
Negotiating Team Formation Using Deep Reinforcement Learning
背景:
多个智能体在环境中交互时(主要是模仿人类的团队行为例如篮球比赛等,只有通过合作才能够达到一定的目的),通常是需要合作从而实现最终目标,即达到最佳总收益。一般来说,实现上述目标的方法是组建一个团队并且需要制定一定的团队规则并实施,才能保证团队的运行,最重要的是要考虑到其中某些智能体的背叛行为导致团队收益受损。
提出的问题:
现有的组成团队以及团队收益分配方式仅适用于特定的协商规则,更一般的方法则通常是有一些例如繁琐限制存在的因此无法广泛应用。
问题的解决:
基于上述的问题,文中提出了一个框架使用智能体强化学习的方式在多智能体深度学习过程中能够进行谈判最终形成团队。其优势在于不需要任何前提,相比于传统的方法,这个方法更加的简单化,完全由训练过程中的经验驱动。
- 基于上述框架,该篇论文对其在一定环境下进行了评估证明其对比与传统基于博弈合作方法的优越性以及合理性
- 同时对团队形成过程中的一些影响因素进行了评估
主要工作:
- 实验环境:多个代理初始分配一定的权重w,代理的目标是形成一个团队总权重大于等于q,如果成功组团则整个团队得到固定的奖励r,组成团队的代理人必须进行奖励的分配,最终只选择一个可行的团队,其余成员奖励0.(博弈过程就是是否接受当前低奖励的分配选择组团,或者选择放弃当前机会寻求其他组团机会,但是可能面临组团失败奖励为0)
- 实验过程:每个代理轮流提议,如果所有人接受该提议则终止,否则以概率p随机选择下一个提议者。
- 环境升级:基于上述实验环境升级为空间环境,具体来说就是变成二维的有方格的地图,初始代理在中间,有上下左右四个动作,到达同一个方块的代理可以组队,到达时有最低需求奖励r以及自身所带权重w,一旦方块内所有代理权重和超过q以及需求奖励和满足该方块所给的奖励则该方块内的代理进行组队。
-
- RL实验:初始将环境以及代理动作空间奖励和权重定义好,然后使用强化学习算法让每个智能体开始独立学习。
- 实验结果:与传统的博弈论方案进行了对比,得到该方案能够达到最优解,并且在某些时刻团队中智能体的奖励要优于传统方法。
- 对结果的奖励值进行公平性评估,用shapley值(衡量公平性的)
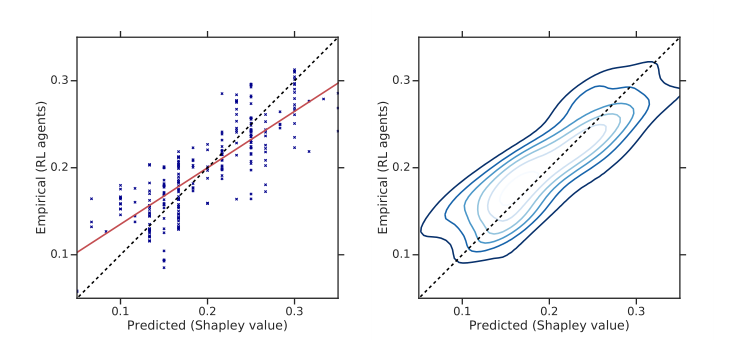
可以看到文中方法得到的奖励分部基本都靠近shapley值,代表了其分配的合理性 - 与传统的博弈论方案进行了对比,得到该方案能够达到最优解,并且在某些时刻团队中智能体的奖励要优于传统方法。
- 对结果的奖励值进行公平性评估,用shapley值(衡量公平性的)
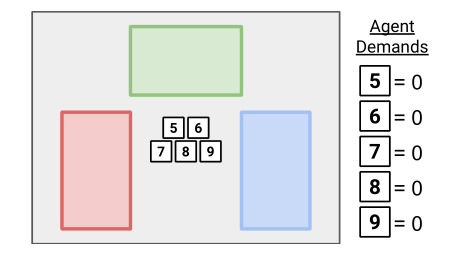
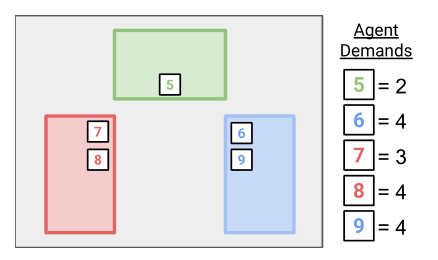
结论:
- 基于强化学习的框架可以更好的适应各种不同的团队形成场景例如空间扩展,并且最终结果相比于传统的方法甚至更优且不需要人工数据减少了资源耗费。
- 缺点:基于强化学习在缩减数据成本的同时导致了计算成本的激增,导致在复杂环境很可能无法很好得实施

 浙公网安备 33010602011771号
浙公网安备 33010602011771号