
Scrapy学习(一)、Scrapy框架和数据流
Scrapy是用python写的爬虫框架,架构图如下:
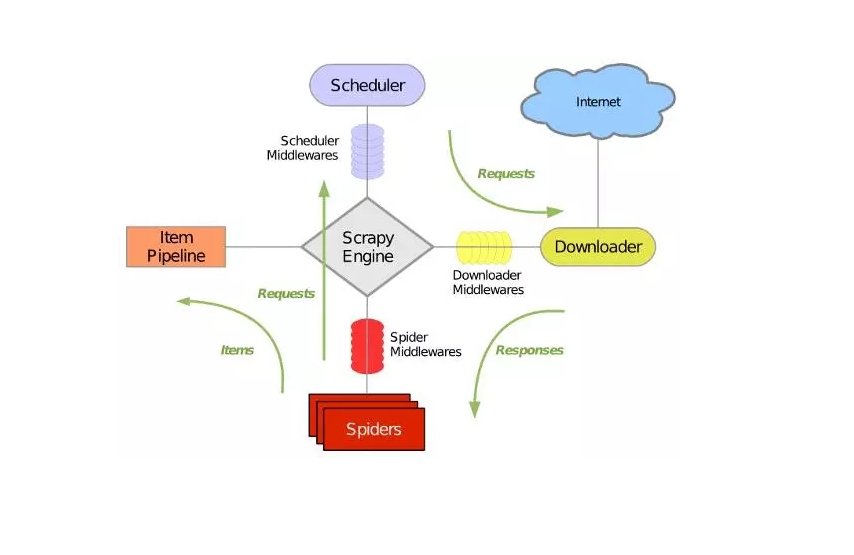
它可以分为如下七个部分:
1、Scrapy Engine:引擎,负责控制数据流在系统的所有组件中流动,并在相应动作发生时触发时间。
2、Scheduler:调度器,从引擎接收Request并将它们入队,以便引擎再次请求Request时提供给引擎。
3、Downloader:下载器,负责获取页面数据并提供给引擎,而后提供给Spiders。
4、Spider:爬虫,定义爬虫逻辑和解析规则,主要负责解析Response并生成提取结果(item)和新的请求(Request)。
5、Item Pipeline:管道,负责处理右Spider提取出来的结果(item)。主要任务是清洗,验证和存储数据。
6、Downloader middlewares:下载器中间件,位于引擎和下载器之间的特定钩子,处理引擎传给下载器的Request以及下载器传给引擎的Response。
7、Spider middlewares:爬虫中间件,位于引擎和爬虫之间的特定钩子,主要处理爬虫的输入(Response)和输出(Item和Request)
具体数据流如下:
1、引擎(Scrapy Engine)打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取的URL
2、引擎(Scrapy Engine)从Spider中获取到第一个要爬取的URL后,通过调度器(Scheduler)以Request的形式调度
3、引擎(Scrapy Engine)向调度器(Scheduler)请求下一个要爬取的URL
4、调度器(Scheduler)返回下一个要爬取的URL给引擎(Scrapy Engine),引擎将该URL通过下载中间件(Downloader middlewares)转发给下载器(Downloader)
5、下载器(Downloader)下载页面,一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(Downloader middlewares)发送给引擎
6、引擎(Scrapy Engine)从下载中间件(Downloader middlewares)接收Response,并将其通过爬虫中间件(Spider middlewares)发送给爬虫(Spider)处理
7、爬虫(Spider)处理Response,并返回处理的Item及新的Request给引擎
8、引擎(Scrapy Engine)将爬虫(Spider)返回的Item给管道(Item Pipeline),将新的Request给调度器(Scheduler)
9、重复第2步到第8步,直到调度器(Scheduler)中没有更多的Request,引擎(Scrapy Engine)关闭该网站,爬虫结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号