<算法基础><排序>O(nlogn)的三种高级排序——快速排序,堆排序,归并排序
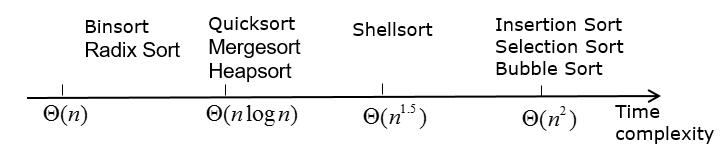
这三种排序算法的性能比较如下:
| 排序名称 | 时间复杂度(平均) | 时间复杂度(最坏) | 辅助空间 | 稳定性 |
| 快速排序 | O(nlogn) | O(n*n) | O(nlogn) | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(n) | 稳定 |
以下除特殊说明外均针对元素数为n的一个序列。
1.归并排序
归并排序的基本思想是递归地将两个或多个有序子序列合并成一个新的有序子序列,最终得到一个长度为n的有序序列。
看这里,我们先将序列看成n个有序的子序列,每个序列的长度为1,然后两两归并,得到n/2个长度为2或1的有序子序列,然后两两归并,........,如此重复,直到得到长度为n的一个有序子序列,这种方法称为2路归并排序,如果每次操作将3个有序子序列归并,则称为3路归并排序。
以下以2路归并排序为例进行说明:
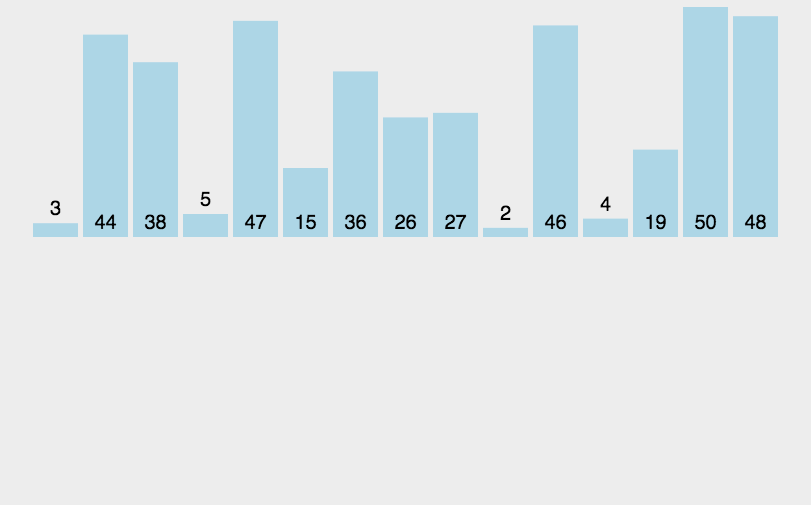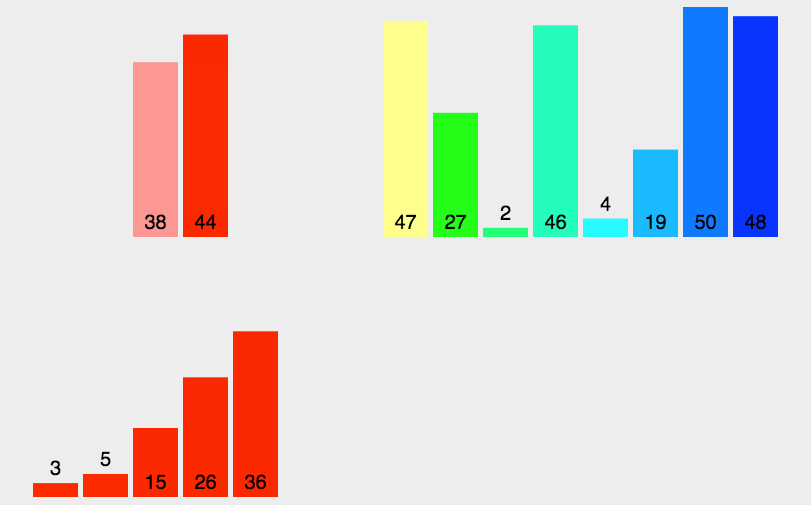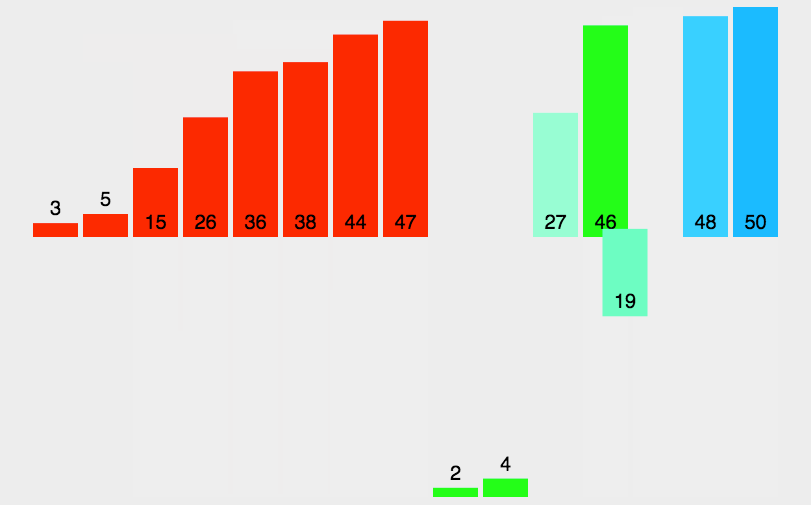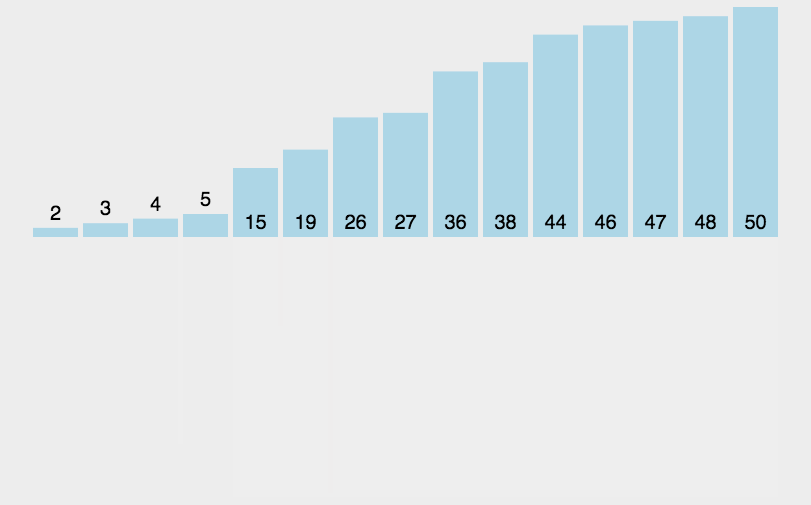
python实现2路归并排序————
def merge_sort(list):
if len(list)<2:
return list
left=merge_sort(list[0:int(len(list)/2)])
right=merge_sort(list[int(len(list)/2):])
return merg(left,right)
def merg(l1,l2):
i=0
j=0
list=[]
while i<len(l1) and j<len(l2):
if l1[i]<l2[j]:
list.append(l1[i])
i=i+1
else:
list.append(l2[j])
j=j+1
list.extend(l2[j:])
list.extend(l1[i:])
return np.array(list)
2.快速排序
快速排序的基本思想是任选序列中的一个数据元素(默认选择第一个数据元素)作为pivot,以其为基准,对剩下的元素作以下处理——比pivot大的排在pivot后面,比pivot小的排在pivot前面。然后以pivot为界把序列划分为两个部分,再对这两个部分递归上述过程直到每一部分中只剩下一个数据元素为止。
一种操作方法是,对每个递归步——设pivot为arr[low],首先从arr[high]所指的位置开始向左搜索到第一个小于的数据元素(此数据元素仍假记为)为止,然后交换arr[low]和arr[high],这时pivot为high,再从low所指位置开始向右搜索到第一个大于high的数据元素(此数据仍假记为low)为止,然后交换low和high,此时pivot为low,重复这两步直到low=high时为止,这时pivot的位置为arr[low]。

python实现快速排序——
#本处函数输入和输出均为list列表类型
def quick_sort(list):
if len(list) >= 2: # 递归入口及出口
mid = list[len(list)//2] # 选取基准值,也可以选取第一个或最后一个元素
left, right = [], [] # 定义基准值左右两侧的列表
list.remove(mid) # 从原始数组中移除基准值
for num in list:
if num >= mid:
right.append(num)
else:
left.append(num)
return quick_sort(left) + [mid] + quick_sort(right)
else:
return list
3.堆排序
堆排序基于堆heap的数据结构进行排序,只需要一个元素的辅助存储空间。以下只针对大顶堆,大顶堆的堆顶元素为最大。
排序过程是这样的——首先将原始序列构建为一个大顶堆。弹出堆顶元素,对剩下的堆进行维护操作,此时堆顶为堆中这几个元素中的最大,如此重复,最后堆所输出的元素组成了有序序列,即为我们要的排序好的序列。

#这里用的是最小堆
def heap_sort(list):
result=[]
list.insert(0,None)
k=len(list)
while k>1:
k-=1
i=0
while 2**(i+1)<len(list):
i+=1
while i>0:
for p in range(2**i-1,2**(i-1)-1,-1):
if 2*p<len(list) :
if list[p]>list[2*p]:
list[p],list[2*p]=list[2*p],list[p]
if 2*p+1<len(list) :
if list[p]>list[2*p+1]:
list[p],list[2*p+1]=list[2*p+1],list[p]
i-=1
result.append(list[1])
list[1]=list[-1]
list.pop()
return result
Reference:
1. 《Data Structures and Algorithm Analysis》,Shaffer

 浙公网安备 33010602011771号
浙公网安备 33010602011771号