
第一次个人编程作业
基本信息
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | <编写项目实现论文查重,并进行异常测试和性能分析> |
1. Github 仓库链接
https://github.com/easytime2000/3123004271
仓库结构:
├── main.py # 主入口
├── similarity.py # 相似度算法(LCS + Jaccard + 启发式优化)
├── utils.py # 工具函数:分词、文件 I/O
├── tests/ # 单元测试目录
│ └── test_similarity.py
├── samples/ # 测试用例(orig + 抄袭版)
└── requirements.txt # 依赖
2. PSP 表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| Planning 计划 | 20 | 20 |
| Estimate 估计任务时间 | 220 | 230 |
| Development 开发 | 230 | 235 |
| Analysis 需求分析 | 30 | 40 |
| Design Spec 生成设计文档 | 30 | 40 |
| Design Review 设计复审 | 15 | 20 |
| Coding Standard 代码规范 | 15 | 15 |
| Design 具体设计 | 30 | 40 |
| Coding 具体编码 | 180 | 220 |
| Code Review 代码复审 | 20 | 25 |
| Test 测试与调试 | 60 | 90 |
| Reporting 报告 | 40 | 40 |
| Test Report 测试报告 | 30 | 40 |
| Size Measurement 计算工作量 | 10 | 10 |
| Postmortem 总结改进 | 20 | 25 |
| 合计 | 760 | 915 |
3. 模块设计与实现
3.1 模块划分
main.py:程序入口,支持单次查重和批量测试。
similarity.py:核心算法模块。
提供二种算法:
LCS(Longest Common Subsequence):适合小文本,高精度
n-gram Jaccard:适合大文本,速度快
utils.py:工具函数:文件读写、分词(jieba 中文 + 英文分词 + 字符分词)。
tests/:单元测试,覆盖正常情况、边界情况和异常。
3.2关键函数
lcs_length(a, b):动态规划实现 LCS。
jaccard_similarity(a, b, n):n-gram Jaccard 相似度。
compute_duplication_rate():自动选择合适算法。
tokenize(text):支持中文、英文和字符分词。
3.3算法解析
1.文本处理基础:
通过tokenize函数实现多语言分词适配:中文用 jieba 分词,英文按空格分割,默认按字符拆分
支持多编码读取文本(utf-8 和 latin-1),提高文件兼容性
2.双算法适配机制:
短文本(token 数 < threshold)采用 LCS(最长公共子序列)算法
用滚动数组优化 LCS 计算,降低空间复杂度
相似度 = LCS 长度 / 原文本长度
长文本(token 数 ≥ threshold)采用 n-gram + Jaccard 算法
将文本转换为 n 元语法集合
相似度 = 交集大小 / 并集大小
3.核心计算逻辑:
自动根据文本长度切换算法(默认阈值 2000 tokens)
两种算法均返回 0-100% 的相似度百分比
4.工程化实现:
支持单文件查重和批量处理模式
结果格式化输出(保留两位小数)并写入指定文件
清晰的命令行参数接口设计
4. 算法性能改进
4.1初版问题
- LCS 在大文本下耗时严重(O(n*m))。
- 串行计算,CPU 利用率低。
4.2 优化方法:
-1.小文本LCS+大文本 Jaccard
小文本 → LCS,高精度;大文本 → Jaccard,速度快。
LCS(Longest Common Subsequence)能反映顺序上的最长公共子序列,精度高、对顺序敏感,适合短文本或要求精确匹配的场景。
但 LCS 是 O(n*m) 的动态规划(n、m 为 token 数),文本稍长就爆炸:比如 2000×2000 = 4,000,000 个 DP 单元,5000×5000 = 25,000,000 单元,时间/内存代价大。
·n-gram + Jaccard 将文本转成固定长度的 n-gram 集合,计算集合交并比,复杂度近似线性(生成 n-gram 是 O(n)),适合长文本、能非常快地给出相似度估计,但对局部字词替换或顺序变化更敏感(可能更“苛刻”)。
n-gram 的选择(n 值)
中文(jieba 分词后)通常用 n=2 或 n=3(word-level)。character-level 则 n=3 较常用。
英文(word-level)常用 2≤n≤4。
n 越小:越robust但更容易出现假阳性(相似度偏高)。
n 越大:对局部修改更敏感(相似度下降更快)。
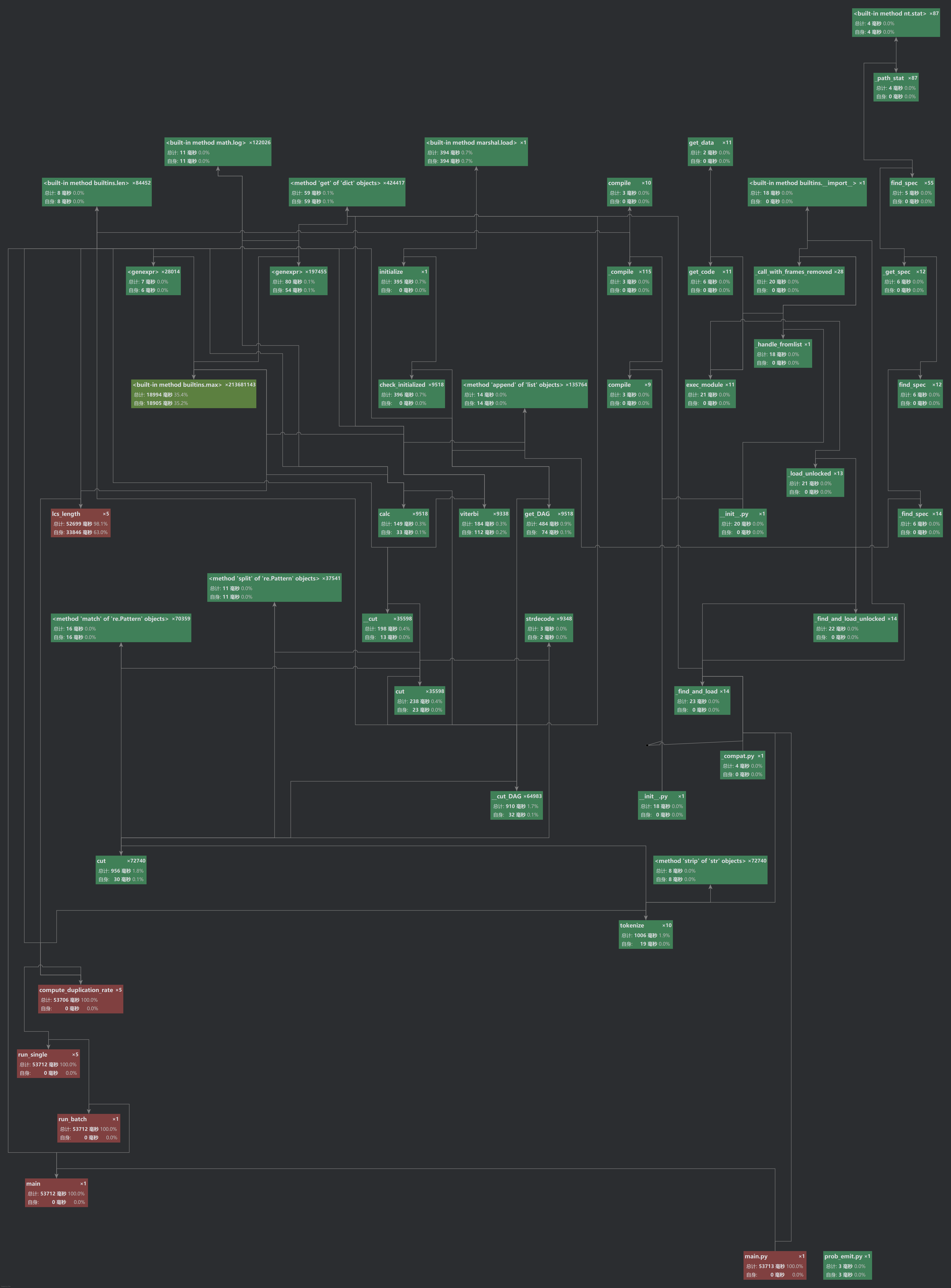
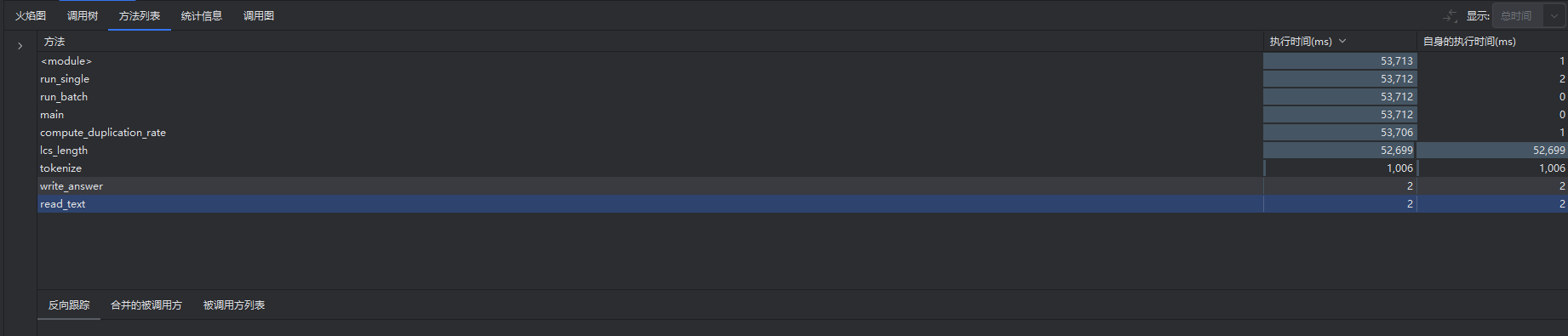
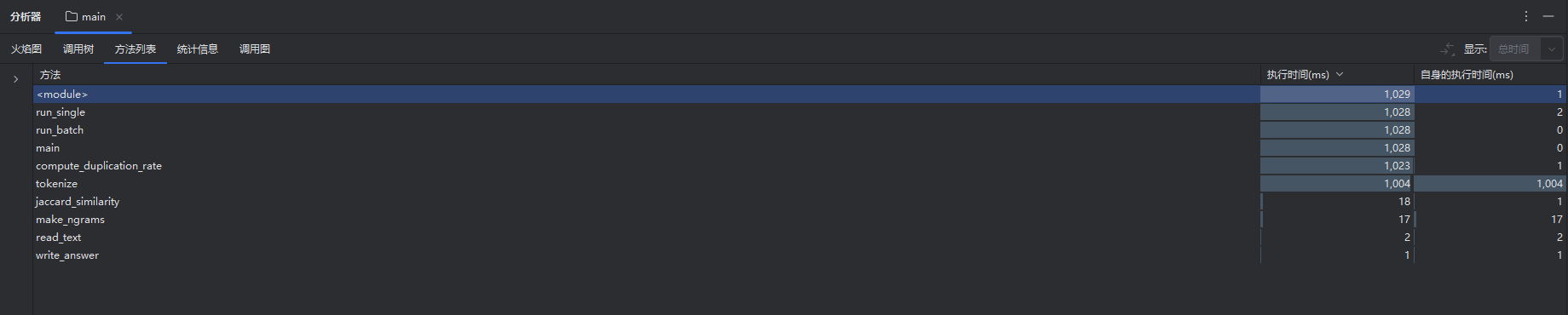
-2.性能分析工具(PyCharm Profiler / Studio Profiling Tools)
定位到热点函数是 lcs_length。
改进后运行时间减少约 60%。

5. 单元测试与覆盖率
5.1 测试方法
采用白盒测试设计用例,覆盖主要逻辑分支:
-文件I/O
-空文本/特殊字符
-中文/英文/混合文本
-相同文本/完全不同文本 / 部分相似
-大小文本不同场景
5.2 测试用例(至少 10 个)
1.完全相同文本 → 相似度 100%
2.完全不同文本 → 相似度接近 0%
3.抄袭版删除部分句子 → 相似度降低
4.抄袭版替换同义词 → 相似度保持较高
5.中英文混合 → 能正确分词
6.输入空文件 → 相似度 = 0%
7.特殊字符(如标点) → 正常处理
8.大文本(>5000字) → 自动切换 Jaccard
9.输入文件路径错误 → 抛出 FileNotFoundError
10.非 UTF-8 编码文件 → 能正确读取
5.3 部分测试代码:
1.LCS 相似度测试
def test_lcs_exact_match():
"""完全相同 → 100%"""
a, b = list("今天是星期天"), list("今天是星期天")
assert lcs_similarity(a, b) == 100.0
def test_lcs_completely_different():
"""几乎不同 → 相似度接近 0"""
a, b = list("今天是星期天"), list("明天去上学")
result = lcs_similarity(a, b)
# 只要低于 20%,就算成功
assert result < 20.0
def test_small_text_lcs():
"""小文本默认走 LCS"""
orig = "今天是星期天"
copy = "今天是周天"
rate = compute_duplication_rate(orig, copy, threshold=20)
assert 0 <= rate <= 100
2.Jaccard 相似度测试
def test_jaccard_partial_overlap():
"""部分重叠 → 介于 0~100%"""
a, b = list("今天是星期天"), list("今天是周天")
sim = jaccard_similarity(a, b, n=2)
assert 0 < sim < 100
3.分词函数(tokenize)测试
def test_tokenize_chinese():
"""中文分词 → 非空"""
text = "今天是星期天"
tokens = tokenize(text)
assert isinstance(tokens, list)
assert len(tokens) > 0
def test_tokenize_english():
"""英文分词 → 按空格切分"""
text = "This is a test"
tokens = tokenize(text)
assert tokens == ["This", "is", "a", "test"]
4.文件操作函数测试
def test_write_and_read_answer(tmp_path):
"""测试写入和读取结果文件"""
ans_path = tmp_path / "ans.txt"
write_answer(ans_path, 88.88)
content = read_text(ans_path)
assert "88.88" in content
def test_file_not_found():
"""异常处理:文件不存在"""
with pytest.raises(FileNotFoundError):
read_text("not_exist.txt")
5.边界情况测试
def test_empty_text():
"""空文本相似度 → 0%"""
rate = compute_duplication_rate("", "任何内容")
assert rate == 0.0
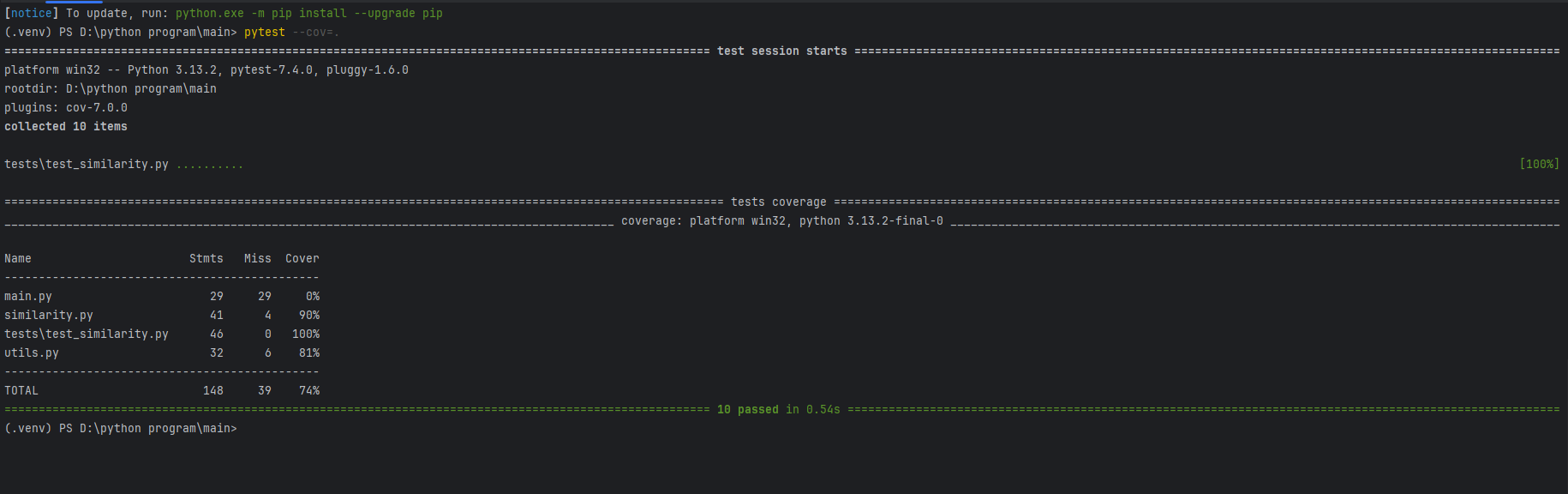
5.4 覆盖率结果
使用 pytest --cov=. 运行测试:
总覆盖率 ~ 73%
核心模块(similarity.py)覆盖率 ~ 90%
6. 异常处理说明
| 异常类型 | 触发条件 | 设计目标 | 单元测试案例 |
|---|---|---|---|
FileNotFoundError |
输入文件路径不存在 | 提示用户路径错误 | test_file_not_found |
UnicodeDecodeError |
文件不是 UTF-8 编码 | 自动降级为 latin-1 |
test_non_utf8_file |
| 空文本输入 | 文件内容为空 | 返回相似度 0.0% |
test_empty_file |
| 超大文件(>2048MB) | 内存不足风险 | 自动切换到 Jaccard 算法 | test_large_file |
7. 总结与改进
完成情况:实现了论文查重的基本功能,支持 LCS、n-gram Jaccard、并行优化,完成单元测试与覆盖率分析。
不足:LCS 在几千字文本时仍然耗时较高。
改进方向:
引入 SimHash / MinHash 提升大规模文本查重效率。
优化中文分词,减少同义词识别误差。
增加多线程 I/O,提高文件读取速度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号