Clickhouse数据存储结构
前言:Clickhouse是一款列式存储的开源DBMS,以其强悍的单机运算能力著称,最近在工作中接触了这款数据库,对其进行了一些学习,在这里记录下来与大家共同分享交流。
Clickhouse中有众多表引擎,不同的表引擎在底层数据存储上千差万别,在功能和性能上各有侧重。但实际生产中,使用最广泛的表引擎就是MergeTree系列。
MergeTree家族是Clickhouse中最有特色,也是功能最强大的表引擎,实现了数据的partitioning、replication、mutation、merge,以及在merge基础上的replace、aggregation。为了了解这些功能是如何实现的,首先需要知道在MergeTree引擎时,数据文件的组织、存储形式及内容。
数据表的目录组成
clickhouse
└── test_db
├── test_table_a
│ ├── 20210224_0_1_1_2
│ ├── 20210224_3_3_0
│ ├── 20210225_0_1_2_3
│ └── 20210225_4_4_0
└── test_table_b
├── 20210224_0_1_1_2
├── 20210224_3_3_0
├── 20210225_0_1_2_3
└── 20210225_4_4_0
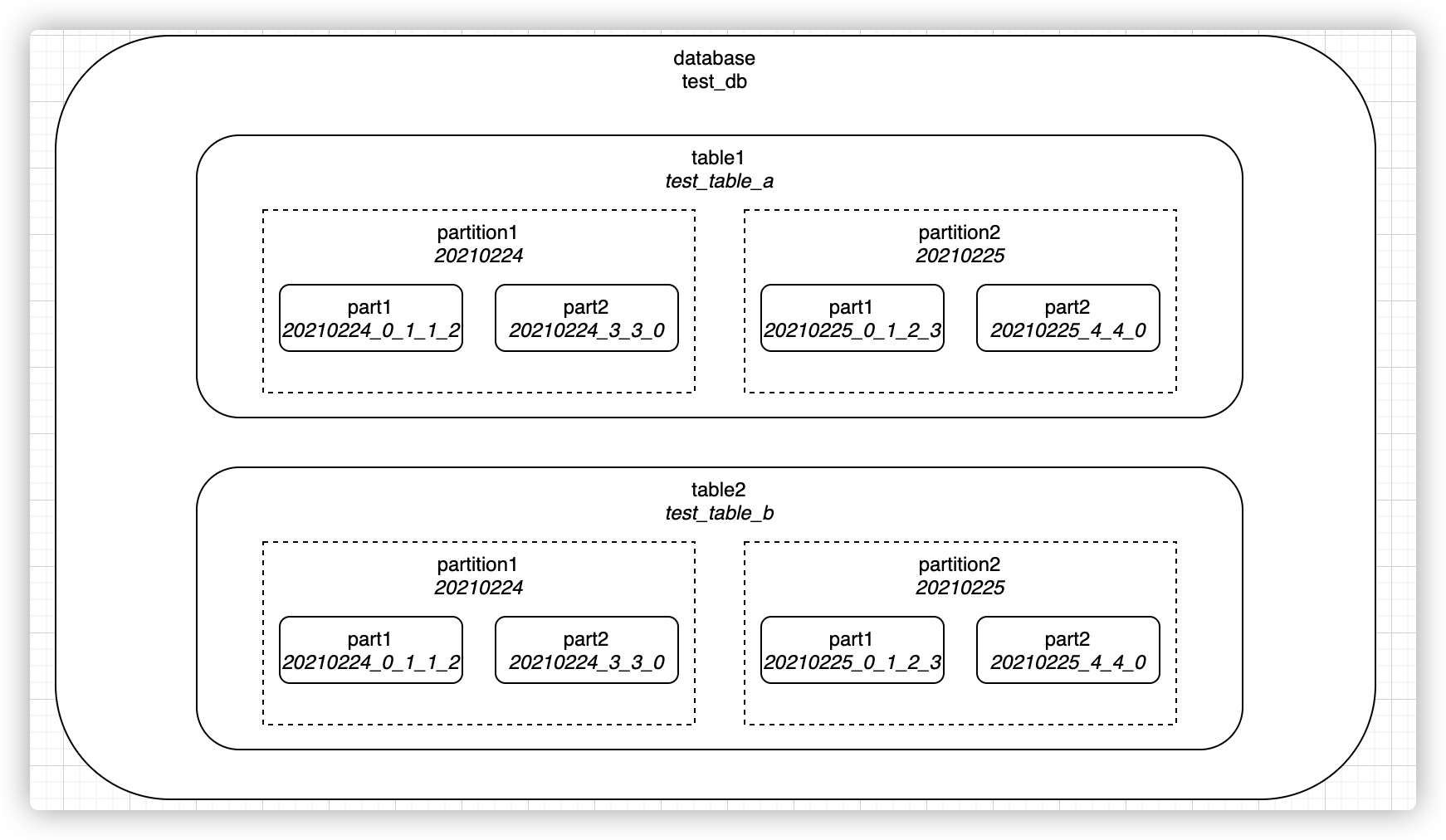
在clickhouse中,一个典型的分区表在文件系统中的目录存储结构如上图所示。库(database)、表(table)、分区(partition)都是按文件目录组织起来的,每个库会有对应的一个库目录,库中的每个表也会有各自对应的表目录。
每张表会包含若干个分区,这里的分区是逻辑概念,并不像库表那样会有目录与之一一对应。在目录形式上,分区实际是一系列part的集合。每张表至少会有一个分区,如果不进行分区配置,则默认为一个all分区。
每个分区是由若干个part组成的,每个part对应一个目录,一般命名格式为{partition}{min_block_number}{level},如果经过mutate操作,则还会有{data_version}的后缀。
在part命名格式{partition}{max_block_number}_{data_version}中:
- partition是分区值
- min_block_number,max_block_number表示这个part包含的最小、最大的block number。每次数据写入都会至少生成一个block,每个block会有自己的block_number
- level表示这个part经过了几次merge,每merge一次会更新生成一个level+1后的part目录
- data_version表示mutate操作的data_version,每一次mutate都会生成一个新的data_version的part目录,这个值的含义其实和block_number类似,同时也和block_number共用自增id空间,通过这个值可以判断每个part是否包含在本次mutate操作的影响范围内
- block_number,level以及mutation在不同的partition中是相互独立的
到这里,我们知道,Clickhouse表中数据是存储在对应表目录下一系列partition parts目录中的,下面就来看看part目录下的数据又是如何组织的。
数据Part目录
用一张具体的表举例:
CREATE TABLE test_benchmark.test_data
(
`id` UInt64,
`prop1` String,
`prop2` String,
`dt` Date,
`update_time` DateTime
) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/{shard}/test_benchmark.test_data', '{replica}', update_time)
PARTITION BY toYYYYMMDD(dt)
ORDER BY id
SETTINGS index_granularity = 8192
视数据量大小,上表的part可能有Wide或Compact两种格式,Compact格式中,所有列的数据都会放在同一个文件中,对小批量数据写入更友好,但经过合并后随着数据增加最终都会用Wide格式存储,这里先以Wide格式为例,上表的一个part目录中的文件有:
-rw-r----- 1 clickhouse clickhouse 655 Jan 27 11:52 checksums.txt
-rw-r----- 1 clickhouse clickhouse 140 Jan 27 11:52 columns.txt
-rw-r----- 1 clickhouse clickhouse 6 Jan 27 11:52 count.txt
-rw-r----- 1 clickhouse clickhouse 10 Jan 27 11:52 default_compression_codec.txt
-rw-r----- 1 clickhouse clickhouse 4 Jan 27 11:52 minmax_dt.idx
-rw-r----- 1 clickhouse clickhouse 4 Jan 27 11:52 partition.dat
-rw-r----- 1 clickhouse clickhouse 304 Jan 27 11:52 primary.idx
-rw-r----- 1 clickhouse clickhouse 2.7K Jan 27 11:52 dt.bin
-rw-r----- 1 clickhouse clickhouse 912 Jan 27 11:52 dt.mrk2
-rw-r----- 1 clickhouse clickhouse 2.3M Jan 27 11:52 id.bin
-rw-r----- 1 clickhouse clickhouse 912 Jan 27 11:52 id.mrk2
-rw-r----- 1 clickhouse clickhouse 1.8M Jan 27 11:52 prop1.bin
-rw-r----- 1 clickhouse clickhouse 912 Jan 27 11:52 prop1.mrk2
-rw-r----- 1 clickhouse clickhouse 1.8M Jan 27 11:52 prop2.bin
-rw-r----- 1 clickhouse clickhouse 912 Jan 27 11:52 prop2.mrk2
-rw-r----- 1 clickhouse clickhouse 1.2M Jan 27 11:52 update_time.bin
-rw-r----- 1 clickhouse clickhouse 912 Jan 27 11:52 update_time.mrk2
part目录的作用是以一种方式将磁盘的数据组织起来,以支持高效的写入和查询,目录中各个文件的作用是:
- checksums.txt:当前目录下各个文件的大小以及各文件内容的hash,用于验证数据是否完整
- columns.txt:此表中所有列以及每列的类型
- count.txt:此part中数据的行数
- default_compression_codec.txt:数据文件的默认压缩算法
- minmax_dt.idx:此表的分区列dt,在这个part中的最大值和最小值
- partition.dat:从分区列计算出分区值的方法
- primary.idx:数据索引,其实是排序键的那一列每间隔index_granularity的值,如果有n列,那每间隔index_granularity就会有n个值,同时也会受index_granularity_bytes影响
- {column_name}.bin:每一列数据的列存文件,存放了实际每一单独列在各行的数值
- {column_name}.mrk2:每一列数据的列存数据标记
上述文件中,列存文件、数据索引和数据标记是最关键的三类部分,是Clickhouse存储和查询数据的核心基础,下面再进一步详细看看这三类文件的内容和作用。
列存文件
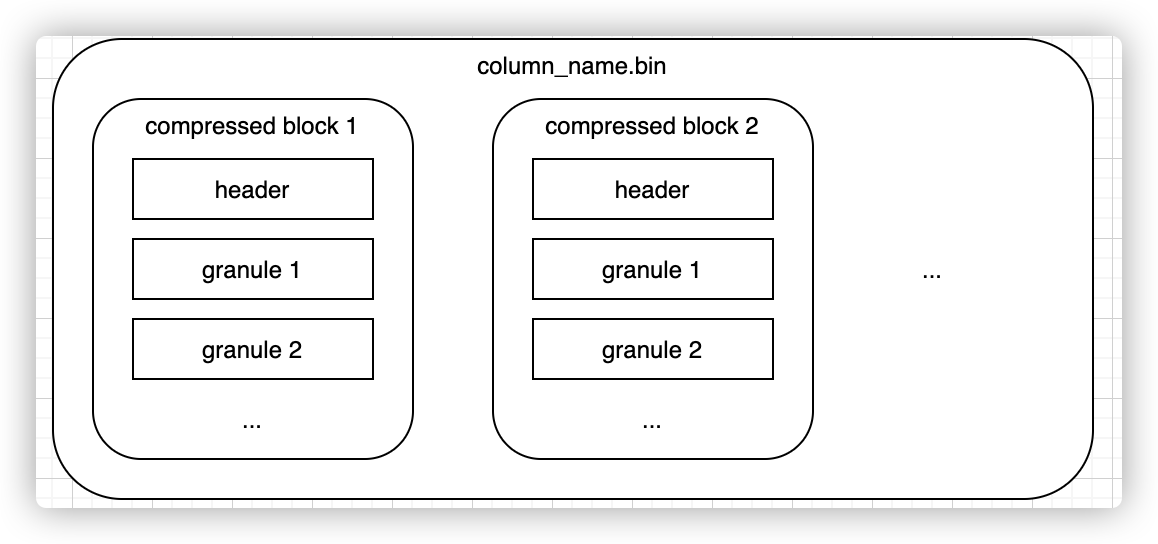
在Part目录下,可以观察到,每一列均有一个单独的列存文件{column_name}.bin来存储实际的数据。为了尽可能减小数据文件大小,文件需要进行压缩,默认算法由part目录下的default_compression_codec文件确定。如果直接将整个文件压缩,则查询时必须读取整个文件进行解压,显然如果需要查询的数据集比较小,这样做的开销就会显得特别大,因此一个列存文件是一个个小的压缩数据块组成的。一个压缩数据块中可以包含若干个granule的数据,而granule就是Clickhouse中最小的查询数据集,后面的索引以及标记也都是围绕granule来实现的。granule的大小由配置项index_granularity确定,默认8192;压缩数据块大小范围由配置max_compress_block_size和min_compress_block_size共同决定。每个压缩块中的header部分会存下这个压缩块的压缩前大小和压缩后大小。整个结构如下图所示:
数据索引文件
在Clickhouse中,数据表中最终的数据是按列存储在Part目录下的各自对应的列存文件下的。那么,查询时应该如何从不同的列存文件中查找到同属于某一行的数据?
有一个前提是,在Clickhouse中,如果使用MergeTree系列的表引擎,则必须指定一个排序键。排序键可以由一列或多列组成,在数据写入磁盘文件中时,数据行的就会按照制定的顺序排列,随后按列拆分写入各个列存文件中。
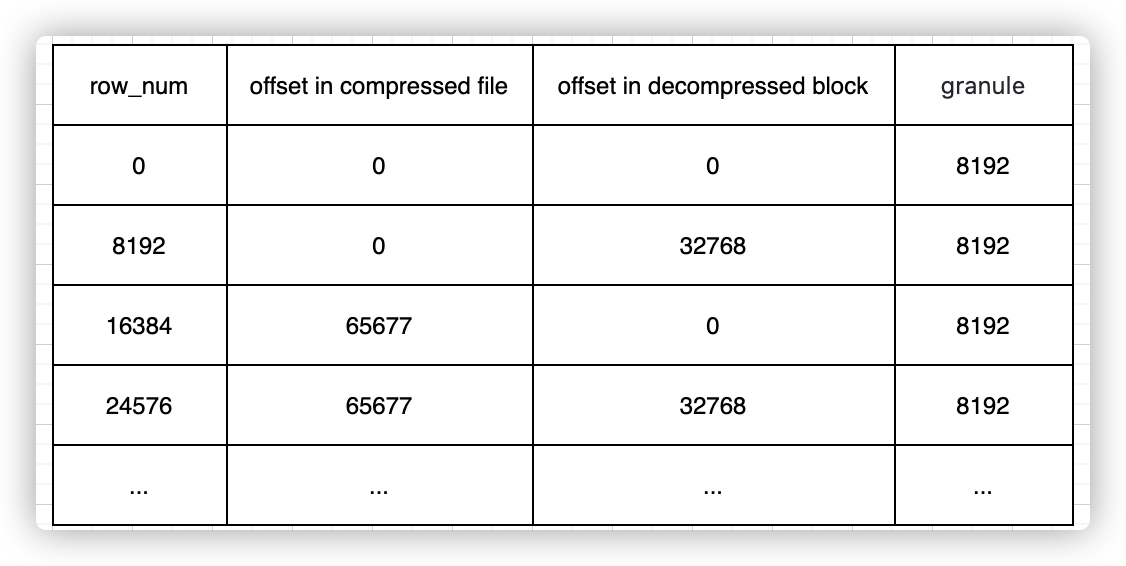
在数据有序的前提下,假设文件不进行任何压缩,则可以通过行号以及每个字段自身所占大小推算出某行号据在文件中的位置。因此,最暴力的方法是根据查询条件到对应列存文件中遍历扫描,查询到对应的数据行号,再由此行号获取其他列存文件在相同行号范围内的数据。显然,如果能够做一个数据 => 行号的索引,则可以在很大程度上提高查询效率,减少文件遍历扫描,这就是数据索引文件(primary.idx)的作用。为了尽量减小索引所占的空间,并且实际上列存文件数据也是按granule组织的,因此可以用稀疏索引的方式建立排序键到行号的对应关系,索引间隙的大小和granule相同,则大致的索引结构就可以描述为下图(和实际的primary.idx文件的内容有些许差异,后文会进一步说明,但用下图可以描述需要达成的作用):

通过上面这样一个索引结构,可以快速查询到指定条件下数据所在行的范围,再通过行号以及各个列的字段长度可以推算出其他列在各自文件中的位置范围。然而实际上,数据在clickhouse中是经过压缩的,且压缩数据正是clickhouse以及其他列存数据库能够达到高性能的原因,极致的压缩能尽可能减少对磁盘的读取。在数据压缩的情况下,各个列每行所占的世纪大小与设定的字段长度并不相同,单靠行号已经无法计算出各列在列存文件中的具体位置,而是还需要各个列单独有自己的一个 行号 => 数据位置的关系。
数据标记文件
在Clickhouse中,每一列的数据都经过某种压缩算法进行压缩。在这种情况下,从数据索引文件查询出数据所在行号后,无法通过行号+字段类型来推算出某行数据的具体位置,为了提高查询性能,Clickhouse设计了数据标记文件,帮助我们更高效地获取到每行数据在列存文件中的具体位置。
上文提到过,列存文件是由一个个压缩数据块组成的,为了查询数据,首先需要定位到数据属于那部分压缩数据块,这里的压缩数据块位置是未解压前的偏移量,找到这个位置后可根据压缩块header中内容将压缩块解压,再通过块内偏移量,就能查到具体的数据。
索引与标记的协同
上文提到,定位一行数据的过程大概是:
- 通过索引文件查到对应的行号范围
- 通过行号在数据标记文件中查到数据在列存文件中的偏移
索引文件和标记文件实际是一对多的关系(主键只有一个,但列有很多),将索引文件和标记文件剥离后,索引文件大小比较小,可以常驻内存。查询到数据范围后,可以直接计算出数据对应在标记文件中的位置,做最小化查询。
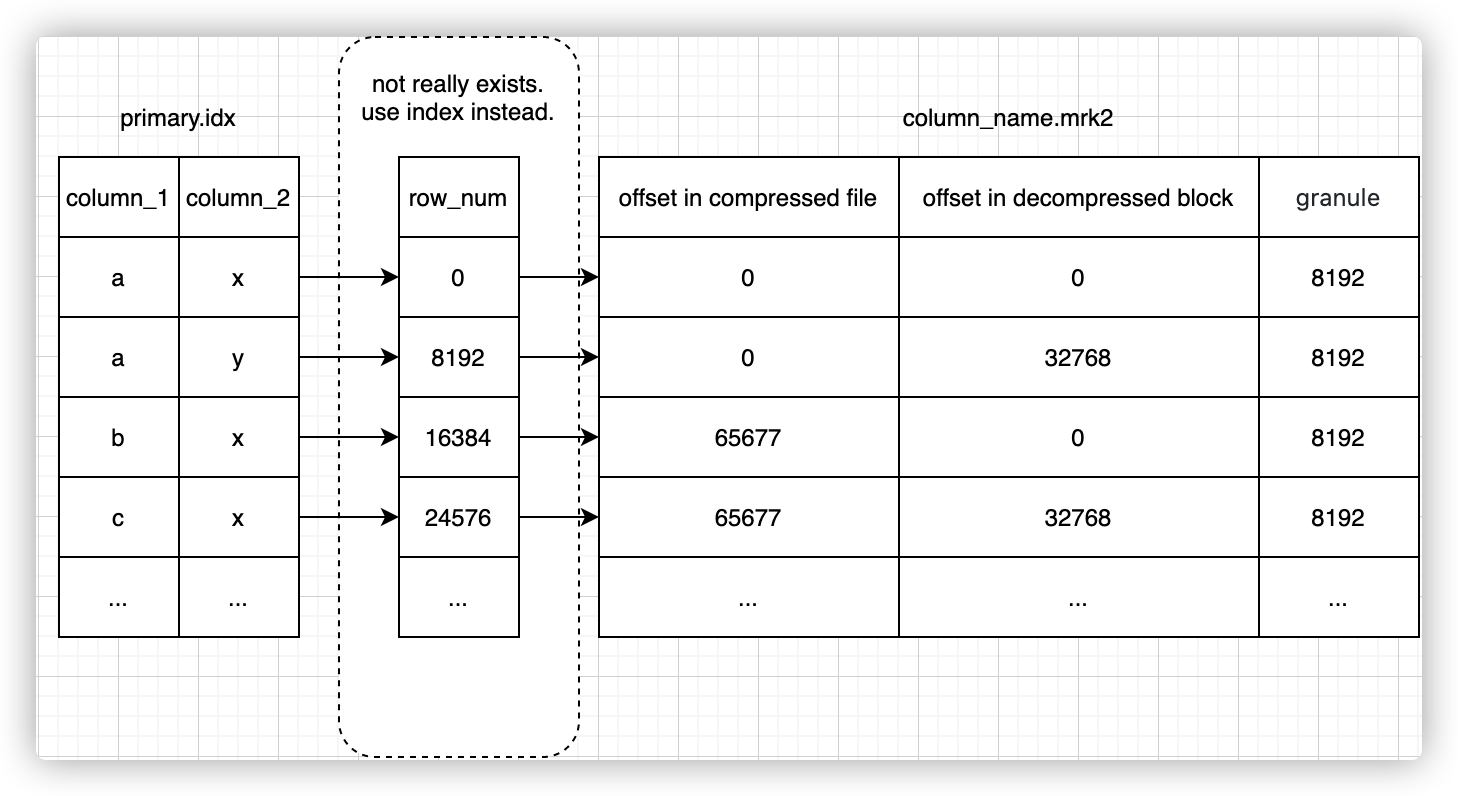
这里的行号其实只是用于关联起索引和标记两个表,而这两个表的数据在行方向其实是一一顺序对应的,因此行号其实是实际上是不需要存在文件中的,这也是Clickhouse追求极致性能,数据尽量精简的一个体现。可以通过od查看一下真实的数据索引文件中和数据标记文件中的数据:
// 数据索引文件,存储的是一个个主健的值,这里主键只有一列
root@clickhouse-0:20210110_0_123_3_341# od -l -j 0 -N 80 --width=8 primary.idx
0000000 5670735277560
0000010 24176312979802680
0000020 48658950580167724
0000030 72938406171441414
0000040 96513037981382350
0000050 120656338641242134
0000060 145024009883201898
0000070 169438340458750532
0000100 193384698694174670
0000110 217869890390743588
// 数据标记文件,可以看作三列,分别是数据压缩块位置,数据块内偏移和granule大小
root@clickhouse-0:20210110_0_123_3_341# od -l -j 0 -N 240 --width=24 ./value9.mrk2
0000000 0 0 8192
0000030 0 32768 8192
0000060 65677 0 8192
0000110 65677 32768 8192
0000140 129357 0 8192
0000170 129357 32768 8192
0000220 193106 0 8192
0000250 193106 32768 8192
0000300 258449 0 8192
0000330 258449 32768 8192
此外,在上面所举的例子中,granule都是固定为8192大小的,于是每8192行会有一行索引数据以及一行标记数据。但是从数据所占空间来看,8192行数据可能占很大空间,也可能占很小空间。如果占了很大空间,则会导致庞大的数据却只有一行索引一行标记,每次查询要做大量扫描解压的工作,拖慢整体性能,用户必须很小心地配置index_granularity。于是在新版本的Clickhouse中,会默认开启自适应granularity,新增配置项index_granularity_bytes来使得一个granule的数据大小不仅取决于行数,也取决于数据大小,因此在标记文件中会有新的一列来表示每个granule的行数。每index_granularity行会产生一行索引和标记,每index_granularity_bytes大小也会产生一行索引和标记。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号