
深度学习之路一 前向反馈和反向传播的初步雏形
#coding: utf8 import math # x1, x2输入神经元 x1=1 x2=2 # w1,w2分别为x1,x2的权重 w1=0.2 w2=0.3 # b为输出神经元的偏移量 b = 0.1 target = 1 # 目标值 def f(w1, w2, b): return x1 * w1 + x2 * w2+ b def loss(x, target): return (target - x) ** 2 def printInfo(): print('w1:', w1) print('w2:', w2) print('b:', b) o1 = f(w1, w2, b) print('f(w1, w2, b):', o1) o1 = math.tanh(o1) print('激活输出:', o1) print('损失值:', loss(o1, target)) print('----------------') printInfo() # 核心问题:如果降低损失? 其实就是让损失函数的输出变小 # 那么就变成数学题了,如何求一个函数的极小值 # 数学理论: # 要求一个函数的极小值,可以使用求导数的方法,具体步骤如下: # 1. 对函数进行求导,得到其导函数。 # 2. 将导函数等于0的解作为函数的极值。 # 3. 判断左正右负极大值,左负右正极小值 # 根据上面的步骤操作 # 第1步: loss 的导函数 def lossGrad(x): # return -2*(1-x) return 2*x-2 # 第2步 lossGrad(x) = 0 ->解得 x = 1 # 第3步 lossGrad(0)=-2 lossGrad(2)=2 属于左负右正极小值,那么x=1时loss函数有极小值 # 其实第三步还有一个小技巧,就是对lossGrad再次求导,得到常数2。 大于0就是极小值。 不懂的同学可以补习下这块知识 # 回到核心问题,如果降低损失? 目标变成了怎么让x=1. 即怎么让tanh的值为1, 可惜tanh的值域不包括1, 那么我们尽可能接近它 # 我们求反函数就可以知道,math.atanh(0.9999) = 4.9517 # 现在问题就又变成了 如何让 x1*w1 + x2*w2 + b = 4.9517 # 其实就是怎么调整 w1 w2 和 b 三个变量的值,使其尽可能输出向4.9517靠拢 # 目标:f(w1, w2, b) = 4.9517 看到这个玩意我知道有很多解,但是没法直接求,所以只能一点一点迭代接近它了。后面训练网络模型的时候其实就是调整所有的w和b # 一个三元函数怎么接近这个4.9517它, 又变成一个数学问题, 求这个三元函数的导函数(也就是偏导数) # 这个分别求导得到: def fGradW1(): return x1 def fGradW2(): return x2 def fGradB(): return 1 # 根据求导结果可知,导函数都是常数 # 当前的损失值 lossTmp = f(w1, w2, b) - 4.9517 print('当前损失值:', lossTmp) w1 = w1 - 0.01 * fGradW1() * lossTmp w2 = w2 - 0.01 * fGradW2() * lossTmp b = b - 0.01 * fGradB() * lossTmp lossTmp = f(w1, w2, b) - 4.9517 print('当前损失值:', lossTmp) w1 = w1 - 0.01 * fGradW1() * lossTmp w2 = w2 - 0.01 * fGradW2() * lossTmp b = b - 0.01 * fGradB() * lossTmp lossTmp = f(w1, w2, b) - 4.9517 print('当前损失值:', lossTmp) w1 = w1 - 0.01 * fGradW1() * lossTmp w2 = w2 - 0.01 * fGradW2() * lossTmp b = b - 0.01 * fGradB() * lossTmp lossTmp = f(w1, w2, b) - 4.9517 print('当前损失值:', lossTmp) w1 = w1 - 0.01 * fGradW1() * lossTmp w2 = w2 - 0.01 * fGradW2() * lossTmp b = b - 0.01 * fGradB() * lossTmp lossTmp = f(w1, w2, b) - 4.9517 print('当前损失值:', lossTmp) printInfo() # 从前面几次迭代可以看出,损失值在不断减小 # 现在把这个迭代过程分装成一个函数 def train(n): global w1, w2, b for i in range(n): lossTmp = f(w1, w2, b) - 4.9517 w1 = w1 - 0.01 * fGradW1() * lossTmp w2 = w2 - 0.01 * fGradW2() * lossTmp b = b - 0.01 * fGradB() * lossTmp train(100) printInfo()
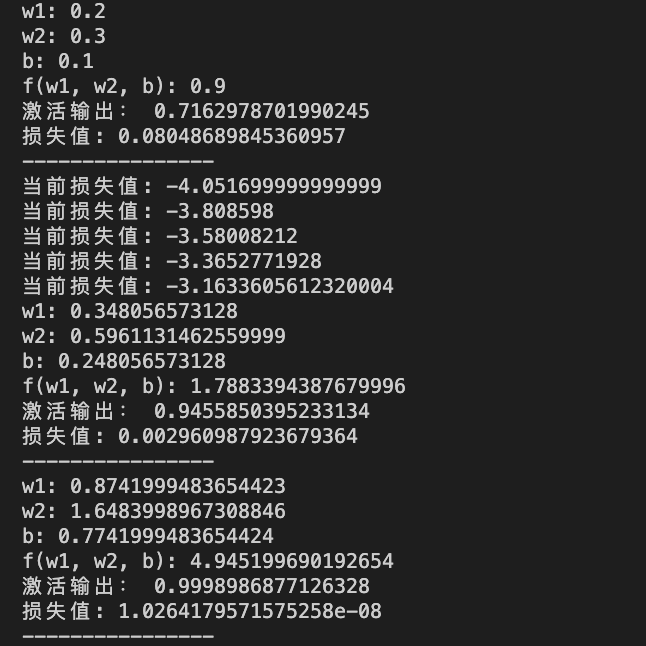
从结果看出已经损失值已经无限接近0了, 还是非常完美, 这个是数学分析后,一点一点拼凑出来的代码,下一篇将对这个代码进行归纳

 浙公网安备 33010602011771号
浙公网安备 33010602011771号