qemu kvm 虚拟化
虚拟化:
KVM是一个基于Linux内核的虚拟机,属于完全虚拟化。虚拟机监控的实现模型有两类:监控模型(Hypervisor)和宿主机模型(Host-based)。由于监控模型需要进行处理器调度,还需要实现各种驱动程序,以支撑运行其上的虚拟机,因此实现难度上一般要大于宿主机模型。KVM的实现采用宿主机模型(Host-based),KVM是集成在Linux内核中的,因此可以自然地使用Linux内核提供的内存管理、多处理器支持等功能,易于实现,而且还可以随着Linux内核的发展而发展。另外,目前KVM的所有I/O虚拟化工作是借助Qemu完成的. 详见(http://blog.csdn.net/yearn520/article/details/6461047#comments)
Libvirt 库是一种实现 Linux 虚拟化功能的 Linux API, libvirt 本身构建于一种抽象的概念之上。它为受支持的虚拟机监控程序实现的常用功能提供通用的 API。

libvirt 将物理主机称作节点,将来宾操作系统称作域。这里需要注意的是,libvirt(及其应用程序)在宿主 Linux 操作系统(域 0)中运行。

QEMU概述:
目前,qemu支持两种操作模式:
- 全系统仿真模式,此时qemu就相当于一台完整的pc机,用来运行不同的操作系统或调试操作系统的代码。
- 用户态仿真模式。在这种模式下,其他平台的程序(x86平台上运行为arm平台编译的程序),能够进行方便的交叉编译和调试,比如wine。
众所周知,Bochs 是一款可移植的IA-32仿真器,它利用模拟的技术来仿真目标系统,具体来说,将是将目标系统的指令分解,然后模拟分解后的指令以达到同样的效果。这种方法将每一条目标指令分解成多条主机系统的指令,很明显会大大降低仿真的速度。
qemu则是采用动态翻译的技术,先将目标代码翻译成一系列等价的被称为“微操作”(micro-operations)的指令,这样做的好处就是,代码是是按块翻译,按块执行的,不像Bochs翻译一条指令,马上就执行一条指令。将guest binary instructions动态翻译成host binary instructions,之后由host运行翻译后的指令。在qemu-0.9之前的版本都采用dyngen的动态翻译技术,而从qemu-0.10开始的版本开始采用TCG(Tiny Code Generator)的翻译技术。
采用dyngen 动态翻译技术的资料主要有以下两篇文章,是了解动态翻译技术入门的好文章(在后续的分析中,会简单介绍dyngen技术):
- QEMU, a Fast and Portable Dynamic Translator
-
Porting QEMU to Plan 9: QEMU Internals and Port Strategy
TCG动态翻译技术的几个概念:
与dyngen一样,TCG的“function”与qemu的TBs(Translated Block)相对应,即以分支跳转指令结束的代码段。
TCG是qemu的核心,主要实现了以下翻译流程:
guest binary instructions -> TCG IR -> host binary instructions TCG 定义了一组IR(intermediate representation),这些IR大致可以分为以下几类:
- Mov类操作: mov, movi, ...
TCG 动态翻译过程:
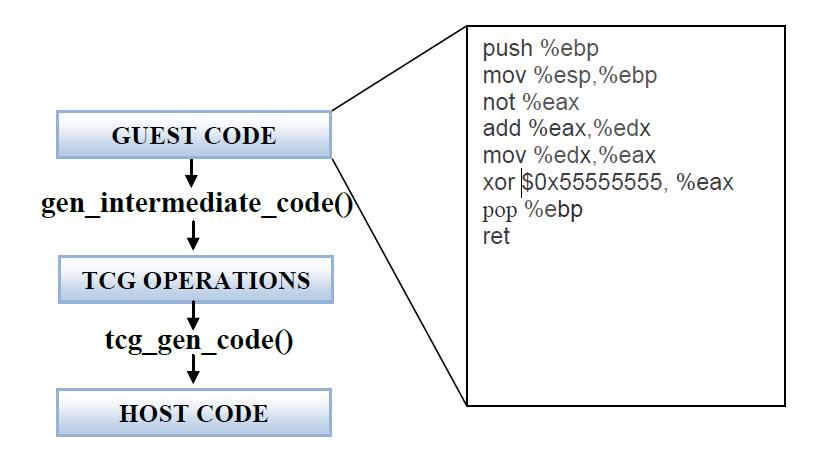
TCG中间代码
主机代码

TB链
在QEMU中,从代码cache到静态代码再回到代码cache,这个过程比较耗时,所以在QEMU中涉及了一个TB链将所有TB连在一起,可以让一个TB执行完以后直接跳到下一个TB,而不用每次都返回到静态代码部分。具体过程如下图:
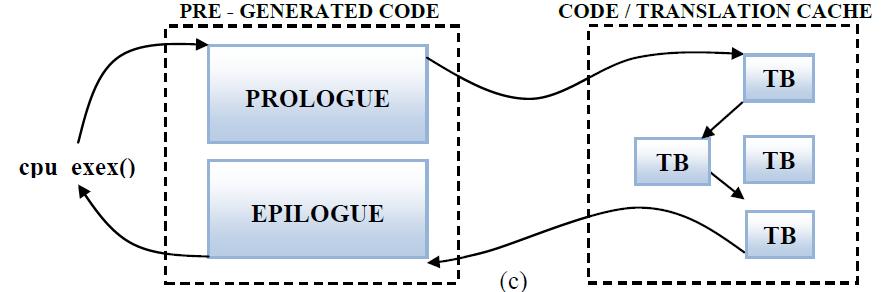
QEMU安装配置:
创建虚拟磁盘:
qemu-img create -f qcow2 -o preallocation=metadata windows.img 3G
安装系统,使用光驱:
qemu -hda windows.img -cdrom /dev/cdrom -boot d
读iso文件:
qemu winxp.img -cdrom deepXP.iso -boot d
启动虚拟机
$ qemu winxp.img -m 1024 -smp 2 -soundhw es1370 -vga std -boot c
其中,-m 1024指分配1G内存,-smp 2指分配两个CPU,-soundhw es1370指加载此类型声卡设备,-vga std指加载此显卡设备。
使用主机上的usb2.0设备, 解决方式是在qemu的启动选项中加上:
-device usb-ehci,id=ehci
启动后通过control-alt-1进入控制台,注意把qemu的控制台重定向到stdin,在启动选项中加入:
-monitor stdio
在qemu控制台查看主机的usb设备:
info usbhost
找到你想要的usb设备。所有usb设备都将列出Bus, Addr, Port和Speed。如果速度在480 Mb/s,那么就需要使用usb2.0连接。假设Bus和Port分别是2和1.6。通过往下命令添加入虚拟机:
device_add usb-host,bus=ehci.0,hostbus=2,hostport=1.6
在虚拟机中添加相应驱动就可以工作了。
用-net nic为虚拟机创建虚拟机网卡。例如,qemu的命令行选项
-net nic,model=pcnet
再查看 #lspci | grep Eth
02:00.0 Ethernet controller: Advanced Micro Devices [AMD] 79c970 [PCnet32 LANCE] (rev 10)
虚拟机的网络设备连接在qemu虚拟的VLAN中。每个qemu的运行实例是宿主机中的一个进程,而每个这样的进程中可以虚拟一些VLAN,虚拟机网络设备接入这些VLAN中。当某个VLAN上连接的网络设备发送数据帧,与它在同一个VLAN中的其它网路设备都能接收到数据帧。上面的例子中对虚拟机的pcnet网卡没有指定其连接的VLAN号,那么qemu默认会将该网卡连入vlan0。
下面这个例子更具一般性:
-net nic,model=pcnet -net nic,model=rtl8139,vlan=1, -net nic,model=ne2k_pci,vlan=1
该命令为虚拟机创建了三块网卡,其中第一块网卡类型是pcnet,连入vlan0;第二块网卡类型是 rtl8139,第三块网卡类型是ne2k_pci,这两块都连入vlan1,所以第二块网卡与第三块网卡可以互相通信,但它们与第一块网卡不能直接通信。
单网卡用户模式:
# qemu-system-x86_64 -m 128 winxp.img -net nic,vlan=0,macaddr=52:54:00:12:342,model=pcnet,addr=08 –net user
---恢复内容开始---
wget http://ftp.nl.debian.org/debian/dists/squeeze/main/installer-armel/20110106+squeeze4+b3/images/versatile/netboot/initrd.gz
wget http://ftp.nl.debian.org/debian/dists/squeeze/main/installer-armel/20110106+squeeze4+b3/images/versatile/netboot/vmlinuz-2.6.32-5-versatile
参考 http://www.cnblogs.com/Akann/archive/2012/01/01/2307804.html
下载下面3个文件
arm嵌入式linux的内核(1.3M0:
http://free-linux.org/upload/arm/vmlinuz-2.6.26-2-versatile
arm嵌入式linux的启动initrd文件(2.1M):
http://free-linux.org/upload/arm/initrd.img-2.6.26-2-versatile
arm嵌入式linux磁盘镜像(368M):
http://free-linux.org/upload/arm/hda.img.bz2(需要解压缩后使用)
3.使用下面的命令引导linux内核和磁盘镜像
linux中执行:
qemu-system-arm -M versatilepb -kernel vmlinuz-2.6.26-2-versatile -hda hda.img -initrd
initrd.img-2.6.26-2-versatile -append "root=/dev/sda1" -m 256
或者下载bash脚本来运行:
http://free-linux.org/upload/arm/arm-linux.sh.gz
(解压缩后需要用chmod +x arm-linux.sh改成可执行的)
windows用户需要把三个文件放到qemu的软件目录中,将qemu-arm.bat的内容换成
qemu-system-arm.exe -M versatilepb -kernel vmlinuz-2.6.26-2-versatile -hda hda.img -initrd
initrd.img-2.6.26-2-versatile -append "root=/dev/sda1" -m 256
或者下载bat脚本运行:
http://free-linux.org/upload/arm/arm-linux.bat
4.登录
启动后看到登录提示符,用户名输入root,密码debian。若遇到磁盘无法自检通过可以重新启动一下试试。
---恢复内容结束---
Convert from VMware to QEMU
This is a quick and dirty quide to converting an Vmware disk file (.vmdk) to something usable by QEMU.
Now QEMU cannot use the vmdk file directly, but has a facility in qemu-img to perform the conversion.
qemu-img convert win2kpro.vmdk -O qcow win2kpro.imgThe next step is totally optional but allows to build a snapshot overlay to which all further rights will perform.
qemu-img create -b win2kpro.img -f qcow win2kpro.ovl Formating 'win2kpro.ovl', fmt=qcow, backing_file=win2kpro.img, size=8388608 kBNow win2kpro.ovl should be usable by qemu. I fire it up and am greeting with promising pictures of Windows 2000 booting up, but after about 10 seconds a BSOD which says INACCESSIBLE_BOOT_DEVICE
I tried this with a Linux instance (centos-3) and it works :)After conversion and boot up, kudzu runs and handles the (virtual) hardware differences. Also the sda references in /etc/fstab are now hda, so some massaging of fstab is necessary.
QEMU 源码分析 :
总结和补充:
/vl.c: 最主要的模拟循环,虚拟机机器环境初始化,和CPU的执行。
/target-arch/translate.c 将客户机代码转化成不同架构的TCG操作码。
/tcg/tcg.c 主要的TCG代码。
/tcg/arch/tcg-target.c 将TCG代码转化生成主机代码
/cpu-exec.c 其中的cpu-exec()函数主要寻找下一个TB(翻译代码块),如果没找到就请求得到下一个TB,并且操作生成的代码块。
Target指令 ----> TCG ----> Host指令
TCG成为QEMU新的翻译引擎,全称为“Tiny Code Generator”,和一个真正的编译器后端一样,主要负责分析、优化Target代码以及生成Host代码。
tcg/tcg.c : static inline void tcg_out8(TCGContext *s, uint8_t v) { ... }
tcg/i386/tcg-target.c : static inline void tcg_out_movi(TCGContext *s, TCGType type, int ret, int32_t arg) { if (arg == 0) { /* xor r0,r0 */ tcg_out_modrm(s, 0x01 | (ARITH_XOR << 3), ret, ret); } else { tcg_out8(s, 0xb8 + ret); // 输出操作码,ret是寄存器索引 tcg_out32(s, arg); // 输出操作数 } }
0xb8 - 0xbf 正是x86指令中的 mov R, Iv 系列操作的16进制码,所以,tcg_out_movi 的功能就是输出 mov 操作的指令码到缓冲区中。
可以看出,TCG在生成目标指令的过程中是采用硬编码的,因此,要让TCG运行在不同的Host平台上,就必须为不同的平台编写微指令函数。
以一条Target指令 jmp f000:e05b 来讲述它是如何被翻译成Host指令的。其中几个关键变量的定义如下:
gen_opc_buf:操作码缓冲区
gen_opparam_buf:参数缓冲区
gen_code_buf:存放翻译后指令的缓冲区
gen_opc_ptr、gen_opparam_ptr、gen_code_ptr三个指针变量分别指向上述缓冲区。
jmp f000:e05b 的编码是:EA 5B E0 00 F0,首先是disas_insn()函数翻译指令,当碰到第1个字节EA,分析可知这是一条16位无条件跳转指令,
像上面说的jmp f000:e05b指令,它分解为如下微操作:
gen_op_movl_T0_im(selector);
gen_op_movl_T1_imu(offset);
gen_op_movl_seg_T0_vm(R_CS);
gen_op_movl_T0_T1();
gen_op_jmp_T0();
这几条微操作的意义概括起来很简单,就是把selector放到env.cs,把offset放到env.eip。
1 这几个微指令函数的定义如下(功能可看注释): 2 3 static inline void gen_op_movl_T0_im(int32_t val) 4 { 5 tcg_gen_movi_tl(cpu_T[0], val); // 相当于 cpu_T[0] = val 6 } 7 8 static inline void gen_op_movl_T1_imu(uint32_t val) 9 { 10 tcg_gen_movi_tl(cpu_T[1], val); // 相当于 cpu_T[1] = val 11 } 12 13 static inline void gen_op_movl_seg_T0_vm(int seg_reg) 14 { 15 tcg_gen_andi_tl(cpu_T[0], cpu_T[0], 0xffff); // cpu_T[0] = cpu_T[0]&0xffff 16 tcg_gen_st32_tl(cpu_T[0], cpu_env, 17 offsetof(CPUX86State,segs[seg_reg].selector)); // the value of cpu_T[0] store to the 'offset' of cpu_env 18 tcg_gen_shli_tl(cpu_T[0], cpu_T[0], 4); // cpu_T[0] = cpu_T[0]<<4 19 tcg_gen_st_tl(cpu_T[0], cpu_env, 20 offsetof(CPUX86State,segs[seg_reg].base)); // the value of cpu_T[0] store to the 'offset' of cpu_env 21 } 22 23 static inline void gen_op_movl_T0_T1(void) 24 { 25 tcg_gen_mov_tl(cpu_T[0], cpu_T[1]); // cpu_T[0] = cpu_T[1] 26 } 27 28 static inline void gen_op_jmp_T0(void) 29 { 30 tcg_gen_st_tl(cpu_T[0], cpu_env, offsetof(CPUState, eip)); // // the value of cpu_T[0] store to the 'offset' of cpu_env 31 } 32 33 其中,cpu_T[0]、cpu_T[1]和前面讲过的T0、T1功能一样,都是用来临时存储的变量。在32位目标机上,tcg_gen_movi_tl 就是 tcg_gen_op2i_i32 函数,它的定义如下: 34 tcg/tcg-op.h:2921: #define tcg_gen_movi_tl tcg_gen_movi_i32
35 static inline void tcg_gen_op2i_i32(int opc, TCGv_i32 arg1, TCGArg arg2) 36 { 37 *gen_opc_ptr++ = opc; 38 *gen_opparam_ptr++ = GET_TCGV_I32(arg1); 39 *gen_opparam_ptr++ = arg2; 40 } 41 42 static inline void tcg_gen_movi_i32(TCGv_i32 ret, int32_t arg) 43 { 44 tcg_gen_op2i_i32(INDEX_op_movi_i32, ret, arg); 45 } 46 47 gen_opparam_buf 是用来存放操作数的缓冲区,它的存放顺序是:第1个4字节代表s->temps(用来存放目标值的数组,即输出参数)的索引,
第2个4字节及之后字节代表输入参数,对它的具体解析过程可见 tcg_reg_alloc_movi 函数,示例代码如下: 48 49 TCGTemp *ots; 50 tcg_target_ulong val; 51 52 ots = &s->temps[args[0]]; 53 val = args[1]; 54 55 ots->val_type = TEMP_VAL_CONST; 56 ots->val = val; // 把输入值暂时存放在ots结构中
jmp f000:e05b 生成的最终指令如下:
099D0040 B8 00 F0 00 00 mov eax,0F000h 099D0045 81 E0 FF FF 00 00 and eax,0FFFFh 099D004B 89 45 50 mov dword ptr [ebp+50h],eax 099D004E C1 E0 04 shl eax,4 099D0051 89 45 54 mov dword ptr [ebp+54h],eax 099D0054 B8 5B E0 00 00 mov eax,0E05Bh 099D0059 89 45 20 mov dword ptr [ebp+20h],eax 099D005C 31 C0 xor eax,eax 099D005E E9 25 5D CA 06 jmp _code_gen_prologue+8 (10675D88h) /* 返回 */
从上面可以看出,生成的Host代码很简洁,对于Target机的JMP,Host没有去执行真正的跳转指令,而只是简单的将目标地址放到EIP中而已。
QEMU维护着一个称为 CPUState 的数据结构,这个结构包括了Target机CPU的所有寄存器,像EAX,EBP,ESP,CS,EIP,EFLAGS等。
它总是代表着Target机的当前状态,用env变量来表示 CPUState 结构,QEMU每次解析Target指令时,总是以 env.cs+env.eip 为开始地址的。
QEMU的TCG代码分析
接下来来看看QEMU代码中中到底怎么来执行这个TCG的,看看它是如何生成主机代码的。
main_loop(...){/vl.c} :
函数main_loop 初始化qemu_main_loop_start()然后进入无限循环cpu_exec_all() , 这个是QEMU的一个主要循环,在里面会不断的判断一些条件,如虚拟机的关机断电之类的。
qemu_main_loop_start(...){/cpus.c} :
函数设置系统变量 qemu_system_ready = 1并且重启所有的线程并且等待一个条件变量。
cpu_exec_all(...){/cpus.c} :
它是cpu循环,QEMU能够启动256个cpu核,但是这些核将会分时运行,然后执行qemu_cpu_exec() 。
struct CPUState{/target-xyz/cpu.h} :
它是CPU状态结构体,关于cpu的各种状态,不同架构下面还有不同。
cpu_exec(...){/cpu-exec.c}:
这个函数是主要的执行循环,这里第一次翻译之前说道德TB,TB被初始化为(TranslationBlock *tb) ,然后不停的执行异常处理。其中嵌套了两个无限循环 find tb_find_fast() 和tcg_qemu_tb_exec().
cantb_find_fast()为客户机初始化查询下一个TB,并且生成主机代码。
tcg_qemu_tb_exec()执行生成的主机代码
struct TranslationBlock {/exec-all.h}:
结构体TranslationBlock包含下面的成员:PC, CS_BASE, Flags (表明TB), tc_ptr (指向这个TB翻译代码的指针), tb_next_offset[2], tb_jmp_offset[2] (接下去的Tb), *jmp_next[2], *jmp_first (之前的TB).
tb_find_fast(...){/cpu-exec.c} :
函数通过调用获得程序指针计数器,然后传到一个哈希函数从 tb_jmp_cache[] (一个哈希表)得到TB的所以,所以使用tb_jmp_cache可以找到下一个TB。如果没有找到下一个TB,则使用tb_find_slow。
tb_find_slow(...){/cpu-exec.c}:
这个是在快速查找失败以后试图去访问物理内存,寻找TB。
tb_gen_code(...){/exec.c}:
开始分配一个新的TB,TB的PC是刚刚从CPUstate里面通过using get_page_addr_code()找到的
phys_pc = get_page_addr_code(env, pc);
tb = tb_alloc(pc);
ph当调用cpu_gen_code() 以后,接着会调用tb_link_page(),它将增加一个新的TB,并且指向它的物理页表。
cpu_gen_code(...){translate-all.c}:
函数初始化真正的代码生成,在这个函数里面有下面的函数调用:
gen_intermediate_code(){/target-arch/translate.c}->gen_intermediate_code_internal(){/target-arch/translate.c }->disas_insn(){/target-arch/translate.c}
disas_insn(){/target-arch/translate.c}
函数disas_insn() 真正的实现将客户机代码翻译成TCG代码,它通过一长串的switch case,将不同的指令做不同的翻译,最后调用tcg_gen_code。
tcg_gen_code(...){/tcg/tcg.c}:
这个函数将TCG的代码转化成主机代码,这个就不细细说明了,和前面类似。
#define tcg_qemu_tb_exec(...){/tcg/tcg.g}:
通过上面的步骤,当TB生成以后就通过这个函数进行执行.
next_tb = tcg_qemu_tb_exec(tc_ptr) :
extern uint8_t code_gen_prologue[];
#define tcg_qemu_tb_exec(tb_ptr) ((long REGPARM(*)(void *)) code_gen_prologue)(tb_ptr)
通过上面的步骤我们就解析了QEMU是如何将客户机代码翻译成主机代码的,了解了TCG的工作原理。
接下来看看QEMU与KVM是怎么联系的, 在QEMU-KVM中,用户空间的QEMU是通过IOCTL与内核空间的KVM模块进行通讯的。
1. 创建KVM
在/vl.c中通过kvm_init()将会创建各种KVM的结构体变量,并且通过IOCTL与已经初始化好的KVM模块进行通讯,创建虚拟机。然后创建VCPU,等等。
2. KVM_RUN
这个IOCTL是使用最频繁的,整个KVM运行就不停在执行这个IOCTL,当KVM需要QEMU处理一些指令和IO等等的时候就会退出通过这个IOCTL退回到QEMU进行处理,不然就会一直在KVM中执行。
它的初始化过程:
vl.c中调用machine->init初始化硬件设备接着调用pc_init_pci,然后再调用pc_init1。
接着通过下面的调用初始化KVM的主循环,以及CPU循环。在CPU循环的过程中不断的执行KVM_RUN与KVM进行交互。
pc_init1->pc_cpus_init->pc_new_cpu->cpu_x86_init->qemu_init_vcpu->kvm_init_vcpu->ap_main_loop->kvm_main_loop_cpu->kvm_cpu_exec->kvm_run
3.KVM_IRQ_LINE
这个IOCTL和KVM_RUN是不同步的,它也是个频率非常高的调用,它就是一般中断设备的中断注入入口。当设备有中断就通过这个IOCTL最终调用KVM里面的kvm_set_irq将中断注入到虚拟的中断控制器。在kvm中会进一步判断属于什么中断类型,然后在合适的时机写入vmcs。当然在KVM_RUN中会不断的同步虚拟中断控制器,来获取需要注入的中断,这些中断包括QEMU和KVM本身的,并在重新进入客户机之前注入中断。
QEMU 代码分析:BIOS 的加载过程: http://www.ibm.com/developerworks/cn/linux/1410_qiaoly_qemubios/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号