
BUAA_OO_第一单元总结与反思
BUAA_OO_第一单元总结与反思
摘要
本单元有三次作业,作业题目就是,输入一个表达式字符串,对这个字符串进行处理,要求输出被去掉括号的表达式字符串。下面说明各次作业的因子类型。
- Homework1:
- 变量因子
- 幂函数
- 一般形式 由自变量 x,指数符号
**和指数组成,指数为一个非负带符号整数,如:x ** +2。 - 省略形式 当指数为 1 的时候,可以省略指数符号
**和指数,如:x。
- 一般形式 由自变量 x,指数符号
- 幂函数
- 常数因子 包含一个带符号整数,如:
233。 - 表达式因子 用一对小括号包裹起来的表达式,可以带指数,且指数为一个非负带符号整数,例如
(x**2 + 2*x)**2。表达式的定义将在表达式的相关设定中进行详细介绍。
- 变量因子
- Homework2:下面只列出第二次作业相对于第一次作业增加的因子
- 三角函数
- 自定义函数
- 求和函数
- Homework3:下面直解释第三次作业相对于第二次作业对于因子的改动
- 允许嵌套因子的三角函数
第一次作业
架构分析
第一次作业接触到层次化递降的架构,基本思路就是把把表达式里的项提取出来,把化简表达式的问题降到化简项,再把项里面的因子提取出来,把化简项的问题降到化简因子。这是递降,把任务这一层的任务推给下一层,然后用下一层的结果来得出本层的结果。
性能分策略
只要将表达式的括号展开去掉以后正确性就达到了,性能分要靠缩短化简的表达式来得到。基本就是合并一下同类项,因为输入数据有幂次限制,采用的数组的方法,acc[0]就记录0次幂的项的系数之和,acc[1]记录一次幂的项的系数之和,....最终输出的时候,再让0次幂的项输出为常数,x**1输出为x,x**2输出x*x。
本次作业UML图
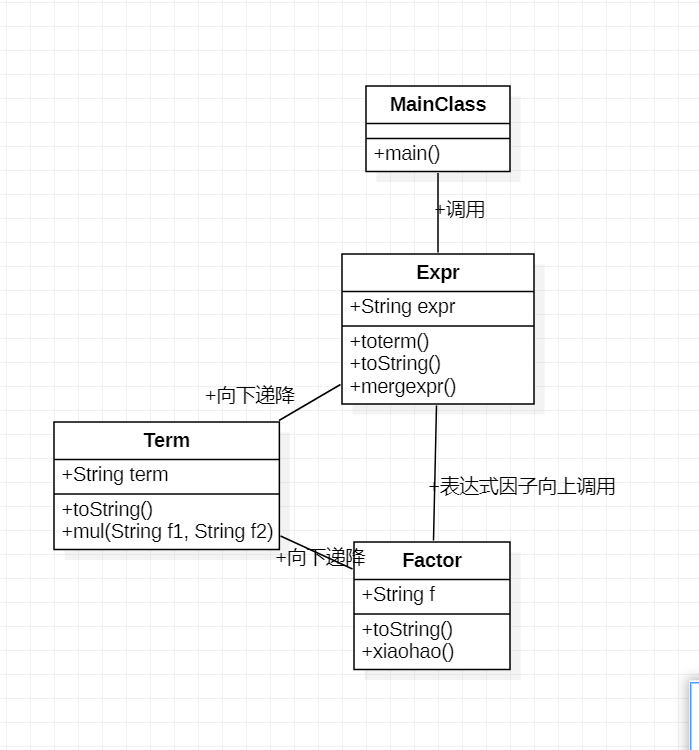
-
Expr类
- toterm方法返回一个Arraylist,里面存放从表达式中提取出来的项
- mergexpr是再展开的基础上返回一个合并同类项的表达式
-
Term类
- mul方法对两个被化简的因子做乘法,返回得到的字符串
-
Factor类
- xiaohao方法就是把因子前面的若干个正负号消成一个正负号
这三个类的toString方法都是返回一个字符串,这个字符串是本层次化简得到的字符串。
缺点:采用数组的方式进行合并同类想,不利于后续的迭代
优点:基本建成了递降的结构
性能分策略
只要将表达式的括号展开去掉以后正确性就达到了,性能分要靠缩短化简的表达式来得到。基本就是合并一下同类项,因为输入数据有幂次限制,采用的数组的方法,acc[0]就记录0次幂的项的系数之和,acc[1]记录一次幂的项的系数之和,....最终输出的时候,再让0次幂的项输出为常数,x**1输出为x,x**2输出x*x。
bug解析
这次作业出现两个bug
-
第一个bug
-
我想的是:0+x输出为x,0+3*x输出为3*x,目的就是去掉行首的0+
-
bug出现:-20+x输出为-2x,-50+x输出为-5x,使用replace方法的时候暴力去掉0+
修复bug:再把replace的reg由“0[+]”改为“^0[+]”
-
-
第二个bug
-
例子:-(x)**0输出1,-(x+x)**0输出1
对于0次幂的表达式因子忽略了它的符号(我的架构是把因子前面的符号也看成因子的一部分)
-
度量分析
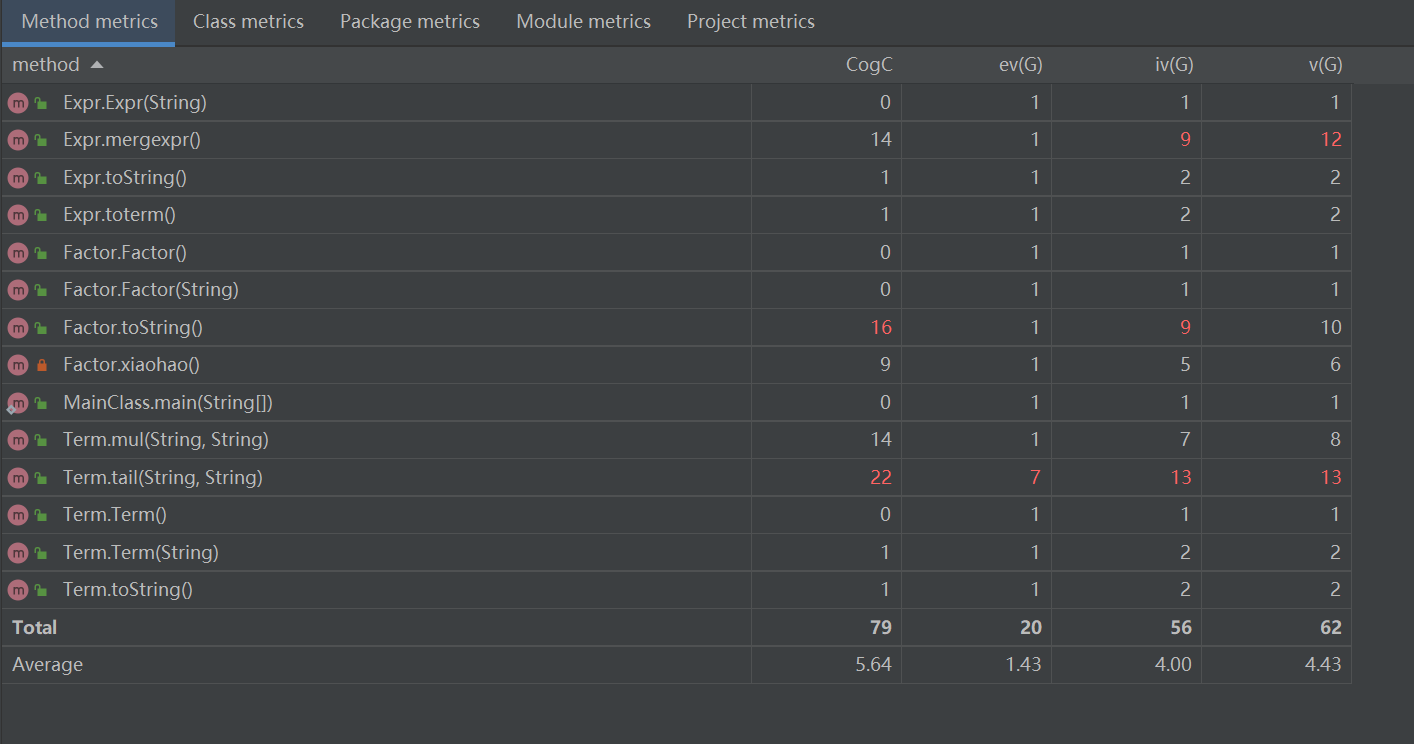
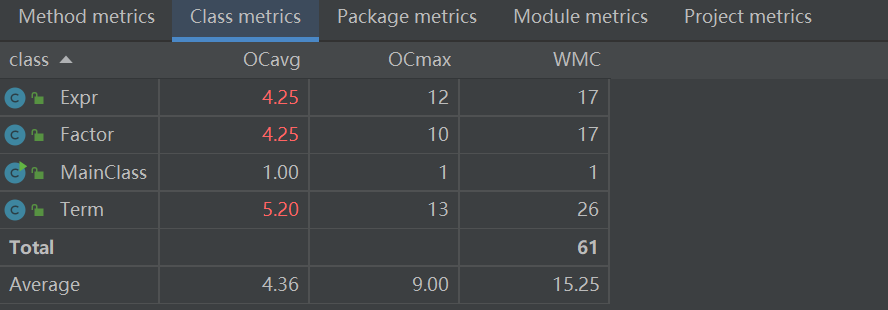
Expr的merge方法是用来合并同类项,这个方法写的比较丑陋,效率也低,基本是为了为了得性能分而写,要改进。
Factor的toString方法复杂度高是因为,我把多种因子都塞到这一个类的这一个方法里面进行处理,我应该写成多个方法和多个类。
Term的Tail方法是为了计算两个因子非系数部分相乘的结果,写的很烂,大半夜写的,脑子比较累,想不动了。
Hack策略
用java写了一个生成测试样例的程序,然后用大量的样例去盲测比对同房间的同学的输出。最终只hack出两个bug。
第二次作业
架构分析
递降关系大体上还是与第一次作业相同,不同的在于第二次因子结构更加复杂,我第一次作业使用正则表达式的方法,为每一个因子写一个Pattern,来提出项和因子,达到递降的目的。但是这一次因子的Pattern不好写,于是我还是新建一个类来专门去识别因子。
本次作业UML图
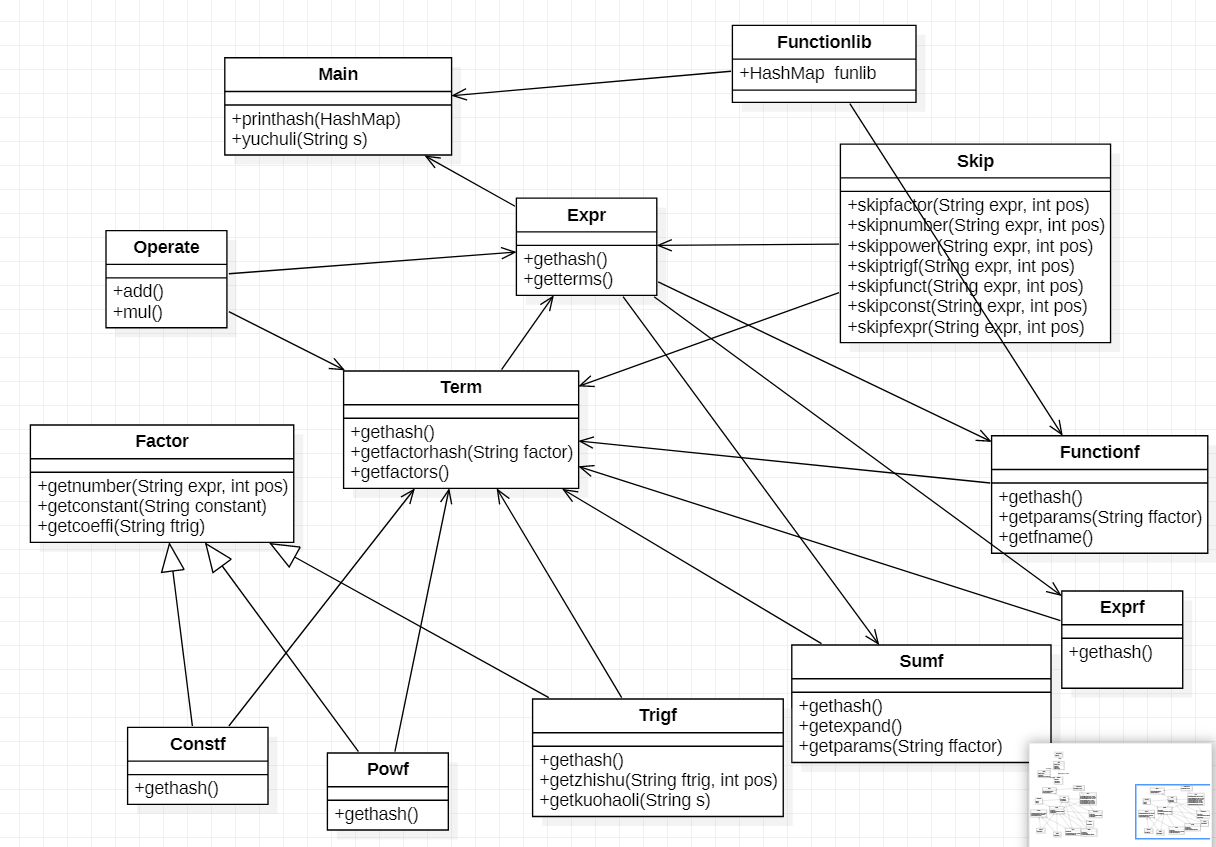
-
先对Expr,Term以及六种因子中都有出现的gethash方法进行解释,这个方法是返回一个 HashMap<HashMap<String,BigInteger>,BigInteger>,里面存储了化简得到的表达式。这个HashMap的每一项,也就是说每一对Key和Value的意义记录被化简的表达式的一个项的信息,Value也就是外层的BigInteger记录的是这个项的系数,Key也就是内层的HashMap的每一项记录的是项内一个因子的信息,String记录的是因子的底数,BigInteger记录的是因子的幂次。
举例说明就是2*x**2*sin(x)**3+1*x,那么这个表达式的第一项存到我的HashMap中就是,第一项的外层BigInteger为2,内层HashMap存了两个因子,<"x",2>和<"sin(x)",3>。 -
Skip类说明,这个类是专门建立用来识别因子和提出因子的。
举例来说:-(x+sin(x))**2+x**3+1,这是一个表达式字符串,我一个一个字符去遍历这个字符串,int i = 0,i现在指向第一个字符,一个负号,然后i++,一个括号,这个时候我就确定这是一个表达式因子,我调用针对表达式因子的方法,来获取这个因子的最后一个字符的位置,在这个表达式中为2,调用substring方法提取出这个因子-(x+sin(x))**2(我把负号也看成这个因子的一部分),然后把对i赋值让它指向下一个因子的开始,也就是2后面的加号,然后继续遍历,读到x的时候,我知道这是一个幂函数因子,我调用针对幂函数因子的方法去得到这个因子的最后一个字符的位置,然后substring连带正好提取出这个因子+x**3,然后让i指向这个因子之后第一个字符,也就是3后面的那个加号...
可以利用这个类去提取项。
-
Operate类中两个方法add()用来将化简项得到的HashMap合并成表达式的HashMap,mul()用来将化简因子得到的HashMap合并成项的HashMap。
-
Functionlib的作用在于它的属性static HashMap<String,String>,作用是存储输入的自定义函数的信息,key为函数名,value是函数的表达式。提供一个全局变量的作用。使得Functionf(用于化简自定义函数的类)中的方法可以访问到自定义函数的信息。
-
设计Factor类的原因是为了避免重复造轮子,因为有多种因子他们需要用到一些基本相同的方法,比如读出一个整数,读出指数之类的,所以这个类里面就是放了一些公用的方法,没有属性,有点随便。
缺点:有重复造轮子,有些类里面有一些十分相似的方法,也许可以建立一些继承关系。
优点:使用了嵌套的HashMap存储化简的表达式信息,比较容易进行乘法加法。
性能分策略
大体和第一次作业相似,就是合并了一下同类项,但是这一次我采用HashMap<HashMap<String,BigInteger>,BigInteger>
来存储每一个层次化简得到的表达式。所以合并同类项的方法就是写好HashMap的合并方法。
主要在两个方面,
- 一个是要用因子的HashMap来得出项的HashMap,也就是要得到因子做乘法得到结果对应的HashMap
- 一个是要用项的HashMap来得出表达式的HashMap,也就是要得到项做加法得到结果对应的HashMap
bug解析
强测出了一个bug
举例说明:sin(x**2)输出sin(x^2),sin(x**3)输出sin(x^3),
原因很明显,对输入的字符串进行预处理的时候,把**替换成^,最后输出的时候忘了把三角函数括号里面的^换回来,很容易修复。
度量分析

说明一下没有显示全的前三个类的名字,第一个是Constf,用来化简常数因子,第二个是Factor,第三个是Powf,用来化简幂函数因子。
Factor、Skip、Trigf类复杂度高应该是方法数太多了。
我也不知道要怎么改进,可能是要拆一拆类,把方法数多的类拆成两个类或者几个类,但是我不知道该不该拆,我是说我不可能仅仅是是为了让这个指标好看去改我的类。拆的话也应该是要把架构拆的更清晰简单。总之我不知道要依据什么去拆,要怎么拆。
Hack策略
这次没用大量的数据样例轰炸,因为没有写生成数据的程序,所以就是随手自己测一测一些边界数据,例如0次方,sin(0),cos(0)。
第三次作业
架构分析
这一次作业工作量较少,就是在第二次的基础上改进了三角函数因子的化简,第二次作业递降到三角函数因子就到最底层了,这一次三角函数里面允许嵌套因子,也就是三角函数因子可能再递降到表达式的层次。就对三角函数因子括号内的内容分情况进行了处理。
本次作业UML图
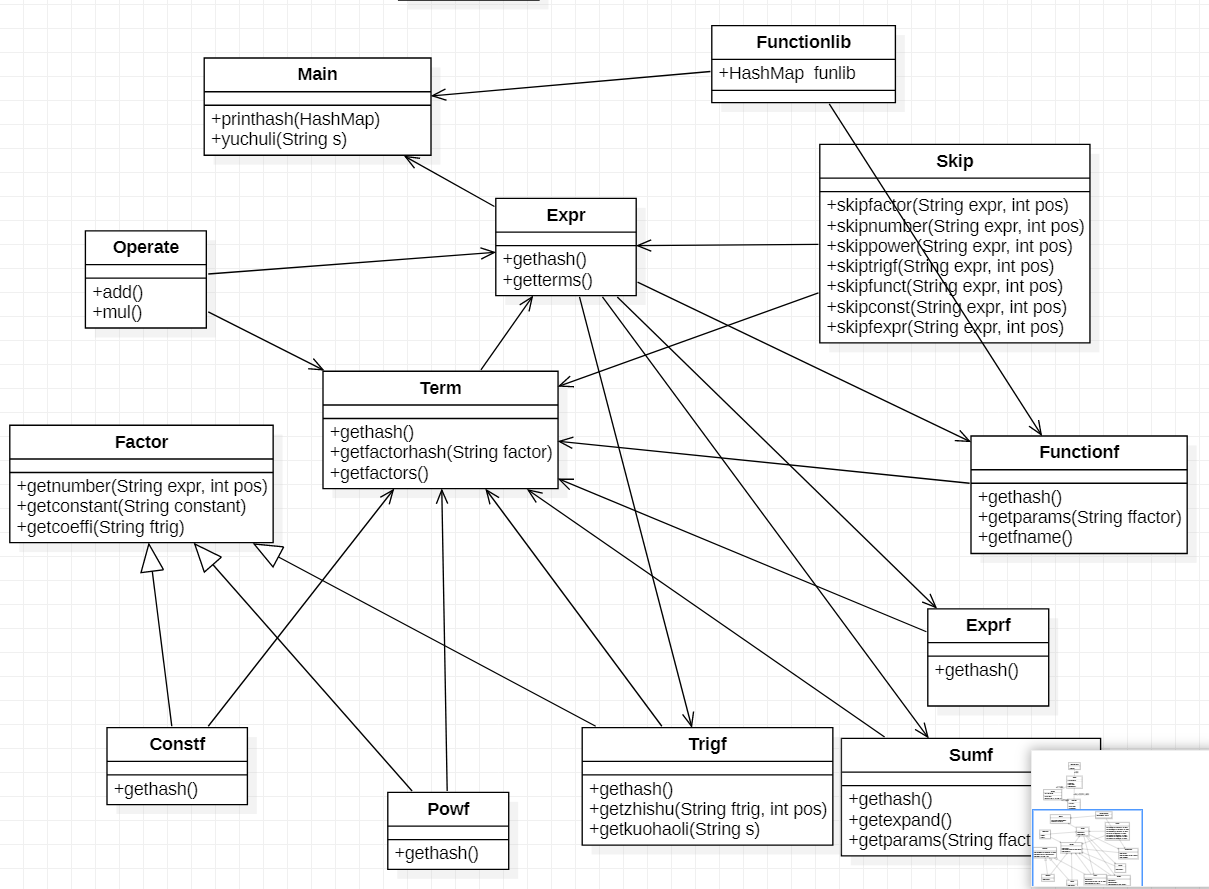
这一次作业相对于第二次作业改动很少,就是改动了Trigf的getkuohaoli方法,让它调用Expr类来对三角函数括号里的字符串来进行化简。
性能分策略
相对于第二次作业没有什么改动。
bug解析
这一次强测和互测没出bug,但是讨论群里别的同学分享bug的时候,我发现我出了同样的bug。
举例说明:输入数据为 0 f(x,y)=x+y f(y,x),输出2*x(这个数据样例不合法,只是用来说明一下bug)
原因在于:对自定义函数带入参数的时候,先把x换成了y,然后又把y,换成x,就是说我对替换进去的参数进行了替换。
修复bug:先把自定义函数表达式的x换成p1,y换成p2再进行替换。
度量分析
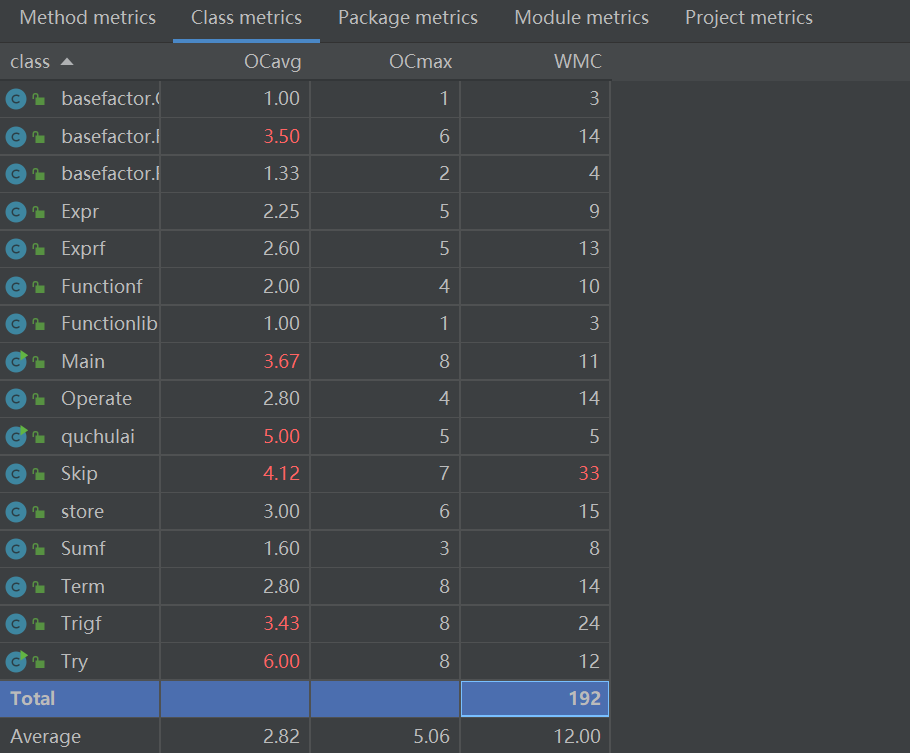
忽略Try、store和quchulai者两个类,这三个类只是我用来做实验的。这次迭代得比较偷懒,因为基本只改了Trigf这一个类,所以导致它的复杂度较高。别的问题基本与第二次一样。
Hack策略
没有写程序生成数据,别人的代码太难看懂,所以随手试了一些数据,跟上次的区别在于,OS学了脚本,我先把别人的程序生成Jar包,再写了一个简单的脚本,用git bash命令行进行的测试,以前都是在IDEA里面比对输出结果。只发现一个同学sin((-x))输出sin(-x)的bug
心得体会
-
学习到了递降法,或者说是层次化。递降法我认为麻烦的地方在于两个方面
-
一个是我怎么降到下一个层次。
就这次作业说就是怎么从表达式里面识别提出一个一个的项,怎么从项里面识别提出一个一个的因子。
-
一个是我怎么用下一个层次传上来的结果得出我这一个层次的结果。
举例说怎么用项化简得到的HashMap来得到表达式化简的HashMap。
-
-
仔细阅读指导书的要求再动手,要想好以后再动手,不要急着开始写代码。
实际上第一次作业对我来说是最难的,因为第一次需要从零去学习这个递降的结构。我先花了一晚上看了训练的题目,有了一些理解。然后又花了一个下午,想通了第一点里面提到的两个方面,这个时候我觉得可以开始写代码了。然后又花了一些时间把各个因子的Pattern造出来。
说这些是为了说明我认为设计是写程序很重要的一步,我花了很久的时间去搞清楚递降法是什么,在想通之前觉得没法动手,想通以后就觉得不是很难,因为清晰的架构有了,接下来就是繁琐的但是不是很难的东西。
