数据采集第一次作业
作业① UniversitiesRanking:
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
代码
import urllib.request
from bs4 import BeautifulSoup
def getHtmlText(url):
html=urllib.request.urlopen(url)
html=html.read()
html=html.decode()
return html
url="http://www.shanghairanking.cn/rankings/bcur/2020"
html=getHtmlText(url) #得到html文档
soup = BeautifulSoup(html, "html.parser") #遍历html文档
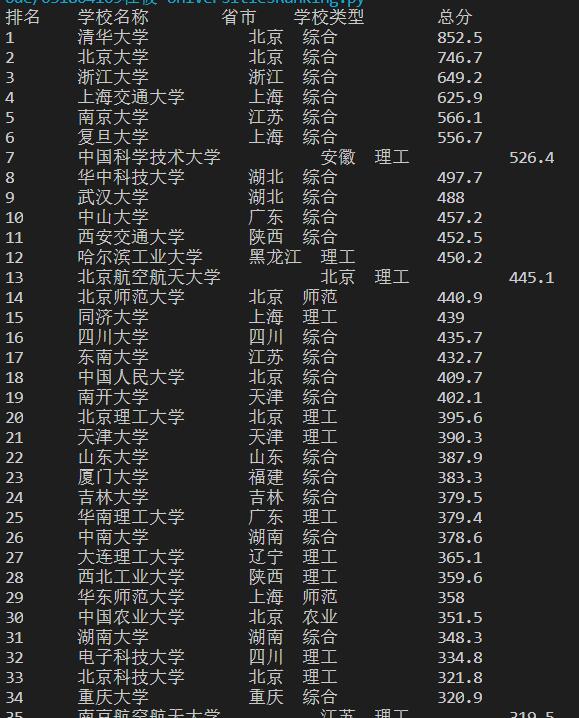
print("排名\t学校名称\t省市\t学校类型\t总分")
for tr in soup.find('tbody').children:
r = tr.find_all("td") #查找所有td元素
#打印元素中的文本
print(r[0].text.strip()+"\t"+r[1].text.strip()+"\t"+' '+r[2].text.strip()+" "+r[3].text.strip()+"\t"+'\t'+r[4].text.strip())
实践结果
心得体会
通过本次实验,对于HTML文档树有了进一步的认识,了解了大致的爬虫过程,知道了该如何查找元素,加深了对于理论知识的理解。
作业② GoodsPrice:
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码
import urllib.request
from bs4 import BeautifulSoup
import re
import urllib.parse
import w3lib.html
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"}
url="https://search.jd.com/Search?keyword=%E4%B9%A6%E5%8C%85&enc=utf-8&wq=%E4%B9%A6%E5%8C%85&pvid=9bd25fcc2bda47b1bc33a822f0ec8e11"
def getHtmlText(url,headers):
req=urllib.request.Request(url,headers=headers)
html=urllib.request.urlopen(req)
html=html.read()
html=html.decode()
return html
html=getHtmlText(url,headers)
#html文档中去除所有的span标签及其之间的文本内容
html=w3lib.html.remove_tags_with_content(html,which_ones=('span',))
soup = BeautifulSoup(html, "html.parser")
i=0
lis=soup.find_all("li",{"data-sku": re.compile("\d+")})
print("序号\t商品名称\t\t\t\t\t\t\t\t\t\t\t价格")
#本来不想一级级读,可是不一级级查找,又出错,总是keyvalue为0。。。
# 今天暂时就这样一级级查找叭QAQ
for li in lis:
price1=li.find("div",attrs={"class":"p-price"}).find("strong").find("i")
price = price1.text
name1=li.find("div",attrs={"class":"p-name"}).find("a").find("em")
name=name1.text.strip()#找到书包名字及去除头尾所有空格
i=i+1
t='\t'
print(i,t,name,t,price)
实践结果

心得体会
经过本次实验,对于反爬虫机制有了初步的了解,对于HTML查找提取信息,是直接关键词模糊查找还是通过层级一级级寻找,有了更深的理解,知道了如何去除我们所不需要的元素信息等。
作业③ JPGFileDownload:
要求:爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
代码
'''
1、网页的html
2、遍历文档元素,结合正则表达式匹配出所有以jpg/png结尾的
3、提取图片路径信息,存入数组
4、遍历数组,路径信息,找到图片,一次存入文档
'''
import urllib.request
from bs4 import BeautifulSoup
import re
from pyquery import PyQuery as pq
def getHtmlText(url):
html=urllib.request.urlopen(url)
html=html.read()
html=html.decode()
return html
url="http://xcb.fzu.edu.cn/"
headers={"User-Agent":" Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"}
html=getHtmlText(url)
soup = BeautifulSoup(html, "html.parser")
imglist = soup.find_all("img",{"src": re.compile('(jpg|png)$')})
final_img_url=[]
for imgurl in imglist:
#print(imgurl)
src=imgurl.attrs['src']
#判断是绝对路径or相对路径
if src.find("http://") == 0:
final_img_url.append(src)
else:
final_src=url+src
#判断路径信息是否已加入数组
if(final_src in final_img_url):
continue
else:
final_img_url.append(final_src)
print(final_src)
#print(final_img_url)
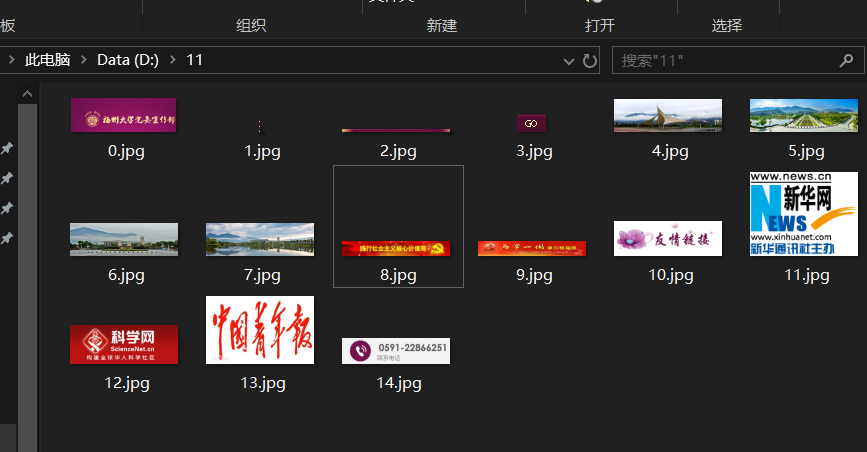
i=0
for url in final_img_url:
response=urllib.request.urlopen(url)
img=response.read()
dir='D:/11/'+str(i)+'.jpg'
f=open(dir,'wb')
f.write(img)
i=i+1
实践结果
心得体会
经过这三次爬虫实验,已经大致了解了爬虫过程,其过程几乎都一样,也就只是其筛选具体信息,或者说匹配所需要的信息时有所出入;另外在这一次实践中,需要注意绝对路径和相对路径。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号