
从零开始学正则(三),理解正则的分组与反向引用

壹 ❀ 引
我在从零开始学正则(二)这篇文章中介绍了正则位置的概念,以及匹配位置常用的六个锚,位置相关的知识虽然不多,不过理解起来还挺费劲。在文章结尾留下了两个问题,一问写一个正则将"12345678"变成千位分隔符表示法 "12,345,678";二问验证密码长度在6-12位之间,且至少包含数字,小写字母与大写字母其中两种。
我们先来分析第一个问题,所谓千位分隔符其实就是从右往左每隔三位数加进一个逗号。有个问题,我们理解的正则匹配都是从左往右,怎么反过来?这里就可以使用 $ 匹配尾部,表示从尾部开始匹配,改变匹配方向。
从右往左,逗号都在3n(n>=1,使用量词+表示)个数字前面,很明显这是要匹配位置,这里可以使用 (?=p) 正向先行断言解决,所以正则是这样:
var str = '12345678'; var regex = /(?=(\d{3})+$)/g; var result = str.replace(regex, ','); //12,345,678
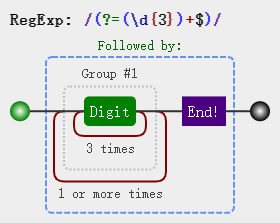
怎么理解这个正则呢,(\d{3})+$ 是一个匹配条件,也就是找 (\d{3})+$ 前面的位置,其中 (\d{3}) 是一个组,这个组会出现1次或更多次,所以后面跟了+,又因为要从尾部开始匹配,所以还有个$,不难吧?
看着貌似没问题,但如果我们要将123456789改为千位分隔符就出现问题了:
var str = '123456789'; var regex = /(?=(\d{3})+$)/g; var result = str.replace(regex, ','); //,123,456,789
很遗憾,如果被处理的字符串刚好是三的倍数,就会出现头部多一个逗号的情况,这不是我们想要的,怎么办呢?其实可以使用 (?!p) 负向先行断言表示除了开头的位置,开头的位置是谁?当然是脱字符^啦。于是我们加个条件:
var str = '123456789'; var regex = /(?!^)(?=(\d{3})+$)/g; var result = str.replace(regex, ','); //123,456,789
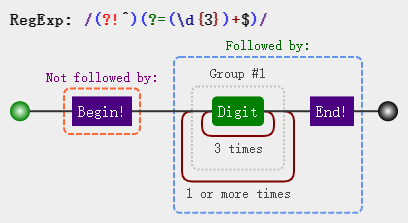
那么现在正则的意思就是,匹配不是开头的且是三倍数前面的位置,这里(?!^)和(?=(\d{3})+$)是两个组,表示并列关系,就像JavaScript中的&&,注意不要与管道符 | 弄混淆了,管道符表示分支,即满足其一即可,就像JavaScript中的 || 。
我们来接着分析第二个问题,验证密码长度在6-12,且必须包含大小写字母数字其中两种。如果只是6-12位大小写字母与数字都还好,只需这样:
var str = "abcdef"; var regex = /^[0-9a-zA-Z]{6,12}$/g; var result = regex.test(str); //true
那么我们如何验证字符串是否包含一个数字呢,这里直接上结论,使用 (?=.*[0-9]) 可以做到,我来详细解释下意思:
首先 (?=.*[0-9]) 的本意是看能不能找到.*[0-9]前面的位置,如果能找到那说明至少有一个.*[0-9],所以我们只需要明白.*[0-9]是什么意思就好了。
[0-9] 好理解,0-9之间的任意一个数字,那为什么不直接写成 (?=[0-9]) 呢,如果说单纯判断有没有数字,准确来说 (?=[0-9]) 是没问题的,我们来测试一下:
var regex = /(?=[0-9])/g; regex.test('1') //true regex.test('a1') //true regex.test('❀1❀') //true regex.test('a') //false
但现在要求是至少包含两种数字和大/小写字母其中两种,我们假设是包含数字和小写字母,按常理来说正则应该是这样,我们测试下:
var regex = /(?=[0-9])(?=[a-z])/g; regex.test('1a') //false regex.test('aa1') //false regex.test('11a') //false
结果发现全部为false,因为此时正则表达式是希望找一个既在数字前又在小写字母前的位置。或者反过来理解,当同时存在数字和小写字母时,一定有一个位置同时在数字和字母前。理解这个关键点,问题就迎刃而解了。
我们先单纯以1a为例,哪个位置既在1前面,又在字母a前面?毫无疑问就是 ^,所以我们改写正则:
var regex = /(?=[0-9])(?=1[a-z])/g; regex.test('1a') //true
你看,这不就为true了。再看例子aa1,这个位置有两个,可以是 a 与 a1 中间,也可以是 ^,比如我们以查a与a1中间的位置为例:
var regex = /(?=a[0-9])(?=[a-z])/g; regex.test('aa1') //true
或者以查 ^ 为例:
var regex = /(?=aa[0-9])(?=[a-z])/g; regex.test('aa1') //true
你看,只要我们能找到共同位置,就表示同时存在两种字符。
但有个问题,这几个例子都是我们写死的,字符结构固定。实际开发中我们也不知道数字前面有没有字符,字母前有没有数字,有几个数字,怎么办呢?只要加上 .* 就好了,. 表示通配符,*表示量词{0,},即任意字符出现任意次数。
我们再看 /(?=.*[0-9])(?=.*[a-z])/g,这不就是找一个既在数字前又在小写字母前的正则吗。那么我们再结合6-12位长度,结合起来就是这样:
var regex = /(?=.*[0-9])(?=.*[a-z])^[0-9a-zA-Z]{6,12}$/g; regex.test('1aaaaa') //true regex.test('a12345') //true regex.test('aaaaaa') //false regex.test('111111') //false

为什么 (?=.*[0-9])(?=.*[a-z]) 是写在 ^ 前面?在正则第二章介绍中我们已经知道位置其实是很抽象的东西,如果用空字符""表示位置,它可以是无数个。所以我们可以理解为在 ^ 前面还有无数个看不见的位置,那么只要你的字符同时拥有小写字母和数字,就一定能在开头位置 ^ 前找到这个位置,我们将上面的正则抽象成js语句,它更像这样:
if(位置===(?=.*[0-9])&& 位置===(?=.*[a-z])){ ^[0-9a-zA-Z]{6,12}$; };
这只是数字和小写字母的情况,我们还得结合数字和大写字母,小写字母和大写字母,所以最终正则就是这样:
var regex =/((?=.*[0-9])(?=.*[a-z])|(?=.*[0-9])(?=.*[A-Z])|(?=.*[a-z])(?=.*[AZ]))^[0-9A-Za-z]{6,12}$/
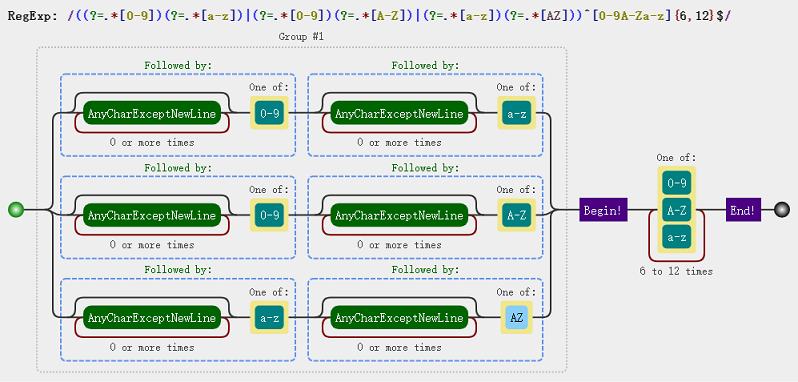
除了使用正向先行断言,我们还可以使用负向先行断言,即输入字段不能同时为数字,同时为小写字母,同时为大写字母,正则为:
var regex = /(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/;
关于这条正则我只能贴出来给大家看看,确实有点无力解释,请教了公司几个资历老的员工,都无法解答。我突然明白原书推荐第一遍不求甚解的读是啥意思了,这两道题我光分析,查资料整理用了半天....还是因为我太菜的缘故吧。若有有缘人看到,能帮我解答那是最好不过了。

那么关于题目先分析到这里,不知道大家有没有发现,上述题目解答中对于分组括号使用特别频繁,我在解答题目时也发现像量词+*写在括号内和括号外传达的意思完全不同,那么本篇主要对于正则表达式的括号使用展开分析。
说在前面,正则学习系列文章均为我阅读 老姚《JavaScript正则迷你书》的读书笔记,文中所有正则图解均使用regulex制作。那么本文开始!
贰 ❀ 分组和分支结构
1.分组基础
在正则中,圆括号 () 表示一个分组,即括号内的正则是一个整体,表示一个子表达式。
我们知道 /ab+/ 表示匹配a加上一个或多个b的组合,那如果我们想匹配ab的多次组合呢?这里就可以使用()包裹ab:
var str = 'abab ababab aabbaa'; var regex = /(ab)+/g; var result = str.match(regex); //["abab", "ababab", "ab"]
在分支中使用括号也是非常常见的,比如这个例子:
var str1 = 'helloEcho'; var str2 = 'helloKetty'; var regex = /^hello(Echo|Ketty)$/; var result1 = regex.test(str1); //true var result2 = regex.test(str2); //true
若我们不给分组加括号,此时的分支就变成了helloEcho和Ketty,很明显这就是不是我们想要的。(注意正则尾部未加全局匹配g,如果加了第二个验证为false,原因参考)。
2.分组引用
不知道大家在以往看正则表达式时有没有留意到$1,$2类似的字符,这类字符表示正则分组引用,对于正则使用是非常重要的概念。我们来看一个简单的例子:
写一个匹配 yyyy-mm-dd 的正则(这里先不考虑月不超过12之类的情况)
var regex = /(\d{4})-(\d{2})-(\d{2})/;
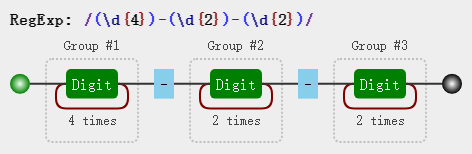
通过图解我们能发现每个分组上面多了类似Group #1的分组编号,是不是已经联想到$1相关的字符了呢?没错,这里$1,$2正是对应的分组编号。
这里我们科普两个方法,一个是字符串的match方法,一个是正则的exec方法,它们都用于匹配正则相符字段,看个例子:
var result1 = '2019-12-19'.match(regex); var result2 = regex.exec('2019-12-19'); console.log(result1); console.log(result2);

可以看到虽然方法写法不同,但结果一模一样,我们来解释下匹配的结果。
"2019-12-19"为正则最终匹配到的结果,"2019", "12", "19"这三个分别为group1,group2,group3三个分组匹配的结果,index: 0为匹配结果的开始位置,input: "2019-12-19"为被匹配的输入字段,groups: undefined表示一个捕获组数组或undefined(如果没有定义命名捕获组)。
我们可以通过$1,$2直接访问上面例子中各分组匹配到的结果。这里我们展示一个完整的例子,在使用过一次正则后输出RegExp对象,可以看到此对象上有众多属性,再通过 RegExp.$1 我们能直接拿到分组1的匹配结果:
var regex = /(\d{4})-(\d{2})-(\d{2})/; var string = "2019-12-19"; //注意,这里你得先使用一次正则,match test,replace等方法都行 regex.exec(string); console.dir(RegExp); console.log(RegExp.$1); // "2019" console.log(RegExp.$2); // "02" console.log(RegExp.$3); // "119"
现在我们要明白一个概念,$1表示的就是Group #1的匹配结果,它就像一个变量,保存了匹配到的实际值。那么知道了这一点我们能做什么呢?比如我们将 yyyy-mm-dd 修改为 dd/mm/yyy 格式。
var result = string.replace(regex, '$3/$2/$1'); // 19/12/2019 console.log(result);
这段代码等价于:
var result = string.replace(regex, function () { return RegExp.$3 + "/" + RegExp.$2 + "/" + RegExp.$1; // 19/12/2019 });
同时也等价于:
var result = string.replace(regex, function (match, year, month, day) { console.log(match, year, month, day);//2019-12-19 2019 12 19 return day + "/" + month + "/" + year;//19/12/2019 });
所以看到这,大家也不要纠结第一个修改中'$3/$2/$1'字段如何关联上的分组匹配结果,知道是正则底层实现这么去用就对了。
叁 ❀ 反向引用
除了像在上文API中那样使用分组一样,还有一个比较常见的就是在正则自身中使用分组,即代指之前已经出现过的分组,又称为反向引用。我们通过一个例子来了解反向引用。
现在我们需要一个正则能同时匹配 2019-12-19 2016/12/19 2016.12.19 这三种字段,正则我们可以这么写:
var regex = /\d{4}[-\/\.]\d{2}[-\/\.]\d{2}/; regex.test('2019-12-19'); //true regex.test('2019/12/19'); //true regex.test('2019.12.19'); //true
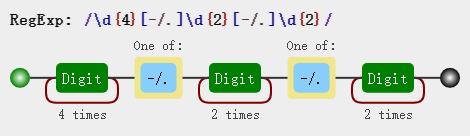
通过图解我们也知道这个正则其实有个问题,它甚至能匹配 2019-12.19 格式的字段
regex.test('2019-12.19'); //true
那现在我们要求前后两个分隔符一定相同时才能匹配成功怎么做呢,这里就需要使用反向引用,像这样:
var regex = /\d{4}([-\/\.])\d{2}\1\d{2}/; regex.test('2019-12-19'); //true regex.test('2019/12/19'); //true regex.test('2019.12.19'); //true regex.test('2019-12.19'); //false regex.test('2019/12-19'); //false
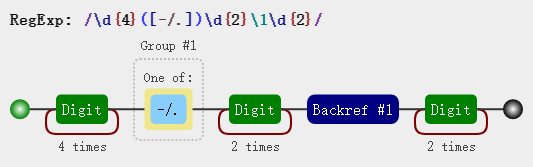
这里的 \1 就是反向引用,除了代指前面出现过的分组([-\/\.])以外,在匹配时它的分支选择也会与前者分组同步,说直白点,当前面分组选择的是 - 时,后者也会选择 - 然后才去匹配字段。
有个问题,括号也会存在嵌套的情况,如果多层嵌套反向引用会有什么规则呢?我们来看个例子:
var regex = /^((\d)(\d(\d)))\1\2\3\4$/; '1231231233'.match(regex); // true console.log( RegExp.$1 ); // 123 console.log( RegExp.$2 ); // 1 console.log( RegExp.$3 ); // 23 console.log( RegExp.$4 ); // 3

通过例子与图解应该不难理解,当存在多个括号嵌套时,从$1-$9的顺序对应括号嵌套就是从外到内,从左到右的顺序。
$1 对应的是 ((\d)(\d(\d))),$2 对应的是第一个 (\d),$3 对应的是 (\d(\d)),$4 对应的是 $3 中的 (\d)。
虽然我们在前面说的是$1-$9,准确来说,只要你的分组够多,我们甚至能使用$1000都行,比如:
var regex = /(a)(b)(c)(d)(e)(f)(g)(h)(i)(j)(k)(l)\12+/; var string = "abcdefghijkllll"; regex.test(string);//true console.log(RegExp.$12);//undefined

可以看到 \12 确实指向了前面的 (l) 分组,但由于RegExp对象只提供了 $1-$9 的属性,所以这里我们输出RegExp.$12是undefined。
还有一个问题,如果我们反向引用了不存在的分组会怎么样呢?很好理解,直接看个例子:
var regex = /\1\2\3/; var string = "\1\2\3"; regex.test(string);//true console.log(RegExp.$1);//为空
由于在\1前面不存在任何分组,所以这里的\1\2\3就单纯变成转义符\和三个数字123了,不会代指任何分组。
最后一点,分组后面如果有量词,分组会记录匹配的最后一次的数据,看个例子:
var regex = /(\w)+/; var string = "abcde"; console.log(regex.exec(string));// ["abcde", "e", index: 0, input: "abcde", groups: undefined]
可以看到分组匹配的结果为e,也就是最后捕获的数据,但index还是为0,表示捕获结果的开始位置。
所以在分组有量词的情况下使用反向引用,它也会指向捕获最大次数最后一次的结果。
var regex = /(\w)+\1/; regex.test('abcdea');//false regex.test('abcdee');//true var regex1 = /(\w)+\1/; regex.test('abcdee'); console.log(RegExp.$1);//2
肆 ❀ 非捕获括号
在前面讲述分组匹配以及反向引用时,我们都知道正则其实将分组匹配的结果都储存起来了,不然也不会有反向引用这个功能,那么如果我们不需要使用反向引用,说直白点就是不希望分组去记录那些数据,怎么办呢?这里就可以使用非捕获括号了。
写法很简单,就是在正则条件加上 ?: 即可,例如 (?:p) 和 (?:p1|p2|p3),我们来做个试验,看看最终match输出结果:
var regex = /(ab)+/; var string = "ababa aab ababab"; string.match(regex); console.log(RegExp.$1);//ab var regex = /(?:ab)+/; var string = "ababa aab ababab"; string.match(regex); console.log(RegExp.$1);//空
我们分别在正则分组 ab前面加或不加 ?:,再分别输出 RegExp.$1 ,可以看到普通分组记录了最后一次的匹配结果,而非捕获括号单纯起到了匹配作用,并没有去记录匹配结果。

伍 ❀ 总结
那么到这里,第三章知识全部解释完毕,我们来做一个技术总结,大家可以参照下方思维导图回顾知识点,看看是否还熟记于心头。

最后留两个思考题,请模拟实现 trim方法,即使用正则去除字符串开头与结尾的空白符。第二个,请将my name is echo每个单词首字母转为大写。
那么本文就写到这里了。我要开始学习第四章了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号