
已优化列表:
1、部分股票获取分红数据一直失败,每次调用都会重新获取。
1、部分股票获取分红数据一直失败,每次调用都会重新获取。
2、数据全部获取,每次分析目标股票,也需要挨个分析,时间太长
3、报告数量多,挨个打开耗费时间
4、akshare库数据其实是爬虫获取,频繁交互会导致数据处理失败,考虑缓存,以及反爬
最终呈现:
龙头股数据:
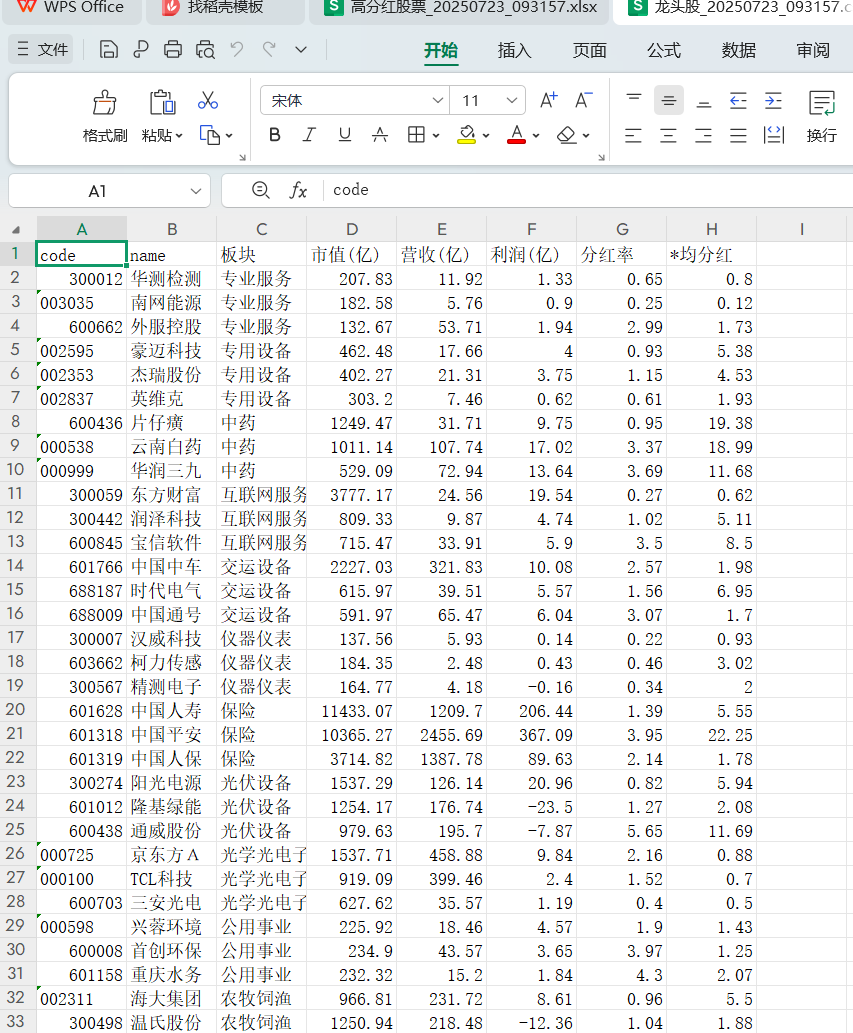
高股息分析结果:
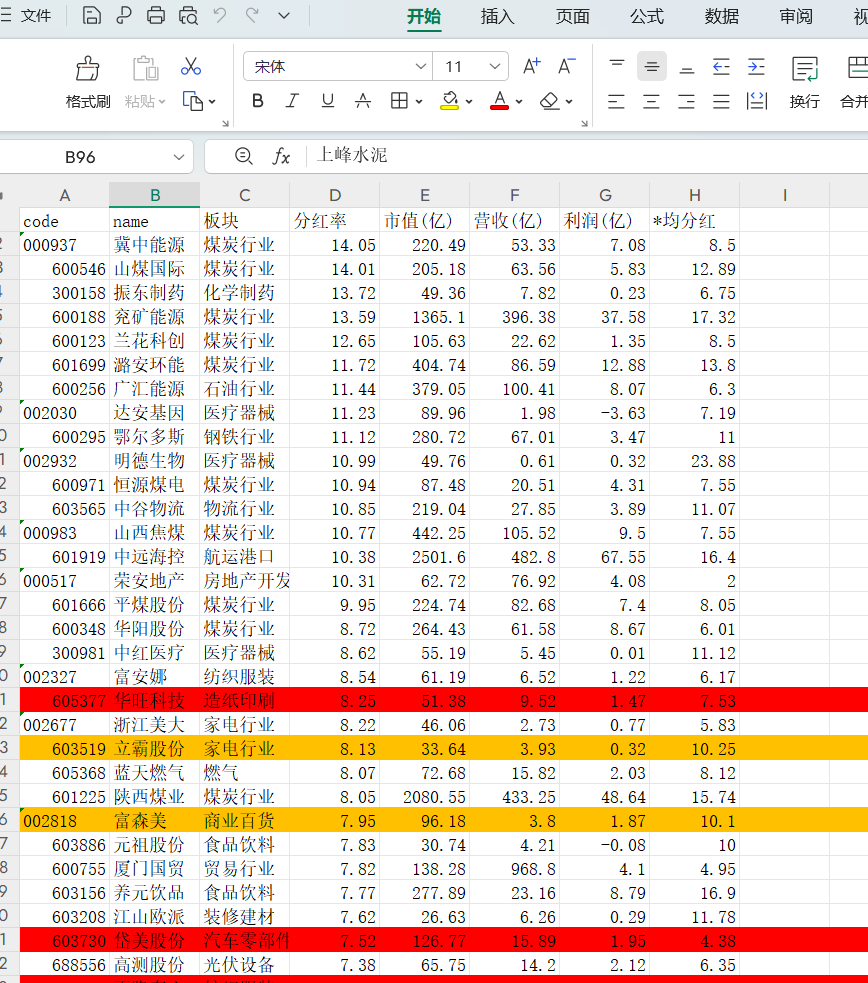
调整完代码:可以直接运行
import akshare as ak
import pandas as pd
import time
import random
from datetime import datetime
import traceback
import numpy as np
import os
def main(enable_high_dividend=True):
"""主流程:先获取全市场分红数据到excel,再分析龙头股和高分红股票"""
try:
print("="*50)
print("开始执行股票分析脚本")
print(f"当前时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("="*50)
# 步骤1: 获取全市场分红数据到excel
print("\n[步骤1/6] 获取全市场分红数据到excel...")
get_dividend_data_for_codes() # 注释掉此步骤时,脚本仍可运行
#print("步骤1已跳过(已注释)")
# 步骤2: 从excel加载分红数据到缓存
print("\n[步骤2/6] 从excel加载分红数据到缓存...")
dividend_cache = load_dividend_cache()
print(f"从缓存加载到 {len(dividend_cache)} 只股票分红数据")
# 步骤3: 获取股票基本信息
print("\n[步骤3/6] 获取股票基本信息...")
stock_basic_df = get_stock_basic_info()
print(f"获取到 {len(stock_basic_df)} 只股票基本信息")
# 步骤4: 获取财务数据
print("\n[步骤4/6] 获取财务数据(市值/营收/利润)...")
financial_df = get_financial_data(stock_basic_df)
# 步骤5: 从excel读取分红数据
print("\n[步骤5/6] 从excel读取分红数据...")
dividend_from_excel = read_dividend_from_excel()
# 步骤6: 数据整合与分析
print("\n[步骤6/6] 数据分析与筛选...")
merged_df = merge_data(stock_basic_df, financial_df, dividend_from_excel)
# 按板块筛选龙头股(不考虑分红率)
top_stocks = []
for industry, group in merged_df.groupby('板块'):
valid_group = group.dropna(subset=['市值(亿)'])
if len(valid_group) == 0:
continue
sorted_group = valid_group.sort_values('市值(亿)', ascending=False)
top_three = sorted_group.head(3)
top_stocks.append(top_three)
if top_stocks:
all_top_stocks = pd.concat(top_stocks).sort_values('板块')
print("\n" + "="*50)
print(f"各板块龙头股分析完成,共筛选出 {len(all_top_stocks)} 只龙头股")
print("="*50 + "\n")
print_top_stocks(all_top_stocks)
# 保存龙头股分析报告到文件
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
top_file = f"龙头股_{timestamp}.csv"
output_columns = ['code', 'name', '板块', '市值(亿)', '营收(亿)', '利润(亿)', '分红率', '*均分红']
all_top_stocks[output_columns].to_csv(top_file, index=False, float_format='%.2f')
print(f"\n龙头股分析报告已保存: {top_file}")
else:
print("未找到龙头股")
# 高分红股票单独输出,放到最后
if enable_high_dividend:
high_dividend_stocks = merged_df[merged_df['分红率'] > 3]
print(f"其中高分红率股票(>3%)有 {len(high_dividend_stocks)} 只")
print_high_dividend_stocks(high_dividend_stocks)
# 保存高分红股票
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
div_file = f"高分红股票_{timestamp}.csv"
output_columns = ['code', 'name', '板块', '分红率', '市值(亿)', '营收(亿)', '利润(亿)', '*均分红']
high_dividend_stocks[output_columns].to_csv(div_file, index=False, float_format='%.2f')
print(f"高分红股票已保存: {div_file}")
except Exception as e:
print("\n" + "!"*50)
print("脚本执行失败!错误信息:")
print(traceback.format_exc())
print("!"*50)
exit(1)
def get_stock_basic_info():
"""获取股票基本信息:代码、名称、所属行业"""
print(" > 获取A股基本信息...")
stock_info_a = ak.stock_info_a_code_name()
time.sleep(2)
print(" > 获取深股基本信息...")
stock_info_sz = ak.stock_info_sz_name_code()
time.sleep(2)
# 合并沪深两市股票
df = pd.concat([
stock_info_a[['code', 'name']],
stock_info_sz[['A股代码', 'A股简称']].rename(columns={'A股代码': 'code', 'A股简称': 'name'})
]).drop_duplicates('code')
print(" > 获取行业分类信息...")
industry_df = ak.stock_board_industry_name_em()
industry_map = {}
for _, row in industry_df.iterrows():
cons_df = ak.stock_board_industry_cons_em(symbol=row['板块名称'])
for code in cons_df['代码']:
industry_map[code] = row['板块名称']
# 添加行业信息
df['板块'] = df['code'].apply(lambda x: industry_map.get(x))
return df.dropna(subset=['板块'])
def get_financial_data(stock_basic_df):
"""批量获取财务数据:市值、营收、利润"""
print(" > 批量获取市值数据...")
spot_df = ak.stock_zh_a_spot_em()
spot_df = spot_df.rename(columns={'代码': 'code', '总市值': '市值(元)'})
time.sleep(6)
print(" > 批量获取利润表数据...")
lrb_df = ak.stock_lrb_em()
lrb_df = lrb_df.sort_values('公告日期', ascending=False).drop_duplicates('股票代码')
# 兼容不同字段名
if '营业总收入' in lrb_df.columns:
revenue_col = '营业总收入'
elif '营业收入' in lrb_df.columns:
revenue_col = '营业收入'
else:
revenue_col = None
lrb_df = lrb_df.rename(columns={'股票代码': 'code'})
if revenue_col:
lrb_df = lrb_df.rename(columns={revenue_col: '营收(元)'})
lrb_df = lrb_df.rename(columns={'净利润': '利润(元)'})
time.sleep(6)
print(" > 合并财务数据...")
df = stock_basic_df[['code']].copy()
df = df.merge(spot_df, on='code', how='left')
df = df.merge(lrb_df, on='code', how='left')
# 单位统一为“亿”
df['市值(亿)'] = df['市值(元)'] / 1e8
df['营收(亿)'] = df['营收(元)'] / 1e8
df['利润(亿)'] = df['利润(元)'] / 1e8
return df[['code', '市值(亿)', '营收(亿)', '利润(亿)']]
def load_dividend_cache():
"""从Excel文件加载分红数据到缓存"""
cache_file = 'dividend_cache.xlsx'
if not os.path.exists(cache_file):
print(f" > 分红数据缓存文件 {cache_file} 不存在,将创建空缓存")
return {}
try:
df = pd.read_excel(cache_file, dtype={'code': str})
df['code'] = df['code'].astype(str)
# 确保所有列都存在,缺失的列填充0
for col in ['*均分红', '分红率']:
if col not in df.columns:
df[col] = 0
# 转换为字典格式,便于快速查找
cache_dict = {}
for _, row in df.iterrows():
cache_dict[row['code']] = {
'*均分红': row.get('*均分红', 0),
'分红率': row.get('分红率', 0)
}
print(f" > 从Excel加载到 {len(cache_dict)} 只股票的分红数据到缓存")
return cache_dict
except Exception as e:
print(f"从Excel加载分红数据失败: {e}")
return {}
def read_dividend_from_excel():
"""从Excel文件读取分红数据"""
cache_file = 'dividend_cache.xlsx'
if not os.path.exists(cache_file):
print(f"错误:分红数据缓存文件 {cache_file} 不存在。请先运行 get_dividend_data_for_codes 获取数据。")
return pd.DataFrame(columns=['code', '*均分红', '分红率'])
try:
df = pd.read_excel(cache_file, dtype={'code': str})
# 验证并确保数据完整性
df = validate_dividend_data(df)
print(f" > 从Excel读取到 {len(df)} 只股票的分红数据")
return df
except Exception as e:
print(f"从Excel读取分红数据失败: {e}")
return pd.DataFrame(columns=['code', '*均分红', '分红率'])
def validate_dividend_data(df):
"""验证分红数据的完整性,确保所有记录都有完整的字段"""
if df.empty:
return df
# 确保所有必需的列都存在
required_columns = ['code', '*均分红', '分红率']
for col in required_columns:
if col not in df.columns:
df[col] = 0
# 确保所有数值字段都是数值类型
df['*均分红'] = pd.to_numeric(df['*均分红'], errors='coerce').fillna(0)
df['分红率'] = pd.to_numeric(df['分红率'], errors='coerce').fillna(0)
# 确保code字段是字符串类型
df['code'] = df['code'].astype(str)
return df
def get_dividend_data_for_codes(year_start=None, year_end=None):
"""获取全市场A股分红数据到Excel缓存文件,分批处理,支持断续执行"""
import os
cache_file = 'dividend_cache.xlsx'
dividend_data = []
current_year = datetime.now().year
if year_start is None:
year_start = current_year - 3
if year_end is None:
year_end = current_year
# 获取全部A股代码
price_df = ak.stock_zh_a_spot_em()
code_list = list(price_df['代码'].astype(str))
price_map = dict(zip(price_df['代码'], price_df['最新价']))
# 读取缓存
if os.path.exists(cache_file):
cache_df = pd.read_excel(cache_file, dtype={'code': str})
cache_df['code'] = cache_df['code'].astype(str)
else:
cache_df = pd.DataFrame(columns=['code', '*均分红', '分红率'])
cache_map = {row['code']: row for _, row in cache_df.iterrows()}
new_records = []
failed = 0
batch_size = 25 # 每批处理25只股票
total = len(code_list)
call_count = 0 # 调用计数器
print(f" > 开始获取分红数据,A股总数: {total} 区间: {year_start}~{year_end}")
for batch_start in range(0, total, batch_size):
batch_codes = code_list[batch_start:batch_start+batch_size]
print(f"\n==== 处理第 {batch_start+1} ~ {min(batch_start+batch_size, total)} 只股票 ====")
batch_new_records = []
for idx, code_str in enumerate(batch_codes):
print(f"正在处理的股票编号是: {code_str} (全市场第 {batch_start+idx+1}/{total})")
# 优先用缓存,如果表格中有数据则跳过并打印
if code_str in cache_map:
print(f" > 从缓存中找到 {code_str} 的数据,跳过获取")
cache_record = cache_map[code_str]
# 确保缓存数据有完整的字段
dividend_data.append({
'code': code_str,
'*均分红': cache_record.get('*均分红', 0),
'分红率': cache_record.get('分红率', 0)
})
continue
# 检查是否需要间隔60秒(每调用30次)
if call_count > 0 and call_count % 30 == 0:
print(f" > 已调用 {call_count} 次,等待60秒...")
time.sleep(60)
max_retries = 1
retry_count = 0
success = False
while not success and retry_count < max_retries:
try:
# 随机间隔3到5秒
delay = random.uniform(3, 5)
time.sleep(delay)
div_df = ak.stock_history_dividend_detail(symbol=code_str, indicator="分红")
call_count += 1 # 增加调用计数
if div_df.empty:
# 没有分红数据,插入分红为0的记录
record = {
'code': code_str,
'*均分红': 0,
'分红率': 0
}
dividend_data.append(record)
batch_new_records.append(record)
new_records.append(record)
success = True
continue
div_df = div_df[div_df['公告日期'].astype(str).str[:4].astype(int).between(year_start, year_end)]
if not div_df.empty:
div_df['year'] = div_df['公告日期'].astype(str).str[:4].astype(int)
year_sum = div_df.groupby('year')['派息'].sum()
years = list(range(year_start, year_end+1))
year_sum = year_sum.reindex(years, fill_value=0)
avg_div = year_sum.sum() / len(years) / 10
current_price = price_map.get(code_str, 0)
div_rate = (avg_div / current_price * 100) if current_price > 0 else 0
record = {
'code': code_str,
'*均分红': avg_div,
'分红率': div_rate
}
dividend_data.append(record)
batch_new_records.append(record)
new_records.append(record)
success = True
else:
# 指定年份范围内没有分红数据,插入分红为0的记录
record = {
'code': code_str,
'*均分红': 0,
'分红率': 0
}
dividend_data.append(record)
batch_new_records.append(record)
new_records.append(record)
success = True
except Exception as e:
retry_count += 1
error_msg = str(e)[:100]
print(f" {code_str} 分红数据获取失败 ({retry_count}/{max_retries}) 错误: {error_msg}")
if retry_count < max_retries:
# 指数退避策略,避免频繁重试
wait_time = min(30, 2 ** retry_count + random.uniform(1, 5))
print(f" > 等待 {wait_time:.1f} 秒后重试...")
time.sleep(wait_time)
else:
print(f" {code_str} 分红数据获取最终失败,插入分红为0的记录")
# 获取失败时也插入分红为0的记录
record = {
'code': code_str,
'*均分红': 0,
'分红率': 0
}
dividend_data.append(record)
batch_new_records.append(record)
new_records.append(record)
failed += 1
# 失败后额外等待,避免连续失败
time.sleep(random.uniform(5, 10))
# 每25只保存一次
if batch_new_records:
# 确保所有记录都有完整的字段
batch_df = pd.DataFrame(batch_new_records)
# 确保所有必需的列都存在
for col in ['code', '*均分红', '分红率']:
if col not in batch_df.columns:
batch_df[col] = 0
all_df = pd.concat([cache_df, batch_df], ignore_index=True)
all_df.drop_duplicates('code', keep='last', inplace=True)
# 验证并确保数据完整性
all_df = validate_dividend_data(all_df)
all_df.to_excel(cache_file, index=False)
cache_df = all_df
cache_map = {row['code']: row for _, row in cache_df.iterrows()}
print(f" > 本批新分红数据已保存到 {cache_file}")
print(f"---- 本批处理完毕,已处理 {min(batch_start+batch_size, total)}/{total} 只 ----\n")
# 合并新数据并保存缓存
if new_records:
# 确保所有记录都有完整的字段
new_df = pd.DataFrame(new_records)
# 确保所有必需的列都存在
for col in ['code', '*均分红', '分红率']:
if col not in new_df.columns:
new_df[col] = 0
all_df = pd.concat([cache_df, new_df], ignore_index=True)
all_df.drop_duplicates('code', keep='last', inplace=True)
# 验证并确保数据完整性
all_df = validate_dividend_data(all_df)
all_df.to_excel(cache_file, index=False)
print(f" > 新分红数据已追加保存到 {cache_file}")
else:
print(f" > 未有新分红数据写入缓存 {cache_file}")
print(f" > 分红数据获取完成,成功: {len(dividend_data)},失败: {failed}")
# 返回最终的数据框,确保所有记录都有完整字段
final_df = pd.DataFrame(dividend_data)
final_df = validate_dividend_data(final_df)
return final_df
def merge_data(basic_df, financial_df, dividend_df):
"""合并所有数据源"""
merged = basic_df.merge(financial_df, on='code', how='left')
merged = merged.merge(dividend_df, on='code', how='left')
# 处理缺失值
merged['分红率'] = merged['分红率'].fillna(0)
merged['*均分红'] = merged['*均分红'].fillna(0)
# 过滤无效数据
merged = merged.dropna(subset=['市值(亿)', '营收(亿)', '利润(亿)'])
merged = merged[merged['市值(亿)'] > 0] # 排除市值为0的股票
return merged
def get_industry_top_stocks(df):
"""按行业筛选市值前三的龙头股"""
top_stocks = []
for industry, group in df.groupby('板块'):
# 排除无财务数据的股票
valid_group = group.dropna(subset=['市值(亿)'])
if len(valid_group) == 0:
continue
# 按市值降序排序
sorted_group = valid_group.sort_values('市值(亿)', ascending=False)
# 取前三名
top_three = sorted_group.head(3)
top_stocks.append(top_three)
return pd.concat(top_stocks).sort_values('板块')
def print_top_stocks(df):
"""打印龙头股报告"""
print("\n" + "="*50)
print("各板块龙头股报告:")
print("="*50)
for industry, group in df.groupby('板块'):
print(f"\n【{industry}】板块龙头股:")
for _, row in group.iterrows():
print(f" {row['code']} {row['name']} | "
f"市值:{row['市值(亿)']:.1f}亿 | "
f"分红率:{row['分红率']:.2f}% | "
f"营收:{row['营收(亿)']:.1f}亿 | "
f"利润:{row['利润(亿)']:.1f}亿")
def print_high_dividend_stocks(df):
"""打印高分红股票报告"""
if not df.empty:
print("\n" + "="*50)
print("高分红率股票(>3%):")
print("="*50)
for _, row in df.iterrows():
print(f" {row['code']} {row['name']} ({row['板块']}) | "
f"分红率:{row['分红率']:.2f}% | "
f"市值:{row['市值(亿)']:.1f}亿")
else:
print("\n未找到分红率>3%的股票")
def save_results(top_stocks, high_dividend_stocks):
"""保存结果到CSV文件"""
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
top_file = f"龙头股分析_{timestamp}.csv"
div_file = f"高分红股票_{timestamp}.csv"
# 优化输出格式
output_columns = ['code', 'name', '板块', '分红率', '市值(亿)', '营收(亿)', '利润(亿)', '*均分红']
top_stocks[output_columns].to_csv(top_file, index=False, float_format='%.2f')
high_dividend_stocks[output_columns].to_csv(div_file, index=False, float_format='%.2f')
print("\n" + "="*50)
print(f"结果已保存: {top_file}, {div_file}")
print("="*50)
if __name__ == "__main__":
main()
# 如需单独获取分红数据,可取消注释下面这行
# get_dividend_data_for_codes()
叠加分析:
1、超跌股票
2、超跌近底股票
具体内容就不展示了,省得坑害别人~
开开心心每一天,写代码的小熊猫~~
