**上节课复习:**
1、装饰器
迭代器
叠加多个装饰器的加载顺序与执行顺序
**今日内容:**
1、函数递归调用
2、函数剩余部分
生成式
匿名函数
内置函数
3、面向过程编程
**复习yield**
简单粗俗的理解yield
可以先理解成return
不同的是返回一个值之后,他会记住这个返回的位置,下次迭代就从这个位置后开始
def func():
print("hello1")
print("hello1")
print("hello1")
yield 111
print('hello2')
print('hello2')
print('hello2')
print('hello2')
yield 222
print('hello3')
print('hello3')
print('hello3')
func() # 程序开始执行以后,因为func函数中有yield关键字,所以func函数并不会
真的执行,而是先得到一个生成器g(相当于一个对象)
g = func() #generator(生成器),此时未开始执行代码
res=next(g) #直到调用next方法,函数代码开始运行,碰到yield停下来
print(res) #把yield的值当作本次结果返回
#函数没有结束只是暂停
res=next(g) #再来一次,继续执行,同上,如果取完所有值会报错
print(res)
**基于yield的小练习:**
def my_range(start, stop, step):
while start < stop:
yield start
start += step
g = my_range(1,5,2)
res = next(g)
print(res)
res = next(g)
print(res)
res = next(g)
print(res)
for i in my_range(1,5,2):
print(i)
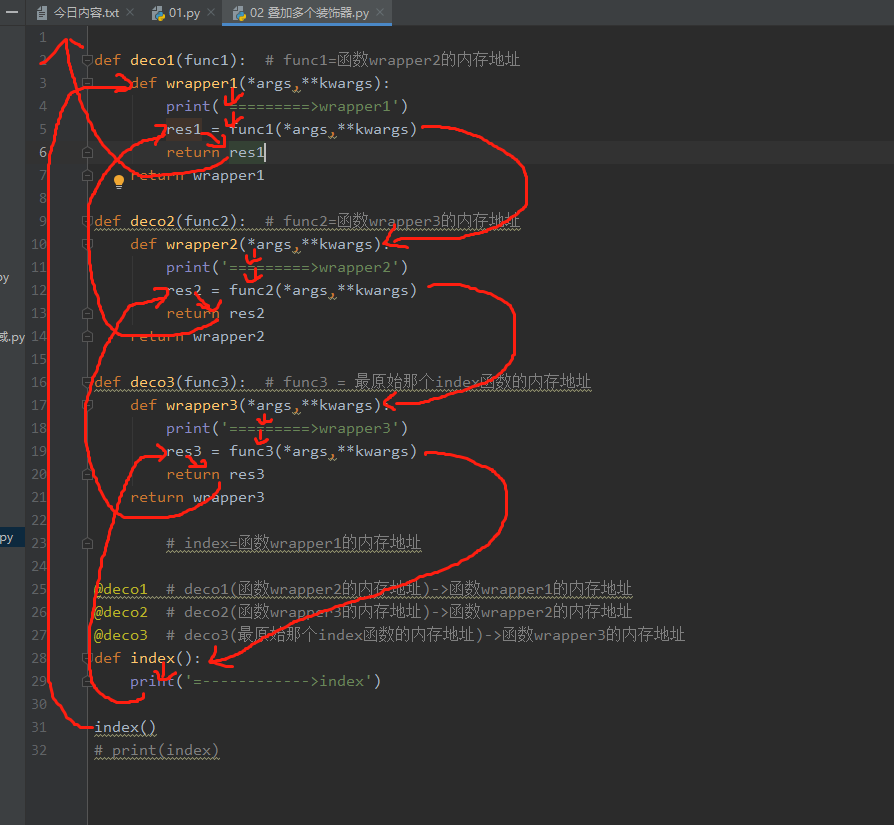
**叠加多个装饰器**
def deco1(func1): # func1=函数wrapper2的内存地址
def wrapper1(*args,**kwargs):
res1 = func1(*args,**kwargs)
print('=========>wrapper1')
return res1
return wrapper1
def deco2(func2): # func2=函数wrapper3的内存地址
def wrapper2(*args,**kwargs):
res2 = func2(*args,**kwargs)
print('=========>wrapper2')
return res2
return wrapper2
def deco3(func3): # func3 = 最原始那个index函数的内存地址
def wrapper3(*args,**kwargs):
res3 = func3(*args,**kwargs)
print('=========>wrapper3')
return res3
return wrapper3
# index=函数wrapper1的内存地址
@deco1 # deco1(函数wrapper2的内存地址)->函数wrapper1的内存地址
@deco2 # deco2(函数wrapper3的内存地址)->函数wrapper2的内存地址
@deco3 # deco3(最原始那个index函数的内存地址)->函数wrapper3的内存地址
# 加载顺序是自下而上的
def index():
print('=------------>index')
return 123
res = index()
print(res)
"""
**1 什么是函数递归调用**
函数递归调用是函数嵌套调用的一种特殊格式,具体是指在调用一个函数的过程
又直接或者间接地调用自己
函数递归调用不应该无限递归调用下去,应该在满足某种条件下结束递归调用
所以,函数递归应该分为两个阶段:
1、回溯
2、递推
**2 为何要用**
重复运行代码的第三种方案
**3 如何用**
1.
def f1():
print('hello1')
print('hello2')
print('hello3')
f1()
f1()
2.
while True:
print('hello1')
print('hello2')
print('hello3')
def f1():
print('f1=====>')
f2()
def f2():
print('f2====>')
f1()
f1()
3.
age(5) = age(4) + 10
age(4) = age(3) + 10
age(3) = age(2) + 10
age(2) = age(1) + 10
age(1) = 30
n > 1 age(n) = age(n-1) + 10
n = 1 age(1) = 30
def age(n):
if n == 1:
return 30
return age(n-1) + 10
res = age(5)
print(res)
4.
l = [1,[2,[3,[4,[5,[6,[7,[8,[9]]]]]]]]]
def foo(l):
for item in l:
if type(item) is not list:
print(item)
else:
foo(item)
foo(l)
**# 基于递归实现二分法**
nums = [-3, 5, 7, 11, 21, 31, 41, 53, 67, 77, 83, 99, 101]
def search(nums,find_num):
print(nums)
if len(nums) == 0:
print('不存在')
return
mid_index = len(nums) // 2
if find_num > nums[mid_index]:
# 在右半部分
search(nums[mid_index+1:],find_num)
elif find_num < nums[mid_index]:
# 在左半部分
search(nums[:mid_index],find_num)
else:
print('找到了')
# search(nums,67)
search(nums,69)
递归:擅长不是死循环在一定次数内完成,不知道次数
**一 列表生成式 [最常用]**
l = []
for i in range(1, 6):
if i > 3:
l.append(i)
print(l)
l = [i for i in range(1,6) if i > 3] #通过一行代码便利上面多行代码
print(l)
#把每次for循环的元素放在for左边,每循环一次就将元素i,append到列表中,这里便利了五次
在不丧失可读性的情况下便利了原代码
names = ['liusir_dsb', 'housir_dsb', 'egon', 'wusir_dsb']
res = [name for name in names if name.endswith('dsb')] #过滤筛选
print(res)
**二 字典生成式**
res = {k:v for k,v in [('name', 'egon'), ('age', 18)]}
res = {i:i for i in range(5)}
print(res)
**三 集合生成式**
res = {i for i in range(5)}
print(res,type(res))
#元组可以通过列表来实现
**四 生成器表达式**
第一种函数内写yield
第二种生成器表达式
****l = [i for i in range(1,6)]
g = (i for i in range(1,6))
print(g)
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
**用生成器读出字符个数**
with open('a.txt',mode='rt',encoding='utf-8') as f:
res = f.read()
print(len(res))
↓ 优化(如果内容过多,统计每一行的长度)
res = 0
for line in f:
res += len(line)
↓ 优化
res = sum([len(line) for line in f])
↓ 优化
res = sum((len(line) for line in f))
↓ 优化 (删除括号默认是生成器)
res = sum(len(line) for line in f)
print(res)
**匿名函数**
# 匿名函数只能用一次
def foo(x, y):
return x + y
**调用匿名函数方式一**
f=lambda x,y:x+y
print(f(1,2))
**调用匿名函数方式二**
res = (lambda x,y:x+y)(1,2)
print(res)
匿名函数真正的用途是与其他函数配合使用
salaries = {
'axx': 30000,
'bxx': 3000,
'cxx': 2000,
'egon': 1000,
'zxx': 500}
print(max([33,44,11,99]))
def func(k):
return salaries[k]
print(max(salaries,key=func))
print(max(salaries,key=lambda k:salaries[k]))
print(min(salaries,key=lambda k:salaries[k]))
print(sorted(salaries,key=lambda k:salaries[k]))
print(sorted(salaries,key=lambda k:salaries[k],reverse=True))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号