
torch 对网络进行训练常用的方法
激活函数:将神经网络上一层的输入,经过神经网络层的非线性变换转换后,通过激活函数,得到输出。
神经网络中的每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,并将输入值传递给下一层,输入层神经元节点会将输入属性值直接传递给下一层(隐层或输出层)。在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数(又称激励函数)。
1. Sigmoid
sigmoid函数的数学形式为f(x) = 1/(1+e**-x),导数为f(x)(1-f(x))。 e**-x 表示 e的-x次方

值域:(0,1)
(1)当输入很大或很小,饱和的神经元会带来梯度消失(Gradient Vanishing);
(2)函数的输出不是以0为对称的(zero-centered)(解释);
(3)使用指数函数,计算代价有点高。
使用示例: sig = nn.Sigmoid() print(sig(input))
2. tanh
tanh函数的数学形式为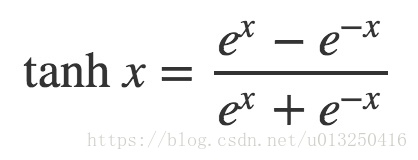
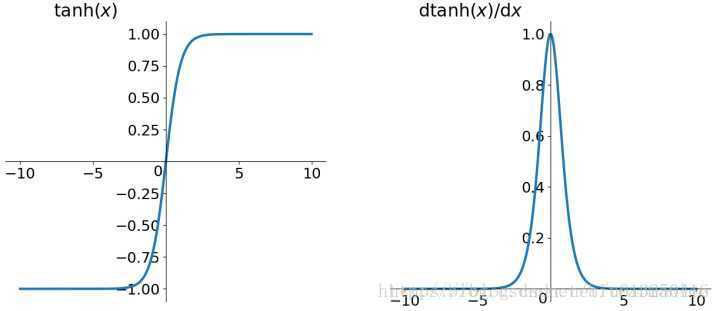
值域:(-1,1)

- 优点1:Krizhevsky et al. 发现使用 ReLU 得到的SGD的收敛速度会比 sigmoid/tanh 快很多。有人说这是因为它是linear,而且梯度不会饱和
- 优点2:相比于 sigmoid/tanh需要计算指数等,计算复杂度高,ReLU 只需要一个阈值就可以得到激活值。
- 缺点1: ReLU在训练的时候很”脆弱”,一不小心有可能导致神经元”坏死”。举个例子:由于ReLU在x<0时梯度为0,这样就导致负的梯度在这个ReLU被置零,而且这个神经元有可能再也不会被任何数据激活。如果这个情况发生了,那么这个神经元之后的梯度就永远是0了,也就是ReLU神经元坏死了,不再对任何数据有所响应。实际操作中,如果你的learning rate 很大,那么很有可能你网络中的40%的神经元都坏死了。 当然,如果你设置了一个合适的较小的learning rate,这个问题发生的情况其实也不会太频繁。
relu的导数是分段计算的,小于0的时候导数是0,大于0的时候导数是1, 等于0时理论上不可导,但是torch和tensorflow框架 是按0处理的
使用方式: relu = nn.ReLU(inplace=True) print(relu(input)) inplace=True 表示修改输入值,即小于0的数据,全部设置为0
API文档跳转: https://pytorch.org/docs/master/generated/torch.nn.ReLU.html
升级版本:Leaky Relu
f(x) = max(ax, x) 其中a是指定的, 通过negative_slope参数
relu函数0点不可导, Leaky Relu函数解决了0点不可导这个问题。
使用示例:lkrelu = nn.LeakyReLU(negative_slope=0.1, inplace=False) print(lkrelu(input))
API文档跳转: https://pytorch.org/docs/master/generated/torch.nn.LeakyReLU.html
升级版本: RReLU
随机的Leaky Relu版本。
f(x) = max(ax, x) 其中a是范围内随机的
使用示例: m = nn.RReLU(0.1, 0.3) m(input) a 在 0.1和0.3之间随机,不包含0.1和0.3
升级版本:PReLU
可以学习的Leaky Relu版本。
PReLU(x)=max(0,x)+a∗min(0,x)
这里的a是可以学习的,
使用示例: m=nn.PReLu(num_parameters=2, init =0.5) num_parameters表示指定通道数, init表示a的初始值
num_parameters 只有两个值可以取。 1或者某一维长度。 如果数据:[ [1,2,3] ,[1,2,3] ,[1,2,3], [1,2,3]] 通道数相当于二维数组的长度
则num_parameters只能是1和3. 参数传1表示一个a贯穿所有通道。 一个通道相当于是[1,2,3] 。 通道长度为3, 如果传入的是3,则每个通道分别用不同的a
使用示例: prelu = nn.PReLU(4,init=0.1) print(prelu(input)) print(prelu.weight)
有一个疑问: 不知道这个权重是自己定义规则更新还是框架自动完成的。 神经元之间的权重是反向传播更新的,不知道这个在哪个阶段完成。
4: softplus:
Softplus(x)=β1∗log(1+exp(β∗x))
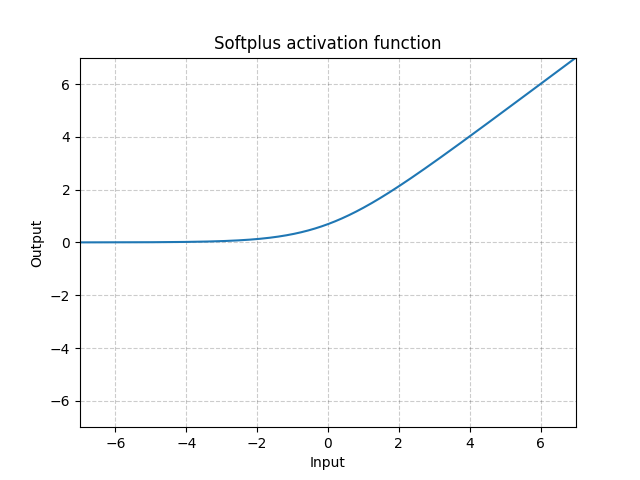
API文档跳转: https://pytorch.org/docs/master/generated/torch.nn.Softplus.html#torch.nn.Softplus
5. maxout
f(x) = (w1x+b, w2x+b)
6. LogSigmoid
LogSigmoid(x)=log(1+exp(−x)1)
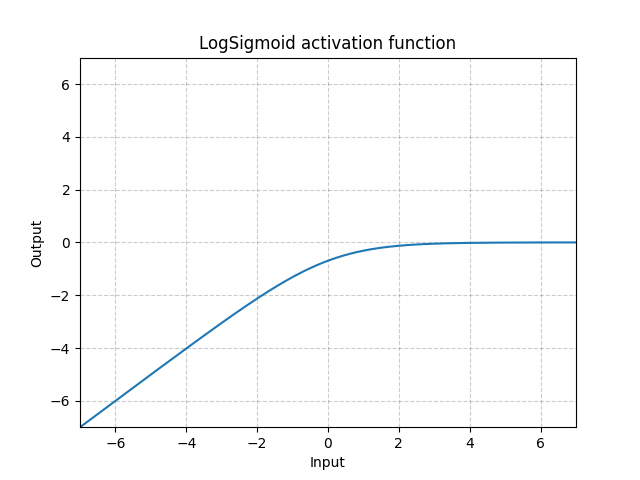
API文档跳转:https://pytorch.org/docs/master/generated/torch.nn.LogSigmoid.html#torch.nn.LogSigmoid
损失函数:度量神经网络的输出的预测值,与实际值之间的差距的一种方式。
文档地址: https://pytorch.org/docs/master/nn.html#loss-functions
优化函数:也就是如何把损失值从神经网络的最外层传递到最前面。如最基础的梯度下降算法,随机梯度下降算法,批量梯度下降算法,带动量的梯度下降算法,Adagrad,Adadelta,Adam等。
SGD:实现随机梯度下降(可选带动量)
https://pytorch.org/docs/master/optim.html#torch.optim.SGD
Adam:
https://pytorch.org/docs/master/optim.html#torch.optim.Adam
Adamax:
https://pytorch.org/docs/master/optim.html#torch.optim.Adamax
RMSprop: 实现在添加epsilon之前取梯度平均值的平方根
https://pytorch.org/docs/master/optim.html#torch.optim.RMSprop
Rprop: 弹性反向传播算法
https://pytorch.org/docs/master/optim.html#torch.optim.Rprop
LambdaLR: 将每个参数组的学习率设置为给定函数的初始lr倍。当last_epoch = -1时,将初始lr设置为lr。
https://pytorch.org/docs/master/optim.html#torch.optim.lr_scheduler.LambdaLR

 浙公网安备 33010602011771号
浙公网安备 33010602011771号