


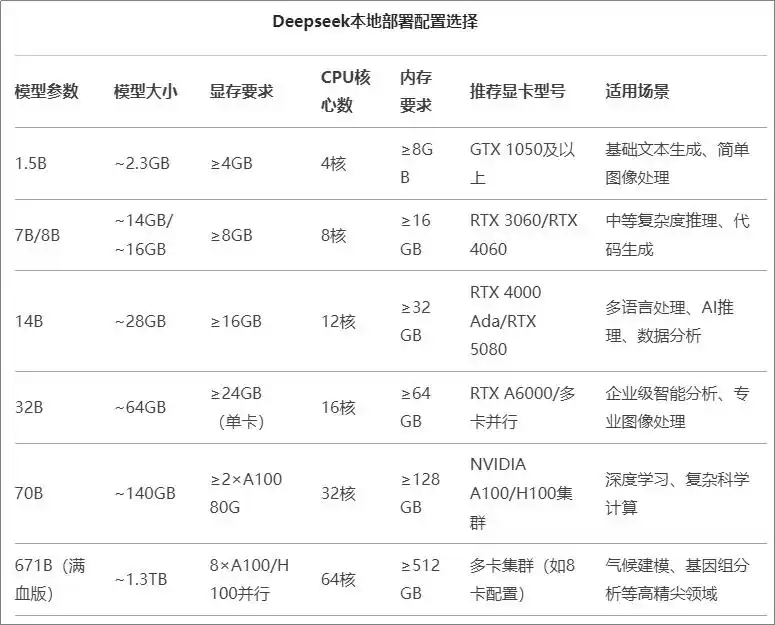
deepseek部署要求:
有无GPU区别:
| 指标 | 有显卡 | 无显卡 |
|---|---|---|
| 推理速度 | 快(10-30 token/s,依赖GPU算力) | 慢(1-5 token/s,依赖CPU核心数) |
| CPU占用率 | 低(10%-30%,主任务为数据预处理) | 高(70%-100%,全计算负载) |
| 内存需求 | 较低(GPU显存承担参数存储) | 较高(需更多RAM或Swap空间) |
| 适用场景 | 实时交互、大批量任务 | 轻量级测试、离线任务或低延迟容忍场景 |
核心原因:
GPU的核心任务
-
并行计算:
GPU专为高并行计算设计,拥有数千个核心(如NVIDIA A100含6912 CUDA核心),擅长处理矩阵乘法、注意力机制等大模型推理中的密集运算。-
示例:1.5B模型的一次前向传播需执行约15亿次浮点操作,GPU可在毫秒级完成,而CPU需数秒。
-
-
显存直接计算:
模型参数和中间数据从RAM加载到GPU显存后,所有计算在显存内部完成,无需CPU干预。
CPU的轻量化角色
-
数据预处理:
-
文本分词、图像归一化、数据格式转换等逻辑控制任务。
-
此类任务通常为串行处理,无法充分利用GPU并行能力。
-
-
任务调度与传输:
-
将预处理后的数据从RAM通过PCIe总线传输至GPU显存(需CPU协调)。
-
管理推理任务的队列和优先级(如多用户请求调度)
-
有GPU的情况下,对内存的占用:
| 场景 | 运行内存(RAM)需求 | 存储内存(硬盘)需求 |
|---|---|---|
| 模型下载 | 无关 | 必须足够(如6GB以上) |
| 推理(未量化) | 约12-18GB(含激活值) | 无关(模型已加载到RAM) |
| 推理(8-bit量化) | 约3-6GB | 量化后模型文件约1.5-3GB |
| 训练 | 极大(需梯度+优化器状态) | 需存储中间checkpoints |
| 组件 | 内存占用计算(以FP32为例) | 1.5B模型示例(FP32) | 作用 |
|---|---|---|---|
| 模型参数 | 参数量 × 4字节 | 1.5B × 4B = 6GB | 模型的 实时计算和推理,GPU也可以直接访问哦 |
| 梯度(Gradients) | 参数量 × 4字节 | +6GB → 累计12GB |
指导模型参数的更新方向 |
| 优化器状态 | Adam优化器:参数量 × 8字节 | +12GB → 累计24GB | 辅助优化算法动态调整参数更新策略,参数更新效率和稳定性 |
| 激活值(Activations) | 依赖模型结构和批次大小,通常为参数的1-3倍 | +6~18GB → **总内存30~42GB** | 引入非线性,赋予模型表达能力 |
写代码的小熊猫,开开心心每一天,耶~
