
Python作业1:Scrapy爬取学堂在线+链家二手房
python作业1:爬取学堂在线+链家二手房
一、爬取学堂在线
1、要求
爬取学堂在线的计算机类课程页面内容。
要求将课程名称、老师、所属学校和选课人数信息,保存到一个csv文件中。
链接:
https://www.xuetangx.com/search?query=&org=&classify=1&type=&status=&page=1
2、实验过程
准备阶段
- 通过查看网页源代码,可以看到源代码中没有相关内容,于是刷新页面,在network中查看获取的页面信息,得到以下内容:
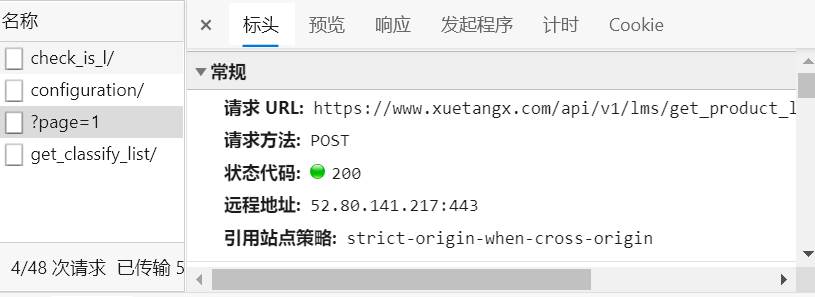
-
可知该页面具体数据由前端通过ajax请求后端获得,需要创建POST请求来爬取页面数据;
-
再查看network中的页面内容,获得请求标头用于创建爬虫:
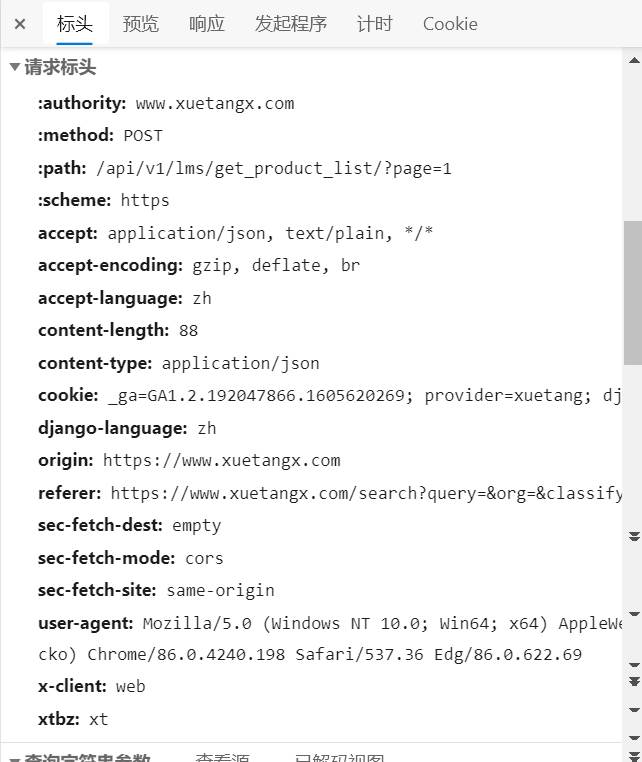
- 同时,要了解该页面数据结构需要进一步查看预览中的msg:
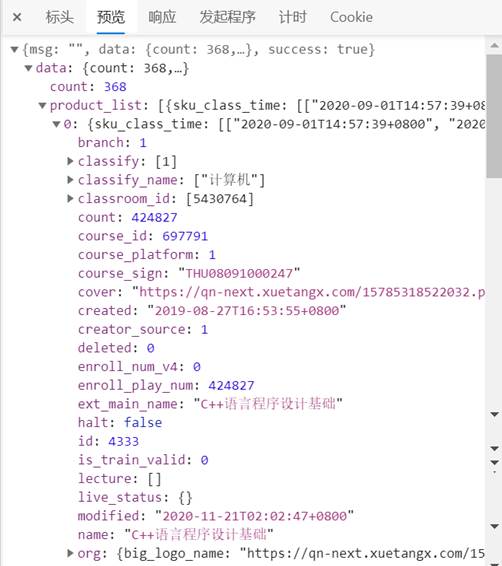
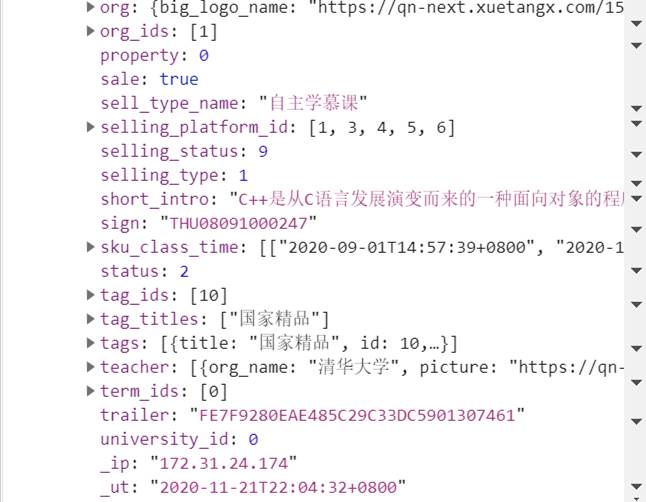
- 从[4]中的截图可以获得我们要爬取的数据存在的地方:
-
课程名称:msg['data']['product_list']['name']
-
老师:msg['data']['product_list'] ['teacher'] ['name']
-
学校:msg['data']['product_list'] ['org']['name']
-
选课人数:msg['data']['product_list'] ['count']
代码编写
- item.py:
import scrapy
class StudyhallItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() # 课程名
teacher = scrapy.Field() # 老师
school = scrapy.Field() # 学校
peopleNum = scrapy.Field() # 选课人数
pass
- settings.py新增一行:
ITEM_PIPELINES =
- pipelines.py:
from itemadapter import ItemAdapter
import csv
class StudyhallPipeline(object):
def open_spider(self, spider):
try:
"""打开csv文件"""
self.file = open('StudyHallData.csv', 'w', encoding='utf-8', newline = '')
self.csv = csv.writer(self.file)
except Exception as e:
print(e)
def process_item(self, item, spider):
self.csv.writerow(list(item.values()))
return item
def close_spider(self, spider):
self.file.close()
- 最后是spider文件,其中headers是直接从浏览器network复制下来,确保无误,不过由于我复制下来的headers没有'Host'信息,所以新加了一项:'Host': 'www.xuetangx.com';由于要创建POST请求,需要重写start_requests函数,并且爬取前五页数据,所以使用for循环创建5个FormRequest(),其中FormRequest的参数有:url、headers、method、body、callback;最后是parse函数,根据之前的截图获取对应数据,此处不再赘述。
import scrapy
import json
from pprint import pprint
from studyHall.items import StudyhallItem
class studyHallSpider(scrapy.spiders.Spider):
name = 'studyHall'
allowed_domains = ['www.xuetangx.com/']
url_pat = 'https://www.xuetangx.com/api/v1/lms/get_product_list/?page={}'
"""data从浏览器中查看得来"""
data = '{"query":"","chief_org":[],"classify":["1"],"selling_type":[],"status":[],"appid":10000}'
"""标头从浏览器中复制"""
headers = {
'Host': 'www.xuetangx.com',
'authority': 'www.xuetangx.com',
'method': 'POST',
'path': '/api/v1/lms/get_product_list/?page=1',
'scheme': 'https',
'accept': 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh',
'content-type': 'application/json',
'cookie': '_ga=GA1.2.192047866.1605620269; provider=xuetang; django_language=zh',
'django-language': 'zh',
'origin': 'https://www.xuetangx.com',
'referer': 'https://www.xuetangx.com/search?query=&org=&classify=1&type=&status=&page=1',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36 Edg/86.0.622.69',
'x-client': 'web',
'xtbz': 'xt'
}
def start_requests(self):
"""使用start_requests创建post请求"""
for page in range(1, 6):
"""爬取5页信息"""
yield scrapy.FormRequest(
url = self.url_pat.format(page),
headers = self.headers,
method = 'POST',
body = self.data,
callback = self.parse
)
def parse(self, response):
msg= json.loads(response.body)
for each in msg['data']['product_list']:
item = StudyhallItem()
item['name'] = each['name']
item['school'] = each['org']['name']
item['peopleNum'] = each['count']
teacherList = []
# 因为有些课程有多个老师,需要逐一保存,写入一条记录
for teacher in each['teacher']:
teacherList.append(teacher['name'])
item['teacher'] = ','.join(teacherList)
yield item
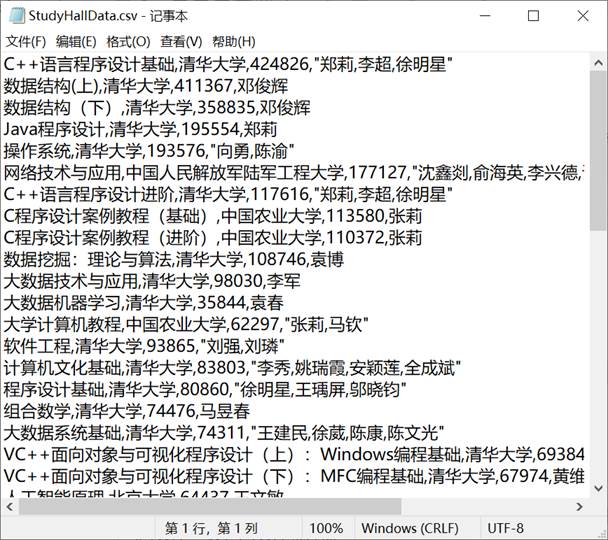
3、爬取结果
截取一部分爬取的数据如下:
二、爬取链家官网
1、要求
爬取链家官网二手房的数据 https://bj.lianjia.com/ershoufang/
要求爬取北京市东城、西城、海淀和朝阳四个城区的数据(每个区爬取5页),将楼盘名称、总价、平米数、单价保存到json文件中。
2、实验过程
准备阶段
- 打开网页,查看网页源代码,可以看到在源代码中间已经包含了二手房信息,说明页面由后端渲染完毕后返回到浏览器,这样可以通过xpath来爬取相关内容。
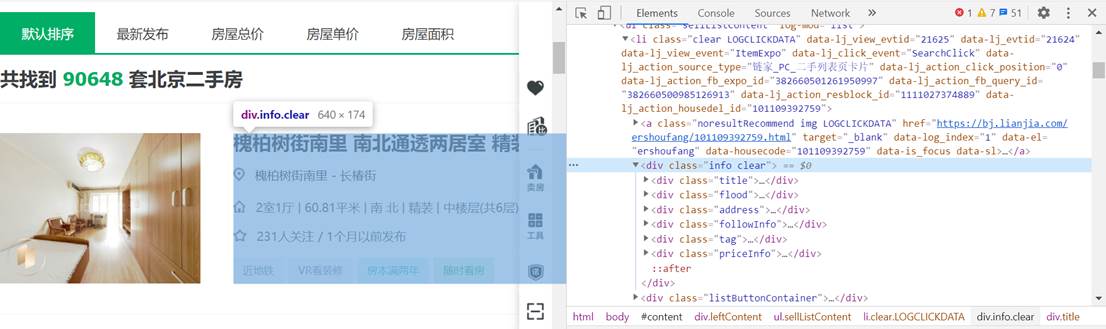
- xpath可以直接从源代码中复制得到,如下图:
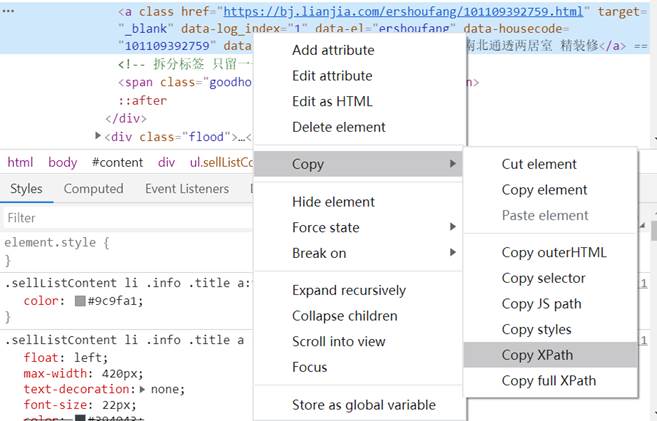
- 由[2],我们只需要在源代码中查看我们需要的数据所在位置,复制其xpath便可爬取到数据:楼盘名称、总价、平米数、单价;至于东城、西城、海淀、朝阳四个城区,观察对应url可知不同城区和不同页只是在后缀加上其拼音,如图:


代码编写
- item.py:
import scrapy
class HomelinkItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
location = scrapy.Field() # 城区
name = scrapy.Field() # 名称
area = scrapy.Field() # 面积
TTprice = scrapy.Field() # 总价
UnitPrice = scrapy.Field() # 单价
- settings.py(加入了一段反爬虫代码,虽然貌似并不需要):
BOT_NAME = 'homeLink'
SPIDER_MODULES = ['homeLink.spiders']
NEWSPIDER_MODULE = 'homeLink.spiders'
ITEM_PIPELINES = {'homeLink.pipelines.HomelinkPipeline': 300,}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'homeLink (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
"""对付反爬虫"""
import random
# user agent 列表
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
# 随机生成user agent
USER_AGENT = random.choice(USER_AGENT_LIST)
- 最后是spider文件,这里为了获得精准详细的数据,对数据进行了筛选和添加:比如楼盘面积,源代码中的数据冗杂,这里去除了不需要的元素:
import scrapy
from homeLink.items import HomelinkItem
import json
class MySpider(scrapy.Spider):
name = 'homeLink'
allowed_domains = ['bj.lianjia.com']
start_urls = ['https://bj.lianjia.com/ershoufang/dongcheng/']
start_urls = []
locations = ['dongcheng', 'xicheng', 'haidian', 'chaoyang'] # 四个城区
for loc in locations:
for page in range(1, 6):
"""东城前五页"""
url = "https://bj.lianjia.com/ershoufang/{}/pg{}/".format(loc, page)
start_urls.append(url)
def parse(self, response):
item = HomelinkItem()
for each in response.xpath("//div[@id='content']/div[1]/ul/*"):
"""爬取该路径下的房区信息"""
"""楼盘地理位置"""
if (response.url.split('/')[-3] == 'dongcheng'):
item['location'] = '东城'
elif (response.url.split('/')[-3] == 'xicheng'):
item['location'] = '西城'
elif (response.url.split('/')[-3] == 'haidian'):
item['location'] = '海淀'
elif (response.url.split('/')[-3] == 'chaoyang'):
item['location'] = '朝阳'
"""获取楼盘名称"""
item['name'] = each.xpath("./div[1]/div[@class='title']/a/text()").extract()
"""获取楼盘面积/平米"""
item['area'] = each.xpath("./div[1]/div[@class='address']/div/text()").extract()[0].split(' | ')[1]
"""获取楼盘总价,以万为单位结尾"""
item['TTprice'] = str(each.xpath("./div[1]/div[@class='priceInfo']/div[1]/span/text()").extract()[0]) + '万'
"""获取楼盘单价"""
item['UnitPrice'] = each.xpath("./div[1]/div[@class='priceInfo']/div[2]/span/text()").extract()
if (item['name'] and item['area'] and item['TTprice'] and item['UnitPrice']):
"""去掉值为空的数据"""
yield(item) # 将item返回到pipelines模块
else:
print('---------ERROR-----------', item['name'])
3、爬取结果
由于数据量巨大(600组数据),这里仅展示其中一部分:





 浙公网安备 33010602011771号
浙公网安备 33010602011771号