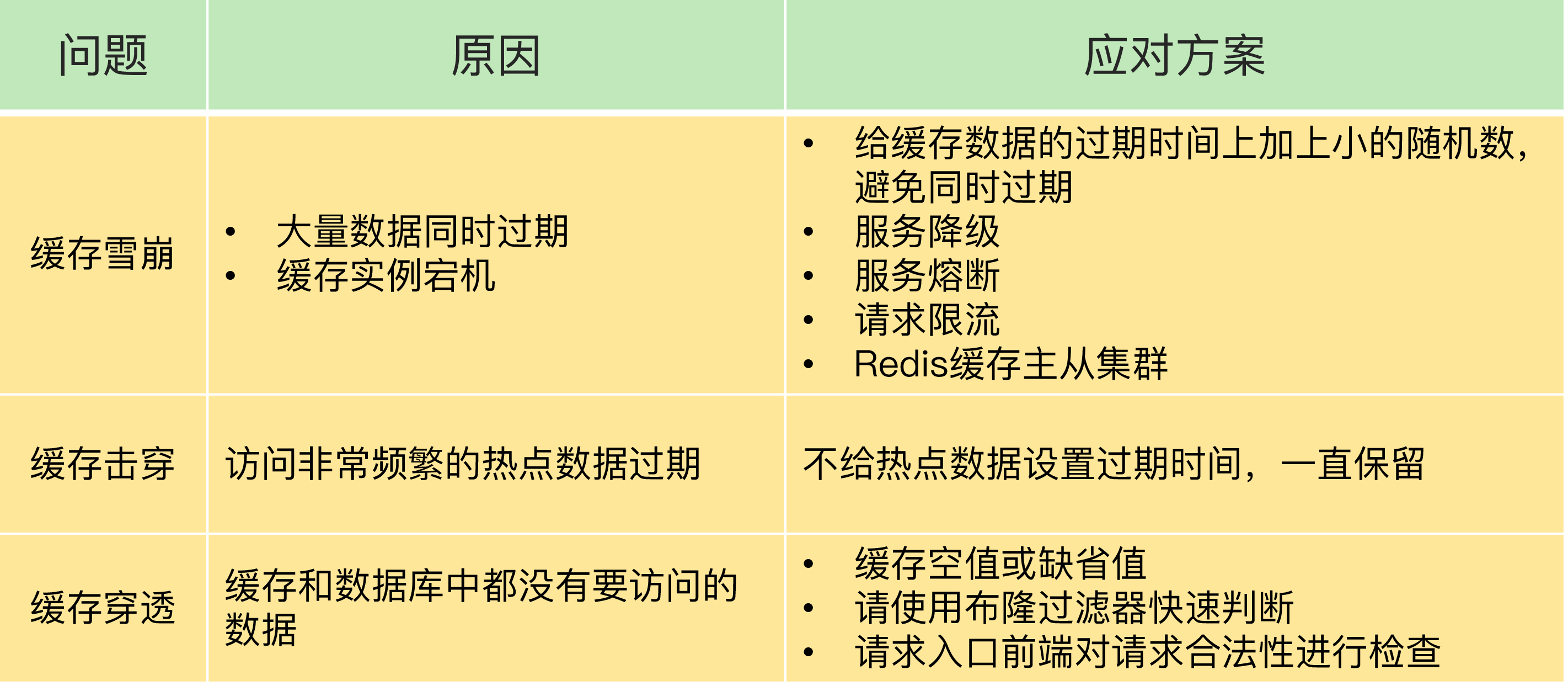
所以,我给你的建议是,尽量使用预防式方案:针对缓存雪崩,合理地设置数据过期时间,以及搭建高可靠缓存集群;针对缓存击穿,在缓存访问非常频繁的热点数据时,不要设置过期时间;针对缓存穿透,提前在入口前端实现恶意请求检测,或者规范数据库的数据删除操作,避免误删除。
4. 分布式锁
- 单个redis节点实现分布式锁
1)只有 key 不存在时,SET 才会创建 key,并对 key 进行赋值;
2)为防止加锁客户端异常,不能释放锁,需设置过期时间。key 的存活时间由 seconds 或者 milliseconds 选项值来决定;PX 10000 则表示 lock_key 会在 10s 后过期
3)unique_value 是客户端的唯一标识(防止不同客户端删除同一把锁),可以用一个随机生成的字符串来表示。在释放锁操作时,我们需要判断锁变量的值,是否等于执行释放锁操作的客户端的唯一标识。
SET key value [EX seconds | PX milliseconds] [NX]
DEL key
// 加锁, unique_value作为客户端唯一性的标识
SET lock_key unique_value NX PX 10000
//释放锁 比较unique_value是否相等,避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
在释放锁操作中,使用了 Lua 脚本,这是因为,释放锁操作的逻辑也包含了读取锁变量、判断值、删除锁变量的多个操作,而 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
- 基于多个 Redis 节点实现高可靠的分布式锁
为了避免 Redis 实例故障而导致的锁无法工作的问题,Redis 的开发者 Antirez 提出了分布式锁算法 Redlock。Redlock 算法的基本思路,是让客户端和多个独立的 Redis 实例依次请求加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁了,否则加锁失败。
Redlock 算法的实现需要有 N 个独立的 Redis 实例。接下来,我们可以分成 3 步来完成加锁操作。
第一步是,客户端获取当前时间。
第二步是,客户端按顺序依次向 N 个 Redis 实例执行加锁操作。
第三步是,一旦客户端完成了和所有 Redis 实例的加锁操作,客户端就要计算整个加锁过程的总耗时。
客户端只有在满足下面的这两个条件时,才能认为是加锁成功。条件一:客户端从超过半数(大于等于 N/2+1)的 Redis 实例上成功获取到了锁;条件二:客户端获取锁的总耗时没有超过锁的有效时间。
5. redis如何应对并发访问
为了保证并发访问的正确性,Redis 提供了两种方法,分别是加锁和原子操作。
为了实现并发控制要求的临界区代码互斥执行,Redis 的原子操作采用了两种方法:
把多个操作在 Redis 中实现成一个操作,也就是单命令操作;
把多个操作写到一个 Lua 脚本中,以原子性方式执行单个 Lua 脚本。
redis-cli --eval lua.script keys , args
6. bigkey
参考:Redis BigKey介绍
在Redis中,一个字符串最大512MB,一个二级数据结构(例如hash、list、set、zset)可以存储大约40亿个(2^32-1)个元素,但实际上中如果下面两种情况,就会认为它是bigkey:
- 字符串类型:它的big体现在单个value值很大,一般认为超过10KB就是bigkey。
- 非字符串类型:哈希、列表、集合、有序集合,它们的big体现在元素个数太多。
危害:内存空间不均匀;超时阻塞;网络拥塞;过期删除;迁移困难。
如何发现:
redis-cli --bigkeys -i 0.1
debug object bigkey
memory usage bigkey
如何删除:
string直接del,其他类型需要hscan、ltrim、sscan、zscan
redis4.0+的话,一条异步删除unlink就可以。
7. 主从备份,读写分离
Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。读操作:主库、从库都可以接收;写操作:首先到主库执行,然后,主库将写操作同步给从库。
主从库模式一旦采用了读写分离,所有数据的修改只会在主库上进行,不用协调三个实例。主库有了最新的数据后,会同步给从库,这样,主从库的数据就是一致的。
主从库间如何进行第一次同步?

主从库同步的基本原理有三种模式:全量复制、基于长连接的命令传播,以及增量复制。
全量复制虽然耗时,但是对于从库来说,如果是第一次同步,全量复制是无法避免的,所以,我给你一个小建议:一个 Redis 实例的数据库不要太大,一个实例大小在几 GB 级别比较合适,这样可以减少 RDB 文件生成、传输和重新加载的开销。另外,为了避免多个从库同时和主库进行全量复制,给主库过大的同步压力,我们也可以采用“主 - 从 - 从”这一级联模式,来缓解主库的压力。
阿里答疑:读写分离实际上是分为分两部分,一部分是访问链路,一部分是数据同步。数据同步:基本的主备同步的过程中,如果读副本的个数比较多的话,采用链式负责任的方式,这样可以降低主节点的压力。访问链路:在开通了读写分离方式后,会有一个 proxy 做代理,有 proxy 去区分用户发送来的命令,判断读请求还是写请求,写请求会转发到主节点处理,读请求会按一定的比例分发到其他的只读节点上。
8. 切片集群
Q:单实例和集群有对应 QPS的参考值吗?
A:简单命令参考:纯社区版 在 10W 左右 可以选择单实例,如果超过了建议使用集群版。阿里云简单的命令上限能到20W 左右。
从 3.0 开始,官方提供了一个名为 Redis Cluster 的方案,用于实现切片集群。Redis Cluster 方案中就规定了数据和实例的对应规则。具体来说,Redis Cluster 方案采用哈希槽(Hash Slot,接下来我会直接称之为 Slot),来处理数据和实例之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。
具体的映射过程分为两大步:首先根据键值对的 key,按照CRC16 算法计算一个 16 bit 的值;然后,再用这个 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
我们在部署 Redis Cluster 方案时,可以使用 cluster create 命令创建集群,此时,Redis 会自动把这些槽平均分布在集群实例上。例如,如果集群中有 N 个实例,那么,每个实例上的槽个数为 16384/N 个。
9. aliyun产品线
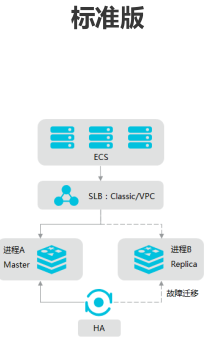
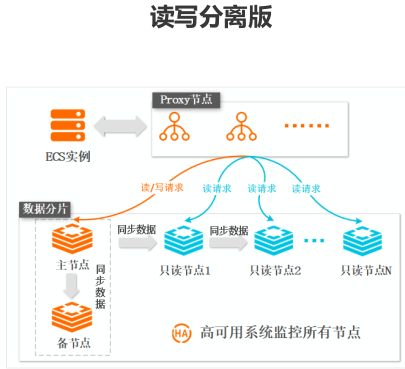
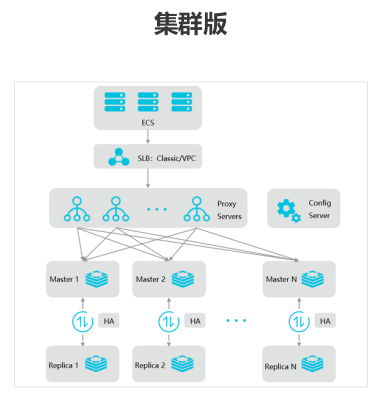
参考:
1 Redis 教程 runoob
4 用 Go 来了解一下 Redis 通讯协议 煎鱼 ---- 通讯协议 ---- 原英文
5 golang中使用redis 简书 推荐go-redis和redigo库
9.初学Redis(2)——用Redis作为Mysql数据库的缓存
10.【Redis数据结构 String类型】String类型生产中的应用 缓存、计数器、限速器的实现
11.难道程序员只把Redis当缓存?3大场景助你完美收割Redis实战开发

 浙公网安备 33010602011771号
浙公网安备 33010602011771号