
Elastic学习之旅 (5) 倒排索引和Analyzer分词
 本篇,我们了解下ElasticSearch的另一个重要概念:倒排索引 和 一个重要工具:Analyzer,通过一些demo了解Analyzer的具体使用案例,它们帮助ElasticSearch实现了强大的搜索功能。
本篇,我们了解下ElasticSearch的另一个重要概念:倒排索引 和 一个重要工具:Analyzer,通过一些demo了解Analyzer的具体使用案例,它们帮助ElasticSearch实现了强大的搜索功能。
上一篇:ES文档的CRUD操作
重要概念1:倒排索引
在学习ES时,倒排索引是一个非常重要的概念。要了解倒排索引,就得先知道什么是正排索引。举个简单的例子,书籍的目录页(从章节名称快速知道页码)其实就是一个典型的正排索引。
而一般书籍的末尾部分的索引页,则是一个典型的倒排索引,是从关键词 到 章节名称 / 页码。

由上可知,对于图书来讲:目录页就是正排索引,索引页就是倒排索引。
而对于搜索引擎来讲:文档ID到文档内容和单词的关联是正排索引,而单词到文档ID的关系则是倒排索引。
我们可以从下面的两个表格来感受下正排索引和倒排索引的区别:

倒排索引的核心内容
倒排索引包含两个部分:
-
单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系。单词词典一般都很大,一般都通过B+树 或 哈希拉链法 实现,以满足高性能的插入和查询。
-
倒排列表(Posting List):记录了单词对应的文档结合,由倒排索引项组成。倒排索引项(Posting)包括 文档ID、词频(TF,该单词在文档中出现的次数,用于相关性评分)、位置(Postion,单词在文档中分词的位置,用于语句搜索) 以及 偏移(Offset,记录单词的开始结束为止,实现高亮显示)
下图展示了ES中的一个例子:
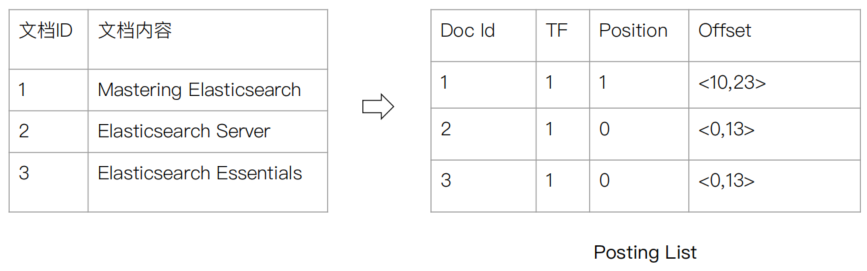
ES中的JSON文档中的每个字段,都有自己的倒排索引。当然,我们可以指定对某些字段不做索引,以节省存储空间,但是这些字段就无法被搜索。
重要概念2:Analyzer
在ES中文本分析是其最常见的功能之一,文本分析(Analysis)是把全文转换为一系列单词(term)的过程,也叫作分词。
文本分析是通过Analyzer来实现,我们可以使用ES内置的分析器,也可以按需定制分析器。
除了在数据写入时会进行全文转换词条,在匹配Query语句时也需要用相同的分析器对查询语句进行分析。
ES中的内置分词器
-
Standard Analyzer - 默认分词器,按词切分,小写处理
-
Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
-
Stop Analyzer - 小写处理,停用词过滤(the, a, is)
-
Whitespace Analyzer - 按照空格切分,不转小写
-
Keyword Analyzer - 不分词,直接将输入当做输出
-
Patter Analyzer - 正则表达式,默认 \W+(非字符分隔)
-
Language - 提供了30多种常见语言的分词器
-
Custom Analyzer - 自定义分词器
通过Analyzer进行分词
这里,我们来用_analyzer API做一些demo:
(1)Standard Analyzer
GET /_analyze { "analyzer": "standard", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
分词结果:按词切分,默认小写(Quick被转成了quick)
{ "tokens" : [ { "token" : "2", "start_offset" : 0, "end_offset" : 1, "type" : "<NUM>", "position" : 0 }, { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "<ALPHANUM>", "position" : 1 }, { "token" : "quick", "start_offset" : 10, "end_offset" : 15, "type" : "<ALPHANUM>", "position" : 2 }, { "token" : "brown", "start_offset" : 16, "end_offset" : 21, "type" : "<ALPHANUM>", "position" : 3 }, { "token" : "foxes", "start_offset" : 22, "end_offset" : 27, "type" : "<ALPHANUM>", "position" : 4 }, { "token" : "leap", "start_offset" : 28, "end_offset" : 32, "type" : "<ALPHANUM>", "position" : 5 }, { "token" : "over", "start_offset" : 33, "end_offset" : 37, "type" : "<ALPHANUM>", "position" : 6 }, { "token" : "lazy", "start_offset" : 38, "end_offset" : 42, "type" : "<ALPHANUM>", "position" : 7 }, { "token" : "dogs", "start_offset" : 43, "end_offset" : 47, "type" : "<ALPHANUM>", "position" : 8 }, { "token" : "in", "start_offset" : 48, "end_offset" : 50, "type" : "<ALPHANUM>", "position" : 9 }, { "token" : "the", "start_offset" : 51, "end_offset" : 54, "type" : "<ALPHANUM>", "position" : 10 }, { "token" : "summer", "start_offset" : 55, "end_offset" : 61, "type" : "<ALPHANUM>", "position" : 11 }, { "token" : "evening", "start_offset" : 62, "end_offset" : 69, "type" : "<ALPHANUM>", "position" : 12 } ] }
(2)Simple Analyzer
GET /_analyze { "analyzer": "simple", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
分词结果:非字母切分,忽略了数字2,小写处理
{ "tokens" : [ { "token" : "running", "start_offset" : 2, "end_offset" : 9, "type" : "word", "position" : 0 }, ...... ] }
(3)Whitespace Analyzer
GET /_analyze { "analyzer": "whitespace", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
分词结果:按照空格切分,不转小写。可以看到,brown-foxes被看成是一个整体,并未像其他分词一样分为brown 和 foxes。此外,也不会强制换位小写,比如Quick就保留了大写。
{ "tokens" : [ ...... { "token" : "Quick", "start_offset" : 10, "end_offset" : 15, "type" : "word", "position" : 2 }, { "token" : "brown-foxes", "start_offset" : 16, "end_offset" : 27, "type" : "word", "position" : 3 }, ...... ] }
(4)Stop Analyzer
GET /_analyze { "analyzer": "stop", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
分词结果:小写处理,停用词过滤(the, a, is),这里原文中的in, over, the都被过滤掉了。
(5)Keyword Analyzer
GET /_analyze { "analyzer": "keyword", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
分词结果:不做任何分词处理,而是将输入整体作为一个term。通常用于不需要对输入做分词的场景。
{ "tokens" : [ { "token" : "2 running Quick brown-foxes leap over lazy dogs in the summer evening.", "start_offset" : 0, "end_offset" : 70, "type" : "word", "position" : 0 } ] }
(6)Pattern Analyzer
GET /_analyze { "analyzer": "pattern", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
正则表达式,默认 \W+(非字符分隔)
新增一个表达式analyzer:
PUT my_index { "settings": { "analysis": { "analyzer": { "my_email_analyzer": { "type": "pattern", "pattern": "\\W|_", "lowercase": true } } } } } POST my_index/_analyze { "analyzer": "my_email_analyzer", "text": "John_Smith@foo-bar.com" }
(7)Lanuage Analyzer
ES提供了多种语言的分词器:阿拉伯语、亚美尼亚语、巴斯克语、孟加拉语、巴西语、保加利亚语、加泰罗尼亚语、捷克语、丹麦语、荷兰语、英语、芬兰语、法语、加利西亚语、德语、希腊语、印地语、匈牙利语、印度尼西亚语、爱尔兰语、意大利语、拉脱维亚语、立陶宛语、挪威语、波斯语、葡萄牙语、罗马尼亚语、俄语、索拉尼语、西班牙语、瑞典语、土耳其语、泰国语。
这里我们看看English:
GET /_analyze { "analyzer": "english", "text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening." }
分词结果:将running替换为了run,将foxes替换为fox,dogs替换为dog,evening替换为了even,in被忽略。
可以看到,ES支持的语言分词器中,没有支持中文,这是因为:中文分词存在较大的难点,不像英语那么简单。
不过,我们可以安装一些中文分词器的插件(plugin),比如ICU Analyzer, 它提供了unicode的支持,更好地支持亚洲语言。
elasticsearch-plugin install analysis-icu
ICU Analyzer的示例:
POST /_analyze { "analyzer": "icu_analyzer", "text": "他说的确实在理" }
分词结果:
[他,说的,确实,在,理]
小结
本篇,我们了解了ElasticSearch的另一个重要概念:倒排索引 和 一个重要工具:Analyzer,还通过一些demo了解了Analyzer的具体使用案例,它们帮助ElasticSearch实现了强大的搜索功能。
参考资料
极客时间,阮一鸣,《ElasticSearch核心技术与实战》



 浙公网安备 33010602011771号
浙公网安备 33010602011771号