爬取bilibili综合热门排行榜及数据分析
爬取bilibili综合热门排行榜及数据分析
一、 选题背景
根据2019年第44次《中国互联网络发展状况统计报告》显示,至2019年6月,我国网民规模为8.54亿,Z世代(10-29岁)网民占比41.5%,约为3. 55亿人。B站在Z世代中的人口渗透率约为12.8%,渗透率将持续提高,增长潜力巨大。在QuestMobile统计的Z世代偏爱APP榜单中,B站独占鳌头。Z世代是生长于移动互联网的一代,恰逢经济腾飞、消费升级,而且经济水平和消费意识都较前代更强,且Z世代大多还未负担起沉重的现实与家庭压力,付费能力和付费意愿较高,版权意识较上代人显著提升。随着Z世代收入和消费能力的不断增强,中国泛娱乐市场发展前景十分光明。因此通过爬取b站近期热门排行榜得到的数据通过可视化分析可以了解人们的喜好,更方便的定位人们的需求。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称:
爬取bilibili综合热门排行榜及数据分析
2.主题式网络爬虫爬取的内容
爬取近期热门视频的标题,up主,播放数,评论数。
3.主题式网络爬虫设计方案概述
通过页面使用开发者工具找到network中的XHR通过查看Headers了解网页的请求方式,并且获取URL。爬取数据之后,通过执行dict=json.loads(text)操作,把数据转化为字典方便数据提取。通过执行
print(dict)的操作找到所需要爬取的内容,并且将其保存csv文件中。进行数据可视化分析。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
从所需爬取的页面中 , 通过页面使用开发者工具(F12)找到network中的XHR通过查看Headers了解网页的请求方式,并且获取URL(https://api.bilibili.com/x/web-interface/popular?ps=20&pn=1)
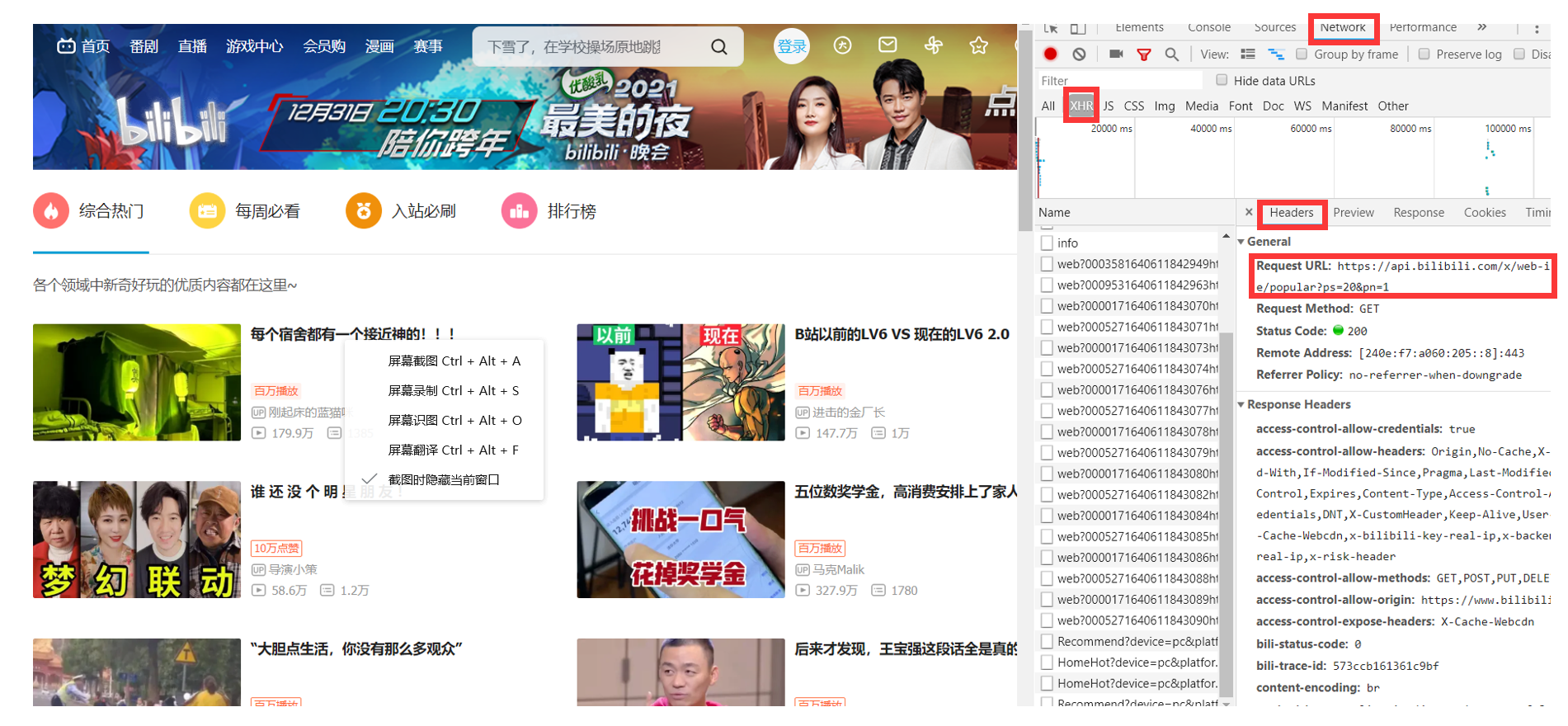

json数据结构
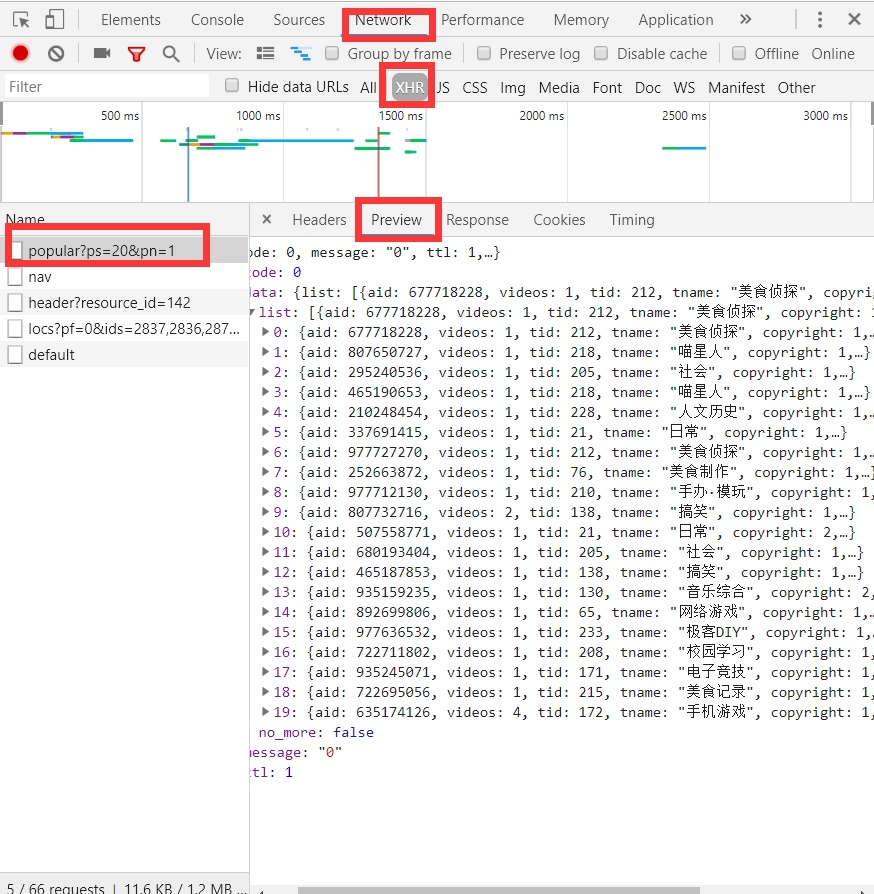
所需要爬取的数据都存放在这个接口里面。
2.页面解析
通过对比参数发现只有'pn'这个参数不同,刷新页面滑到视频的底部,发现'pn'值为11。pn代表页数,所以热门视频共有十一页。下一步开始爬虫。

用json方法把request返回的格式转译为字典,通过执行dict=json.loads(text)操作,这样更方便数据提取。通过执行 print(dict)的操作找到所需要爬取的内容。

(PS:因为动态加载的原因,爬取的内容可能和之后的可视化有点差异,但不影响结果的展示)
3.节点(标签)查找方法与遍历方法
用json方法把request返回的格式转译为字典,从上图输出结果可是看出数据是来自data,list,遍历字典for i in dict['data']['list']:。然后执行print(i)找到这些所需要的key值。后遍历这些key值。

四、网络爬虫程序设计
爬虫程序主体要包括以下各部分。
1.数据爬取与采集
1 #导入所需要的库 2 import requests 3 import json 4 import csv 5 #爬虫部分 6 #1.数据是动态加载的,所以需要寻找数据地址 7 def Get_data(): 8 #处理一个小小的反爬,伪装成浏览器发送请求。 9 header={ 10 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' 11 } 12 url='https://api.bilibili.com/x/web-interface/popular' 13 #从页面分析知道热门数据共有11页 14 for i in range(1,12): 15 #把URL的参数封装成一个字典 16 param={ 17 'ps': 20, 18 'pn': i 19 } 20 res=requests.get(url=url,headers=header,params=param) 21 print(res.text) 22 #Parse(res.text)#下一步需要利用的函数 23 res.close()#关闭对网页的爬取 24 25 if __name__ == '__main__': 26 Get_data()
爬取成功结果截图如下:

2.提取所需的数据,并存储
1 #2.对爬取到的数据进行解析,获取每一条视频数据的标题,Up主,播放量,评论数 2 3 #对所有视频的数据都解析,每一条数据以元组的形式保存在列表中 4 all_data=[] 5 def Parse(text): 6 dict=json.loads(text)#把数据转化为字典方便数据提取 7 # print(dict['data']['list']) 8 9 for i in dict['data']['list']: 10 # print(i['title'])#标题 11 # print(i['owner']['name'])#up主 12 # print(i['stat']['view'])#播放量 13 # print(i['stat']['danmaku'])#评论数 14 15 temp=(i['title'],i['owner']['name'],i['stat']['view'],i['stat']['danmaku']) 16 all_data.append(temp) 17 18 #3.对数据进行保存 19 def Save_data(all_data): 20 with open(r'all_data.csv',mode='w',encoding='utf-8') as fp: 21 writer=csv.writer(fp)#创建一个csv的写对象 22 writer.writerow(['视频名称','up主','播放量','评论数'])#写一行数据作为数据头部 23 for i in all_data: 24 writer.writerow(i)#把all_data的数据写进去 25 26 27 if __name__ == '__main__': 28 Get_data() 29 #print(all_data) 30 Save_data(all_data=all_data) 31
提取数据截图如下图:

生成的csv如下图:
![]()
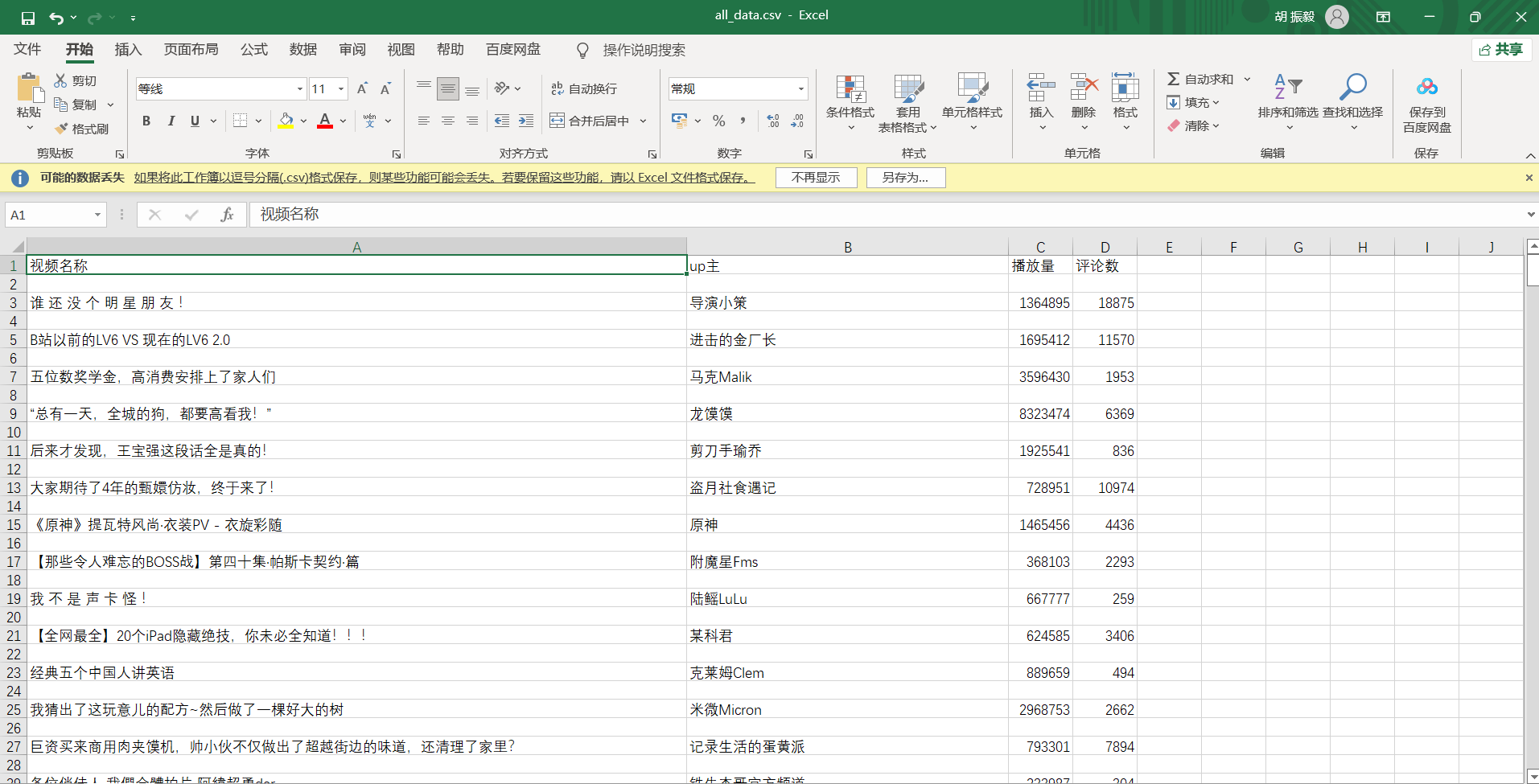
3.数据清洗
获取的数据较完整,没有出现重复和空行情况。故不需要数据清洗。
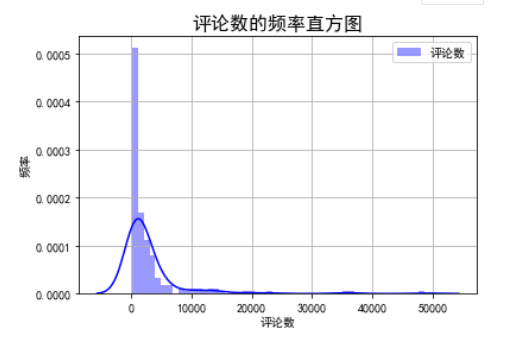
4.绘制频率直方图
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import numpy as np 4 import matplotlib 5 import seaborn as sns 6 from sklearn import datasets 7 from sklearn.linear_model import LinearRegression 8 from sklearn.datasets import load_boston 9 import jieba 10 from pylab import * 11 from wordcloud import WordCloud 12 13 14 #评论数的频率直方图 15 %matplotlib inline 16 plt.rcParams['font.sans-serif'] = ['SimHei'] 17 plt.rcParams['axes.unicode_minus'] = False 18 df=pd.read_csv('C:/Users/10365/Desktop/python期末作业/all_data.csv') 19 plt.figure 20 21 sns.distplot(df['评论数'].values,hist=True, kde=True,axlabel='tip',rug=False,fit=None,hist_kws = {'color':'b','label':'评论数'}, kde_kws={'color':'b'}) 22 plt.title("评论数的频率直方图",fontsize=16) 23 plt.legend() 24 plt.xlabel('评论数') 25 plt.ylabel('频率') 26 plt.grid() 27 28 29 30 #播放量的频率直方图 31 sns.distplot(df['播放量'].values,hist=True, kde=True,axlabel='tip',rug=False,fit=None,hist_kws = {'color':'b','label':'播放量'}, kde_kws={'color':'b'}) 32 plt.title("播放量的频率直方图",fontsize=16) 33 plt.legend() 34 plt.ylabel('') 35 plt.grid()
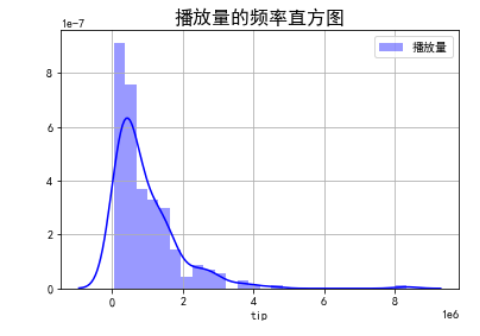
5.绘制柱形图
1 #TOP35的UP主与播放量的柱形图 2 data=np.array(df['播放量'][0:35]) 3 index=np.array(df['up主'][0:35]) 4 print(data) 5 print(index) 6 plt.ylabel('播放量(百万)') 7 8 plt.title("TOP35的UP主与播放量的柱形图",fontsize=16) 9 s = pd.Series(data, index) 10 11 s.plot(kind='bar') 12 plt.savefig('TOP35的UP主与播放量的柱形图.jpg') 13 14 15 16 17 #TOP35的UP主与评论数的柱形图 18 data=np.array(df['评论数'][0:35]) 19 index=np.array(df['up主'][0:35]) 20 print(data) 21 print(index) 22 plt.ylabel('评论数') 23 24 s = pd.Series(data, index) 25 26 plt.title("TOP35的UP主与评论数的柱形图",fontsize=16) 27 28 s.plot(kind='bar') 29 30 #数据持久化 31 plt.savefig('TOP35UP主与评论数的柱形图.jpg')

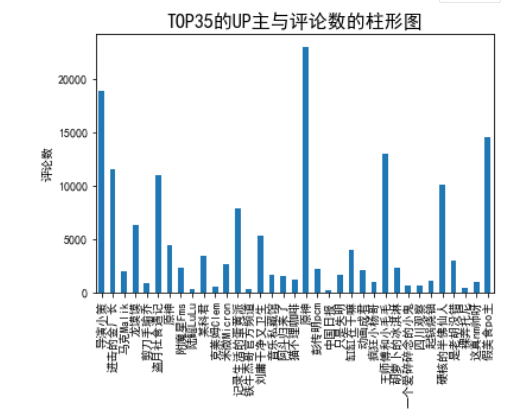
6.绘制散点图
1 #播放量与评论数关系的散点图 2 x=df['播放量'].values 3 4 y=df['评论数'].values 5 6 plt.figure 7 8 size=120 9 10 plt.xlabel('播放量(百万)') 11 12 plt.ylabel('评论数') 13 plt.scatter(x/1,y,size,color='g',label='播放评论关系') 14 plt.legend(loc=2) 15 plt.grid() 16 plt.title("播放量与评论数关系的散点图",fontsize=16) 17 plt.show()
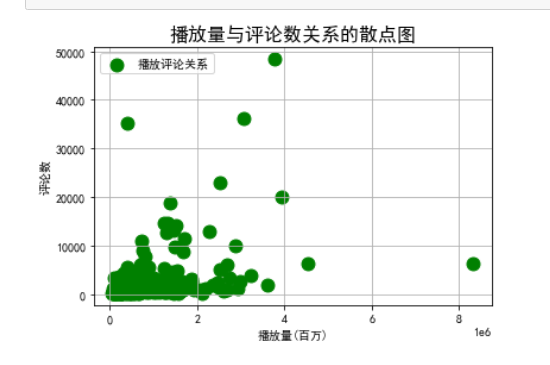
7.数据分析,回归方程
1 #计算回归方程系数和回归方程截距 2 predict_model = LinearRegression() 3 predict_model.fit(x.reshape(-1, 1),y) 4 np.set_printoptions(precision = 3, suppress = True) 5 print("回归方程系数{}".format(predict_model.coef_)) 6 print("回归方程截距{0:2f}".format(predict_model.intercept_)) 7 8 9 10 #播放评论关系回归方程图 11 plt.scatter(x,y,size,color='g',label='播放评论关系') 12 yfit = [809.206980 + 0.002 * xi for xi in x] 13 plt.plot(x, yfit, color="r") 14 plt.ylabel('评论数') 15 plt.xlabel('播放量(百万)') 16 plt.show()

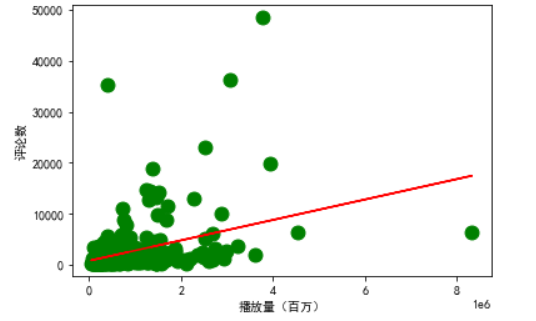
8.绘制词云
1 import jieba 2 from pylab import * 3 from wordcloud import WordCloud 4 text = ' ' 5 a='' 6 df=pd.read_csv('C:/Users/10365/Desktop/python期末作业/all_data.csv') 7 for line in df['视频名称']: 8 a+= line 9 text+=a 10 # 使用jieba模块将字符串分割为单词列表 11 cut_text = ' '.join(jieba.cut(text)) 12 color_mask = imread('C:/Users/10365/Desktop/python期末作业/python截图图片/书本.jpg') #设置背景图 13 cloud = WordCloud( 14 background_color = 'white', 15 # 对中文操作必须指明字体 16 font_path='C:/Windows/Fonts/优设标题黑_猫啃网.ttf', 17 mask = color_mask, 18 max_words = 50, 19 max_font_size = 200 20 ).generate(cut_text) 21 22 # 保存词云图片 23 cloud.to_file('ciwordcloud.jpg') 24 plt.imshow(cloud) 25 plt.axis('off') 26 plt.show()

9.数据持久化
生成CSV文件
![]()
将数据可视化的图片保存成jpg的形式
通过 #例如 plt.savefig('词云.jpg') 实现数据可视化

10.完整代码
1 #导入所需要的库 2 import requests 3 import json 4 import csv 5 6 #爬虫部分 7 #1.数据是动态加载的,所以需要寻找数据地址 8 def Get_data(): 9 header={ 10 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' 11 } 12 url='https://api.bilibili.com/x/web-interface/popular' 13 for i in range(1,12): 14 param={ 15 'ps': 20, 16 'pn': i 17 } 18 res=requests.get(url=url,headers=header,params=param) 19 #print(res.text) 20 Parse(res.text) 21 res.close() 22 23 #2.对爬取到的数据进行解析,获取每一条视频数据的标题,Up主,播放量,评论数 24 25 #对所有视频的数据都解析,每一条数据以元组的形式保存在列表中 26 all_data=[] 27 def Parse(text): 28 dict=json.loads(text)#把数据转化为字典方便数据提取 29 # print(dict['data']['list']) 30 31 for i in dict['data']['list']: 32 # print(i['title'])#标题 33 # print(i['owner']['name'])#up主 34 # print(i['stat']['view'])#播放量 35 # print(i['stat']['danmaku'])#评论数 36 37 temp=(i['title'],i['owner']['name'],i['stat']['view'],i['stat']['danmaku']) 38 all_data.append(temp) 39 40 #3.对数据进行保存 41 42 def Save_data(all_data): 43 with open(r'all_data.csv',mode='w',encoding='utf-8') as fp: 44 writer=csv.writer(fp)#创建一个csv的写对象 45 writer.writerow(['视频名称','up主','播放量','评论数'])#写一行数据作为数据头部 46 for i in all_data: 47 writer.writerow(i)#把all_data的数据写进去 48 49 50 51 if __name__ == '__main__': 52 Get_data() 53 #print(all_data) 54 Save_data(all_data=all_data) 55 56 57 58 #数据可视化部分 59 60 import pandas as pd 61 62 import matplotlib.pyplot as plt 63 64 import numpy as np 65 66 import matplotlib 67 68 import seaborn as sns 69 70 71 #评论数的频率直方图 72 73 %matplotlib inline 74 plt.rcParams['font.sans-serif'] = ['SimHei'] 75 plt.rcParams['axes.unicode_minus'] = False 76 df=pd.read_csv('C:/Users/10365/Desktop/python期末作业/all_data.csv') 77 plt.figure 78 79 sns.distplot(df['评论数'].values,hist=True, kde=True,axlabel='tip', 80 rug=False,fit=None,hist_kws = {'color':'b','label':'评论数'}, 81 kde_kws={'color':'b'}) 82 83 plt.legend() 84 plt.xlabel('评论数') 85 plt.ylabel('频率') 86 plt.grid() 87 88 89 90 #播放量的频率直方图 91 92 sns.distplot(df['播放量'].values,hist=True, kde=True,axlabel='tip',rug=False, 93 fit=None,hist_kws = {'color':'b','label':'播放量'}, 94 kde_kws={'color':'b'}) 95 96 plt.legend() 97 98 plt.ylabel('') 99 100 plt.grid() 101 102 103 104 #播放量与评论数关系的散点图 105 106 x=df['播放量'].values 107 108 y=df['评论数'].values 109 110 plt.figure 111 112 size=120 113 114 plt.xlabel('播放量(百万)') 115 116 plt.ylabel('评论数') 117 plt.scatter(x/1,y,size,color='g',label='播放评论关系') 118 119 plt.legend(loc=2) 120 plt.title("播放量与评论数关系的散点图",fontsize=16) 121 plt.grid() 122 123 plt.show() 124 125 126 #TOP35的UP主与播放量的柱形图 127 128 data=np.array(df['播放量'][0:35]) 129 index=np.array(df['up主'][0:35]) 130 print(data) 131 print(index) 132 plt.ylabel('播放量(百万)') 133 134 plt.title("TOP35的UP主与播放量的柱形图",fontsize=16) 135 s = pd.Series(data, index) 136 137 s.plot(kind='bar') 138 plt.savefig('TOP35的UP主与播放量的柱形图.jpg') 139 140 141 142 #TOP35的UP主与评论数的柱形图 143 144 data=np.array(df['评论数'][0:35]) 145 index=np.array(df['up主'][0:35]) 146 print(data) 147 print(index) 148 plt.ylabel('评论数') 149 150 s = pd.Series(data, index) 151 152 plt.title("TOP35的UP主与评论数的柱形图",fontsize=16) 153 154 s.plot(kind='bar') 155 156 #数据持久化 157 plt.savefig('TOP35UP主与评论数的柱形图.jpg') 158 159 160 161 #数据分析,回归方程 162 163 from sklearn import datasets 164 165 from sklearn.linear_model import LinearRegression 166 167 from sklearn.datasets import load_boston 168 169 import pandas as pd 170 171 172 #计算回归方程系数和回归方程截距 173 174 predict_model = LinearRegression() 175 predict_model.fit(x.reshape(-1, 1),y) 176 np.set_printoptions(precision = 3, suppress = True) 177 print("回归方程系数{}".format(predict_model.coef_)) 178 print("回归方程截距{0:2f}".format(predict_model.intercept_)) 179 180 181 #播放评论关系回归方程图 182 183 plt.scatter(x,y,size,color='g',label='播放评论关系') 184 yfit = [809.206980 + 0.002 * xi for xi in x] 185 plt.plot(x, yfit, color="r") 186 187 plt.ylabel('评论数') 188 189 plt.xlabel('播放量(百万)') 190 191 plt.title("播放评论关系回归方程图",fontsize=16) 192 193 plt.show() 194 195 plt.savefig('播放评论关系回归方程图.jpg') 196 197 198 199 #绘制词云,查看出现最多的词语 200 201 import jieba 202 from pylab import * 203 from wordcloud import WordCloud 204 text = ' ' 205 a='' 206 df=pd.read_csv('C:/Users/10365/Desktop/python期末作业/all_data.csv') 207 for line in df['视频名称']: 208 a+= line 209 text+=a 210 211 # 使用jieba模块将字符串分割为单词列表 212 cut_text = ' '.join(jieba.cut(text)) 213 #设置背景图 214 color_mask = imread('C:/Users/10365/Desktop/python期末作业/python截图图片/书本.jpg') 215 216 cloud = WordCloud( 217 218 background_color = 'white', 219 # 对中文操作必须指明字体 220 font_path='C:/Windows/Fonts/优设标题黑_猫啃网.ttf', 221 mask = color_mask, 222 max_words = 50, 223 max_font_size = 200 224 ).generate(cut_text) 225 226 # 保存词云图片 227 cloud.to_file('ciwordcloud.jpg') 228 plt.imshow(cloud) 229 plt.axis('off') 230 plt.show()
五、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
结论: (1)通过近期热门视频排行榜数据爬取得知播放量最高的up主是龙馍馍,说明人们对这类视频的关注度高
(2)通过近期热门视频排行榜数据爬取并结合词云得知评论数最高的是原神官方账号,说明人们对该视频的讨论激烈。
因为缺少分区等方面的信息,不能更高效的分析出哪类视频在受众方面的情况,不能清楚分析出这些列别视频的受欢迎程度。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
通过爬取bilibili近期热门排行榜,在项目代码编写阶段巩固了基础知识,并且通过网上的视频了解到对爬取页面和解析页面的多种方法,如(requests模块,bs4,json等)所以爬虫方面进展还是比较顺利的。但是由于基础的原因在数据可视化的实现中还是比较吃力的,参考了很多种实现方法。数据可视化这方面进展比较缓慢拉下完成项目的进度。
日后要加强对绘图库的理解与使用,通过各种实战来熟练。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号