论文笔记 — Learning to Collaborate: Multi-Scenario Ranking via Multi-Agent Reinforcement Learning
背景
目前各个场景之间是完全独立优化的,这样会带来几点比较严重的问题:
- 不同场景缺少联动,不用场景策略优化自己的目标而忽略其他场景目标,导致优化到局部最优解;
- 单一场景的独立优化,只使用自己场景的数据,忽略了其他场景的上下文信息;
- 用户在淘宝上购物会经常在多个场景之间切换,例如:从主搜索到猜你喜欢,从猜你喜欢到店铺内。不同场景的商品排序仅考虑自身,会导致用户的购物体验是不连贯或者雷同的。例如:从冰箱的详情页进入店铺,却展示手机;各个场景都展现趋同,都包含太多的U2I(点击或成交过的商品)。
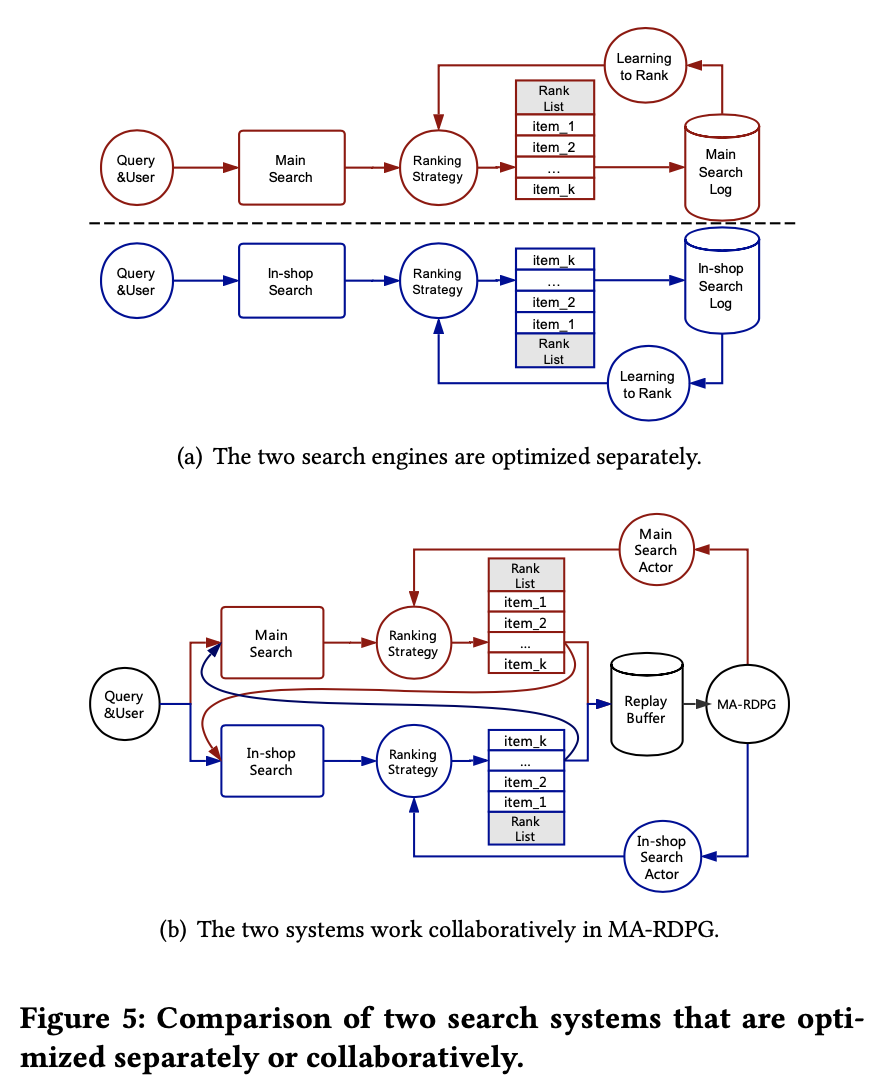
- 多场景之间是博弈(竞争)关系,期望每个场景的提升带来整体提升这一点是无法保证的。很有可能一个场景的提升会导致其他场景的下降,更可怕的是某个场景带来的提升甚至小于其他场景更大的下降。这并非是不可能的,那么这种情况下,单场景的A/B测试就显得没那么有意义,单场景的优化也会存在明显的问题。因为这一点尤为重要,因此我们举一个更简单易懂的例子(如下图)。一个1000米长的沙滩上有2个饮料摊A和B,沙滩上均分分布者很多游客,他们一般会找更近的饮料摊去买饮料。最开始A和B分别在沙滩250米和750米的位置,此时沙滩左边的人会去A买,右边的人去B买。然后A发现,自己往右边移动的时候,会有更多的用户(A/B测试的结论),因此A会右移,同样B会左移。A和B各自‘优化’下去,最后会都在沙滩中间的位置,从博弈论的角度,到了一个均衡点。然而,最后‘优化’得到的位置是不如初始位置的,因为会有很多游客会因为太远而放弃买饮料。这种情况下,2个饮料摊各自优化的结果反而是不如不优化的。
论文思路
本文提出一个多场景联合排序算法,旨在提升整体指标。我们将多场景的排序问题看成一个完全合作的、部分可观测的多智能体序列决策问题,利用Multi-Agent Reinforcement Learning的方法来尝试着对问题进行建模。该模型以各个场景为Agent,让各个场景不同的排序策略共享同一个目标,同时在一个场景的排序结果会考虑该用户在其他场景的行为和反馈。也就是,不同场景不同的action,但是使用相同的critic,目的是保证他们有相同的全局目标。critic网络评价当前场景的状态+action会得到的汇报reward,actor网络彼此之间交换信息,信息是用户的历史行为数据。
这样使得各个场景的排序策略由独立转变为合作与共赢。由于我们想要使用用户在所有场景的行为,而DRQN中的RNN网络可以记住历史信息,同时利用DPG对连续状态与连续动作空间进行探索,因此我们算法取名MA-RDPG(Multi-Agent Recurrent Deterministic Policy Gradient)。
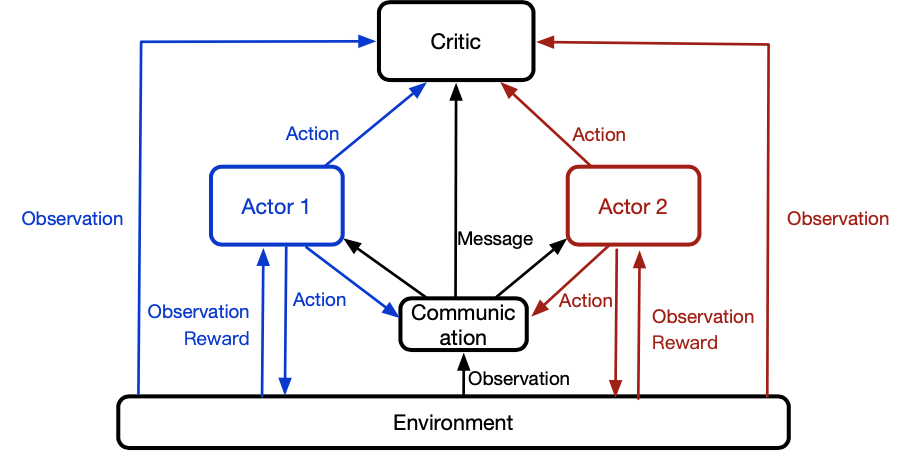
模型结构:
- 不同场景使用不同的actor,输入的信息包括:当前场景、历史场景编码+action。输出当前场景的action;信息共享部分Message,让actor、critic的判断能考虑全局信息;
- 使用相同的critic,目的是全局目标一样;
- 一个场景有一个actor,不同场景的actor相互合作,优化相同的目标;
模型结构
全场景合作,部分观察,多actor的序列决策问题。
- multi-agent:一个系统中的不同场景使用不同的策略,每个actor表示一种策略,学习自己的公式映射,场景信息到action的映射;
- 序列决策:用户和系统的交互是序列化的,因此action也是序列化的。每一步,actor都会选择一个action通过影响list排序来和用户进行交互;
- 全场景合作:所有的actor相互合作,最大化同一个目标。actor之间相互交换信息,并且使用同一个critic进行评估;
- 部分观察:环境是部分观察的,每个actor只观察自己场景下的信息,而不是所有场景下的;

- critic:衡量当前的动作会产生的未来收益,输入是:actor预估的action、当前环境的观察信息、之前的观察信息;
- actor:输出action,输入是:当前的观察信息、之前的观察信息;
- 之前的观察信息更新方式:当前的观察信息、当前的action信息;
t 时刻的状态表示: ![]() ,使用lstm后可以近似为:
,使用lstm后可以近似为:![]() ,这里h 是之前观察的行为+action的编码。
,这里h 是之前观察的行为+action的编码。
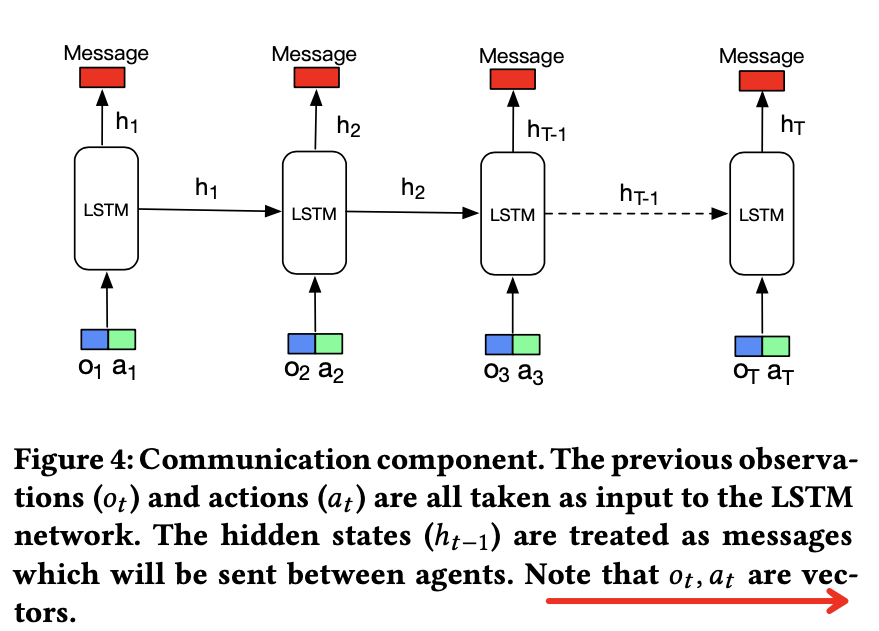
lstm 如下图 :![]() ,这里O包含所有场景的observation,A包含所有场景的action;这样actor就可以获取所有场景下的信息了;
,这里O包含所有场景的observation,A包含所有场景的action;这样actor就可以获取所有场景下的信息了;
critic模型:每次输入的action只有一个会被激活;训练时候的优化公式如下:
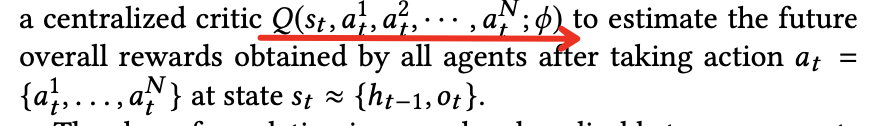
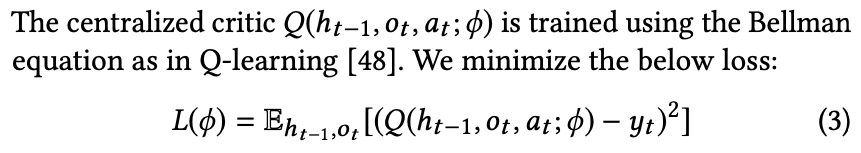

模型应用

参考文献:
https://blog.csdn.net/weixin_33995481/article/details/90063331

 浙公网安备 33010602011771号
浙公网安备 33010602011771号