
BUAA OO 第三单元总结
综述
本单元的主要任务是实现简单社交关系网络的模拟和查询,主要考察基于JML规格的理解和代码实现,一些基本算法的掌握以及程序性能与正确性的测试考量。三次作业的任务相仿,均是基于JML规格实现相应接口的方法,并分别掌握一个基本算法,分别为并查集算法、最小生成树算法和最短路径算法。通过三次作业的开发,我更加理解了JML规格约束对程序实现正确性的重要作用,能够通过阅读JML方法规格的前后置条件语句确定该方法的基本功能与实现,以及对特定功能时间复杂度的优化把握更加清晰。
一、自测过程基于JML规格的测试数据准备
在基于JML规格准备测试数据时,我主要是针对JML规格中的条件拆分,如
对某一JML方法规格中存在多个normal_behavior和多个exceptional_behavior,根据它们分别需要触发的条件构造相应数据
寻找JML方法规格的后置条件中含有推理操作符”==>”的JML表达式,其中蕴含了多种实现情况。如第十一次作业中sendMessage方法对RedEnvelopeMessage和EmojiMessage的特殊处理等。
此外,属性的类型规格也不能忽视,如RedEnvelopeMessage中socialvalue == money * 5的规定也需要构造数据进行检验。
在准备测试数据时,对所有通过JML规格进行约束的方法都需要在测试数据中构造指令进行测试,做到测试的全面。同时,针对JML方法规格十分冗长的方法需要额外注意,创造更多的数据以确保正确性。对JML规格中含有多重循环的方法,格外需要注意其性能和时间复杂度的考虑与测试,如queryBlockSum和经典算法函数等。
二、架构设计与图模型构建
1.架构设计
本单元作业的架构实现主要是通过重写已经完成架构设计的一些接口的方法进行的,辅以一些配套的自设方法,整体上架构比较简单与清晰。本单元架构设计的UML类图如下。
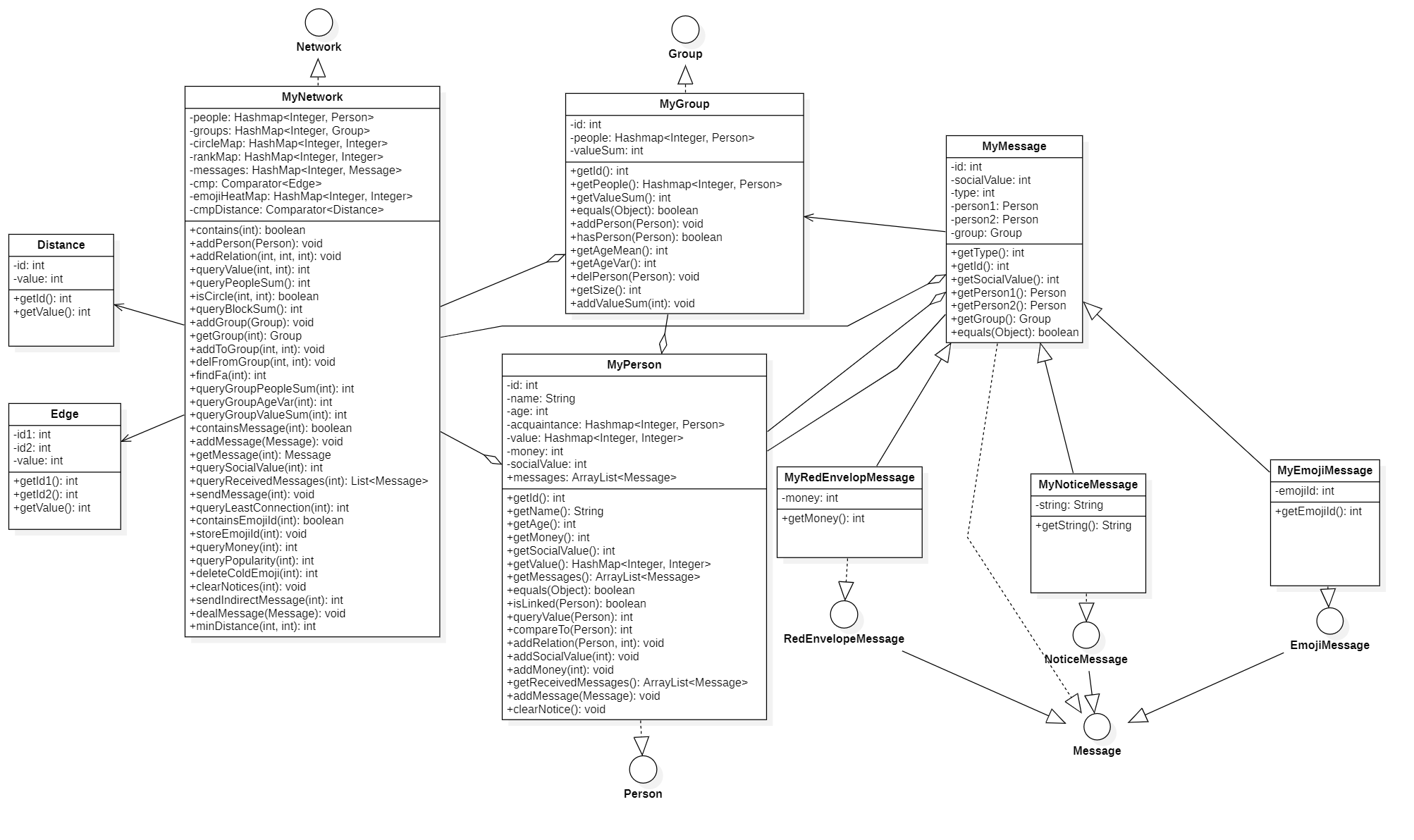
2.图模型构建
在本单元作业中,一般的方法只需要根据JML的后置条件照猫画虎即可,这样可以构建出一个以Person为节点,Relation为边,Person类中的acquaintance和value构成的类似于带权邻接表所构成的一个基本网络图。但对于一些全局性复杂度高的方法,则需要额外维护图进行运算与处理。本单元我主要是运用了并查集算法、Prim算法和Dijkstra算法,分别实现isCircle、queryBlockSum、queryLeastConnection和sendIndirectMessage。
2.1 并查集实现isCircle与qbs
由JML规格可知,这两个方法的核心在于判断两人之间是否存在联系的可能,转化为路径可达问题。一开始我并不了解并查集算法,就只想着通过广度遍历是否到达来判断路径可达,但由于人与关系的不断添加,这种方法在性能上完全无法保证。经过了解,我使用了按秩合并的并查集算法,并为此维护了根父节点图circleMap与节点秩图rankMap。该算法通过记录某一节点对应的最终根父节点,并通过判断两点对应根父节点是否相同来判断两点是否可达,并使用把沿途的每个节点的父节点都设为根节点和把秩(以该节点为根节点的树的深度)较小者往较大者上合并的方法进行优化。在addPerson时,完成基本操作之外,将自己的根父节点初始化为自己,秩初始化为1。addRelation时,完成基本操作后找到两节点原先的父节点并进行秩的比较,由此完成circleMap和rankMap的更新。该部分代码以及查找根父节点函数代码如下.
//addRelation int x = findFa(id1); int y = findFa(id2); if (rankMap.get(x) <= rankMap.get(y)) { circleMap.put(x, y); } else { circleMap.put(y, x); } if (rankMap.get(x).equals(rankMap.get(y)) && x != y) { rankMap.put(y, rankMap.get(y) + 1); } //findFa public int findFa(int id) { if (id == circleMap.get(id)) { return id; } circleMap.put(id, findFa(circleMap.get(id))); return circleMap.get(id); }
经过这些维护,isCircle和queryBlockSum就只是简单的判断两点的根父节点是否相同的查询工作了,时间复杂度大大降低。
2.2 最小生成树Prim算法实现qlc
Prim算法的基本思想是从连通网中的某一顶点出发,选择与它关联的具有最小权值的边,将其顶点加入到生成树的顶点集合U中。以后每一步从一个顶点在U中,而另一个顶点不在U中的各条边中选择权值最小的边,把它的顶点加入到集合U中。如此继续下去,直到网中的所有顶点都加入到生成树顶点集合U中为止。基于此,维护了一个HashMap连通图节点表用于记录查询节点所在连通图的所有点是否遍历过,以及用一个小顶堆维护一个边集,向边集添加边时,对当前顶点的所有熟人遍历并将两人与权值构成一条边Edge加入到边集中,PriorityQueue小顶堆会自动维护堆的顺序。按照Prim算法的基本思想实现即可,代码如下。
while (fill < chosenPeople.size()) { if (fill == 0) { chosenPeople.put(id, true); fill++; MyPerson person = (MyPerson) getPerson(id); for (Integer key : person.getValue().keySet()) { if (!chosenPeople.get(key)) { heap.add(new Edge(id, key, person.getValue().get(key))); } } } else { Edge edge = heap.poll(); if (edge != null) { while (edge != null && chosenPeople.get(edge.getId1()) && chosenPeople.get(edge.getId2())) { edge = heap.poll(); } } if (edge != null) { sum = sum + edge.getValue(); chosenPeople.put(edge.getId2(), true); fill++; MyPerson person = (MyPerson) getPerson(edge.getId2()); for (Integer key : person.getValue().keySet()) { if (!chosenPeople.get(key)) { heap.add(new Edge(edge.getId2(), key, person.getValue().get(key))); } } } } }
2.3 最短路径算法Dijkstra实现sim
与Prim算法类似,只不过Dijkstra算法的实现需要额外维护一个距离数组并在选定最小边后更新距离数组,如果当前的到达路径的权值小于已经保存的距离,则更新。代码如下。
while (u != fid) { if (ud != null) { MyPerson person = (MyPerson) people.get(u); for (Integer key : person.getValue().keySet()) { int preDistance = person.getValue().get(key) + distanceMap.get(u); int nowDistance = distanceMap.getOrDefault(key, 10000000); if (preDistance < nowDistance && !finish.get(key)) { distanceMap.put(key, preDistance); distance.add(new Distance(key, preDistance)); } } finish.put(u, true); ud = distance.poll(); if (ud != null) { u = ud.getId(); } if (finish.get(u)) { ud = distance.poll(); if (ud != null) { u = ud.getId(); } } } } return distanceMap.get(fid);
三、出现的性能问题和修复情况
1. qbs双重循环的性能问题。这是本单元第一次作业中互测出现的性能问题,由于对JML的本质理解不深刻,以为方法的实现要按照JML规格说的严格去做,因此当时将qbs设计为双重循环结构。这样如果qbs过多且Person过多时,则类似于o(n2)的复杂度显然无法满足性能要求。修复方法为,判断当前图中有多少个连通图的方法只需要判断当前根父节点的个数即可,通过一级循环判断节点id与其根父节点id是否相等并统计个数即可。
2. qgvs的双重循环问题。与qbs类似,只不过这次在自测时就已发现(后面的均是)。修复方法为将valueSum的计算拆到atg,dfg,ar这些操作中。在atg和dfg中,遍历除了目标人的其他人,如果和目标人有关系,则加或减两人之间权值的两倍。在ar中,遍历所有组,若该关系对应二人都在某组,则将该组的valueSum加上两倍的关系权值。
3. qgav的性能问题。若严格按照JML规格设计,则在循环中又套了许多getAgeMean方法,时间复杂度大大加大。修复方法为先调用getAgeMean获取平均值mean,直接使用mean进行运算。
4. 算法的性能问题。修复方法为使用并查集和堆优化的Prim和Dijkstra算法。
四、Network扩展
扩展部分接口和三个方法的JML规格代码如下。
public interface Network { /*@ public instance model non_null int[] productId @ public instance model non_null Product[] products @ public instance model non_null int[] advertiseId @ public instance model non_null int[] adProductId */ /*@ public normal_behavior @ requires contains(producerId) && getPerson(producerId) instanceOf Producer; @ assignable productId, products; @ ensures (\exists int i; 0 <= i && i < productId.length; productId[i] == productId @ && products[i].getId() == productId && products[i].getProducerId == producerId); @ ensures !(\exists int i; 0 <= i && i < \old(productId.length); productId[i] == productId @ && products[i].getId() == productId) ==> (productId.length = \old(productId.length) + 1 @ && productId.length = \old(products.length) + 1); @ ensures (\exists int i; 0 <= i && i < \old(productId.length); productId[i] == productId @ && products[i].getId() == productId) ==> (productId.length = \old(productId.length) @ && productId.length = \old(products.length)); @ ensures (\forall int i; 0 <= i && i < \old(productId.length); @ (\exists int j; 0 <= j && j < productId.length; productId[j] == \old(productId[i]) && @ products[j] == \old(products[i]))); @ also @ public exceptional_behavior @ signals (PersonNotFoundException e) !contains(producerId) || !getPerson(producerId) instanceOf Producer; */ public void produce(int producerId, int productId) throws PersonNotFoundException; public void sendAdvertisement(int advertiserId, int productId) throws PersonNotFoundException; public void setPriority(int customerId) throws PersonNotFoundException; /*@ public normal_behaviour @ requires contains(customerId) && getPerson(customerId) instanceOf Customer; @ assignable products; @ ensures (\forall int i; 0 <= i && i < productId.length; productId[i] == getPerson(customerId).getPriorId @ ==> (products[i].customers.contains(customerId) && products[i].size == \old(products[i].size) + 1 @ && products[i].customers.length == \old(products[i].customers.length) + 1); @ also @ public exceptional_behaviour @ signals (PersonNotFoundException e) !contains(customerId) || !getPerson(customerId) instanceOf Customer; */ public void buy(int customerId) throws PersonNotFoundException; public void sendPurchase(int advertiserId, int producerId) throws PersonNotFoundException; public int getMoney(int productId) throws ProductNotFoundException; /*@ public normal_behaviour @ requires containsProduct(productId); @ assignable \nothing; @ ensures \result.length == 3 && \result.get(0) == getProduct(productId).producerId @ && \result.get(1) == getProduct(productId).advertisers[size - 1] @ && \result.get(2) == getProduct(productId).customers[size - 1]; @ also @ public exceptional_behaviour @ signals (ProductNotFoundException e) !containsProduct(productId); */ public int[] getRoads(int productId) throws ProductNotFoundException; } public interface Product { /*@ public instance model non_null int[] advertisers @ public instance model non_null int[] customers @ public instance model non_null int size @ public instance model non_null int producerId */ public int getMoney(); public int[] getRoads(); public void addElement(int id, int num); }
五、学习体会
本单元的难度相较前两个单元难度低一些,毕竟不像前面两单元需要绕脑子思考架构与时序,这一单元直截了当让我们通过JML规格的约束实现特定的方法。通过这一单元的学习,熟悉了如何利用JML规格提取相关信息进行编写与测试的过程,掌握了如何阅读和编写JML规格。
但更重要的是,我清楚了JML规格的意义。它是为了约束我们方法的实现,确保方法实现的正确性存在的,并不约束我们的具体实现(如容器、算法等)。一开始我以为我就要严格按照JML规格的后置条件的方法去写,结果做得很麻烦,性能也很差。
此外,掌握了一些基本算法的实现以及学会如何通过阅读代码和编写测试数据优化方法的时间复杂度,对测试的理解和方法更加精进了。本单元我也尝试去写可以对拍和查看CPU时间的能够自动产生特定方法数据的评测机,效果不错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号