MySQL开发优化
MySQL开发优化
MySQL 索引类型
聚集索引
使用聚集索引的表,记录和索引保持着一致的顺序,这样只要找到索引的值就能直接从叶子节点里面获取到全部列数据
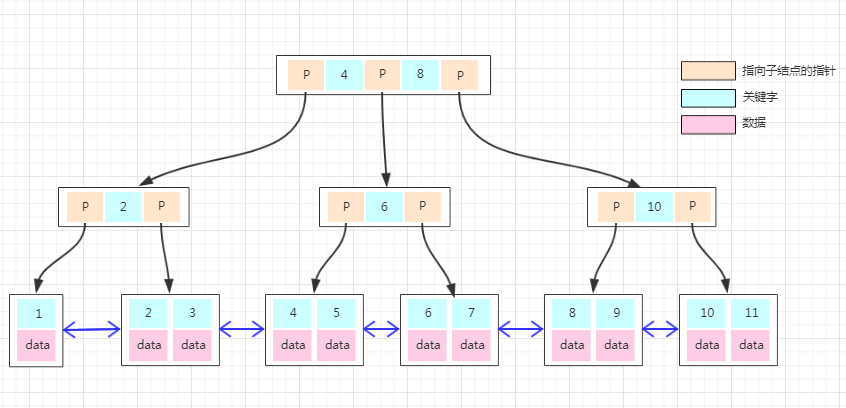
非聚集索引
记录和索引的顺序往往不同,可理解为索引下面的叶子节点存储的还是索引,想要获得真正的列数据,还需要再一次查询
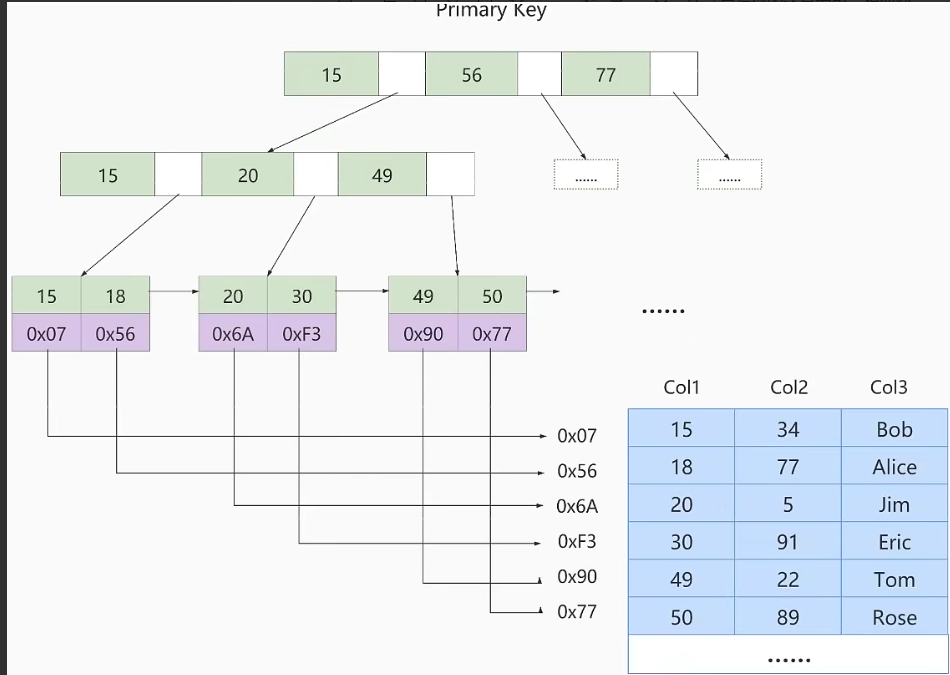

索引优化
索引数据结构
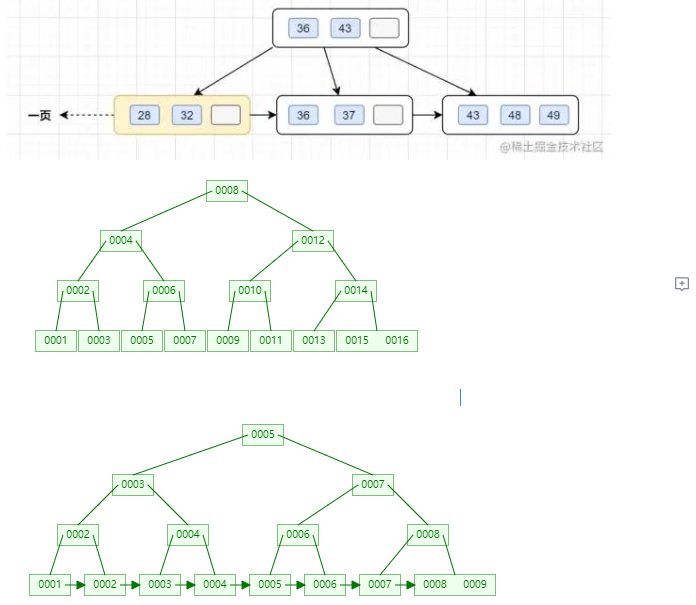
联合索引
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
https://www.cs.usfca.edu/~galles/visualization/BST.html
https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
https://www.cs.usfca.edu/~galles/visualization/BTree.html
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
explain
type 由上至下,效率越来越高
●ALL 全表扫描
●index 索引全扫描
●range 索引范围扫描,常用语<,<=,>=,between,in等操作
●ref 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
●eq_ref 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
●const/system 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询
●null MySQL不访问任何表或索引,直接返回结果
●虽然上至下,效率越来越高,但是根据cost模型,假设有两个索引idx1(a, b, c),idx2(a, c),SQL为"select * from t where a = 1 and b in (1, 2) order by c";如果走idx1,那么是type为range,如果走idx2,那么type是ref;当需要扫描的行数,使用idx2大约是idx1的5倍以上时,会用idx1,否则会用idx2
Extra
●Using filesort:MySQL需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配WHERE子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行。
●Using temporary:使用了临时表保存中间结果,性能特别差,需要重点优化
●Using index:表示相应的 select 操作中使用了覆盖索引(Coveing Index),避免访问了表的数据行,效率不错!如果同时出现 using where,意味着无法直接通过索引查找来查询到符合条件的数据。
●Using index condition:MySQL5.6之后新增的ICP,using index condtion就是使用了ICP(索引下推),在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据。
show profile 分析
SHOW PROFILES ;
SHOW PROFILE FOR QUERY #{id};
确定问题并采用相应的措施
●优化索引
●优化SQL语句:修改SQL、IN 查询分段、时间查询分段、基于上一次数据过滤
●改用其他实现方式:ES、数仓等
●数据碎片处理
场景分析
最左匹配原则
index ('area_id', 'good_number')
不走索引
select * from goods_info where good_number = 2;
走索引
select * from goods_info where area_id = 1 and good_number = 2;
or
select * from goods_info where area_id = 1;
隐式转换
5.7 以后是走索引的
select * from goods_info where area_id = 1;
select * from goods_info where FLOOR(area_id/10) = 1
大分页
select * from goods_info where area_id=1 and good_number = 2 order by id desc limit 10000, 10
in + order by
select * from goods_info where area_id in (3,4,5,6) order by good_nnumber desc
范围查询阻断,后续字段不能走索引
explain select * from goods_info where area_id > 1 and good_number=2
or 索引失效
explain select * from goods_info where area_id = 1 or good_number = 2
like 失效
select * from goods_info where good_name like '%1%'
索引字段上使用(!= 或者 < >),索引可能失效
explain select * from goods_info where area_id != 1
注意覆盖索引问题
事务处理
●原子性(undo log)
●持久性 (redo log)
●隔离行(不同的事务之间相互不受影响)
●一致性(数据执行前后数据接口一直不变 这是个目标)
写写操作
写读操作
事务隔离间级别锁之间关系(读写)
隔离级别
●未提交读 (Read Uncommitted):允许脏读,也就是可能读取到其他会话中未提交事务修改的数据
●提交读 (Read Committed):只能读取到已经提交的数据。Oracle 等多数数据库默认都是该级别 (不重复读)
●可重复读 (Repeated Read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB 默认级别。在 SQL 标准中,该隔离级别消除了不可重复读,但是还存在幻象读
●串行读 (Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
1.脏读:有AB两个事务,B事务对一条数据进行修改,但未提交;而A事务在这之后对同一条数据进行读操作,读到的若是未提交的修改后的数据,就说明产生了脏读现象。
演示:「读未提交」隔离级别下,读写操作可以同时进行,但写写操作无法同时进行。与此同时,该隔离级别下只会使用行级别的记录锁,并不会用间隙锁
// 设置隔离级别
SET session TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
// 查看隔离级别
select @@transaction_isolation;
----读写-----
//A 事务
beign;
select * from goods_info where id = 1;
//B事务开启运行以后再查询
select * from goods_info where id = 1
//B 事务
begin;
update goods_info set goods_price = 20 where id = 1;
--写写--
//事务A
begin;
update goods_info set goods_price = goods_price+20 where id = 1;
//事务B
begin;
update goods_info set goods_price = goods_price+20 where id = 1;
2.不可重复读:有一个A事务和若干其他事务,A事务对一条数据(或多条符合同一查询条件的数据)进行多次的读操作;其他的事务对A事务所读的数据进行了修改(这里不包括插入新的数据),若是未提交,在RU级别可以读到修改的数据,若是已提交,在RC级别及以下可以读到修改的数据;那么这种情况就可能会导致A事务在多次读取数据的时候,发现读取的数据值不一致,这种现象被称为不可重复读。
// 设置隔离级别 已提交读
SET session TRANSACTION ISOLATION LEVEL READ COMMITTED;
// 查看隔离级别
select @@transaction_isolation;
//A 事务
begin;
select * from goods_info where id = 1 for UPDATE//B 事务知晓
//B 事务
begin;
select * from goods_info where id = 1 for UPDATE
3.幻读:幻读指的是一个事务在前后两次查询同一个范围的时候,后一次查询看到了前一次查询没有看到的行。
锁
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
行锁(写&读)
具有索引的查找做的是行锁
行锁(写&写)
表锁
update goods_info set good_number = 1 where good_name = '张三'
没有加索引的查找
间隙锁
●什么是间隙锁
当我们采用范围条件查询数据时,InnoDB 会对这个范围内的数据进行加锁。比如有 id 为:1、3、5、7 的 4 条数据,我们查找 1-7 范围的数据。那么 1-7 都会被加上锁。2、4、6 也在 1-7 的范围中,但是不存在这些数据记录,这些 2、4、6 就被称为间隙。
●间隙锁的危害
范围查找时,会把整个范围的数据全部锁定住,即便这个范围内不存在的一些数据,也会被无辜的锁定住,比如我要在 1、3、5、7 中插入 2,这个时候 1-7 都被锁定住了,根本无法插入 2。在某些场景下会对性能产生很大的影响
独占了
BEGIN;
select * from tx where id < 7 for UPDATE
没法插入
BEGIN;
INSERT tx VALUES(2,3,4)
MySQL多版本控制(MVCC)
MVCC 实现细节
SELECT
InnoDB 会根据以下两个条件检测每行记录:
a. 版本号早于当前事务的数据行 (table_txid <= tx_id) 也就是说要么是本事务修改的,要么是 开始查询就存在的,保证可重复读
b. 行的删除要么未定义null 要么大于当前版本号,也就说我事务开始以后被删除的。
INSERT
InnoDB 未新插入的每行保存单曲系统事务版本号作为表隐藏版本table_tx_id
DELETE
InnoDB 未删除的买一行保存单曲系统版本号作为删除标识 table_del_id
UPDATE
InnoDB 插入一条记录 版本号当前,删除一条记录版本号当前。
MySQL 默认是自动提交事务 AICD
锁情况
select * from information_schema.innodb_locks;
InnoDB 整体状态,其中包括锁的情况
show engine innodb status;
执行事务A
start transaction;
update account set balance = 1000 where id = 1;
在事务B中执行
start transaction;
update account set balance = 2000 where id =1;
模拟产生表
CREATE PROCEDURE auto_insert()
BEGIN
declare num int default 1;
declare sum int default 1000000;
/*
添加100万条数据
/
while num<=sum do
insert into goods_info(goods_name,goods_number,goods_price)
values(concat('货物',num,'号'),FLOOR(RAND() * 1000) ,RAND() * 1000);
/
其中,RAND() * 1000指的是随机从0到1000随机取数,FLOOR(RAND() * 1000)指的是随机取整数
*/
set num =num+1;
end while;
END
MySQL for update 不等于 sqlserver updlock
select * from information_schema.INNODB_TRX;
INFORMATION_SCHEMA.INNODB_TRX、INNODB_LOCKS、INNODB_LOCK_WAITS
1、执行 SHOW ENGINE INNODB STATUS,查看事务相关信息
2、查看 INFORMATION_SCHEMA.INNODB_TRX、INNODB_LOCKS、INNODB_LOCK_WAITS 三个表,通过这些信息能快速发现哪些事务在阻塞其他事务
先查询 INNODB_TRX 表,看看都有哪些事务
再看 INNODB_LOCKS 表,看看都有什么锁
最后看 INNODB_LOCK_WAITS 表,看看当前都有哪些锁等待
null 搞鬼
1、count
2、sum
SELECT sum(del_id),COUNT(del_id) from tx -- ifnull(sum(del_id),0)
3、is null 查找
SELECT * from tx where del_id !=1 -- and is null
4、对索引影响
建议在 表设计的时候就要设置 not null 加default

 浙公网安备 33010602011771号
浙公网安备 33010602011771号