

为什么要动态链接
静态链接的问题
-
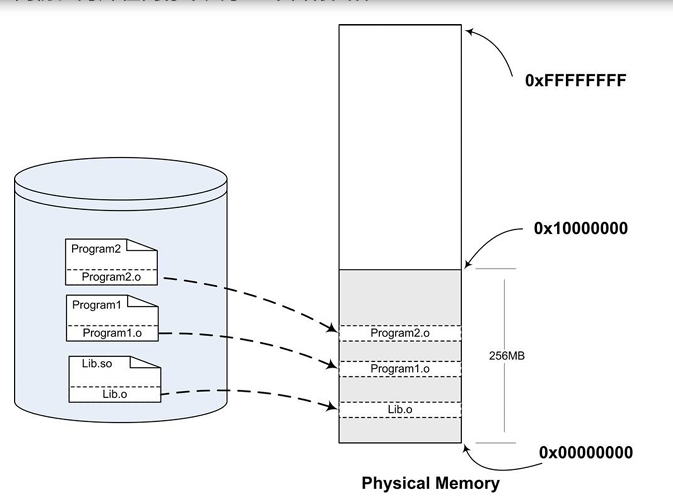
浪费内存和磁盘空间:静态库可能会在存在 多个副本(如果多个程序都使用了同一个静态库的话)
存在多个Lib.o

- 更新困难:对静态库的任意改动都可能导致整个程序要 重新链接
动态链接
要解决空间浪费和更新困难这两个问题最简单的办法就是把程序的模块相互分割开来,形成独⽴的⽂件,⽽不再将它们静态地链接在⼀起。简单地讲,就是不对那些组成程序的⽬标⽂件进⾏链接,等到程序要运⾏时才进⾏链接。也就是说,把链接这个过程推迟到了运⾏时再进⾏,这就是动态链接(Dynamic Linking)的基本思想。
只有一份Lib.o
- 可扩展性好
动态链接还有⼀个特点就是程序在运⾏时可以动态地选择加载各种程序模块,这个优点就是后来被⼈们⽤来制作程序的插件(Plug-in)
- 加强兼容性:比如不同的平台上都可以使用同样的 c库,这个动态链接库就相当于 程序和操作系统之间的中间层
产生的问题:
当程序所依赖的某个模块更新后,由于新的模块与旧的模块之间接⼝不兼容,导致了原有的程序⽆法运⾏
动态链接的基本实现
动态链接的基本思想是把程序按照模块拆分成各个相对独⽴部分,在程序运⾏时才将它们链接在⼀起形成⼀个完整的程序,⽽不是像静态链接⼀样把所有的程序模块都链接成⼀个个单独的可执⾏⽂件
当程序被装载的时候,系统的动态链接器会将程序所需要的所有动态链接库(最基本的就是libc.so)装载到进程的地址空间,并且将程序中所有未决议的符号绑定到相应的动态链接库中,并进⾏重定位⼯作
简单的动态链接例子
// mylib.h
#ifndef LIB_H
#define LIB_H
void foobar(int i);
#endif /* LIB_H */
// mylib.c
#include <stdio.h>
void foobar(int i)
{
printf("Printing from mylib.so %d\n", i);
}
// prog1.c
#include "mylib.h"
int main(void)
{
foobar(1);
return 0;
}
// prog2.c
#include "mylib.h"
int main(void)
{
foobar(1);
return 0;
}
- 首先将
mylib.c编译成 共享对象,即 动态库
clang -fPIC -shared -o mylib.so mylib.c
- 将
prog1.c和prog2.c编译链接为 可执行程序
clang -o prog1 prog1.c ./mylib.so
clang -o prog2 prog2.c ./mylib.so
必须加上 ./,告诉系统共享库位于当前目录。没有 ./ 时,系统会去标准库路径中查找共享库

注意,虽然命令行中,mylib.so参与了链接,但是mylib.so并没有被链接起来
在静态链接时,整个程序最终只有⼀个可执⾏⽂件,它是⼀个不可以分割的整体
但是在动态链接下,⼀个程序被分成了若⼲个⽂件,有程序的主要部分,即可执⾏⽂件(prog1)和程序所依赖的共享对象(mylib.so),很多时候我们也把这些部分称为模块,即动态链接下的可执⾏⽂件和共享对象都可以看作是程序的⼀个模块
-
当程序模块 prog1.c 编译成 prog1.o 时,编译器并不知道 foobar() 函数的地址
-
链接器在将 prog1.o 转换成可执行文件时,必须确定 foobar() 的地址。
-
如果 foobar() 是静态函数,链接器会进行静态链接并重定位地址
-
如果是动态库中的函数,链接器会将其标记为动态符号,地址重定位会推迟到加载时进行
-
-
为了区分静态符号和动态符号,链接器需要使用符号信息
- 如果将动态库 mylib.so 作为链接输入,链接器就能知道 foobar() 是动态符号,并进行适当的处理
动态链接器与普通共享对象⼀样被映射到了进程的地址空间,在系统开始运⾏
prog1之前,⾸先会把控制权交给动态链接器,由它完成所有的动态链接⼯作以后再把控制权交给prog1,然后开始执⾏
换句话说,就是相比于静态链接,动态链接中程序的虚拟地址空间会多出 动态链接器 和 共享对象 的映射
地址无关代码
固定装载地址的困扰
共享对象在被装载时,如何确定它在进程虚拟地址空间中的位置?如何确保不会与其他共享对象地址冲突
装载时重定位
静态链接中的重定位叫做 链接时重定位
在为了解决这个模块装载地址固定的问题,我们设想是否可以让共享对象在任意地址加载?这个问题另⼀种表述⽅法就是:共享对象在编译时不能假设⾃⼰在进程虚拟地址空间中的位置。
在链接时,对所有绝对地址的引⽤不作重定位,⽽把这⼀步推迟到装载时再完成。⼀旦模块装载地址确定,即⽬标地址确定,那么系统就对程序中所有的绝对地址引⽤进⾏重定位。
动态链接模块被装载映射⾄虚拟空间后,指令部分是在多个进程之间共享的,由于装载时重定位的⽅法需要修改指令,所以没有办法做到同⼀份指令被多个进程共享,因为指令被重定位后对于每个进程来讲是不同的。
因为装载时需要进行重定位,也就是说,动态库内部的符号的引用地址需要进行修正,而对于不同的进程,动态库加载的位置也不同,所以符号的修正内容也会不同,这就意味着不能在多个进程中共享,所以只在物理内存中保存一份,创建多个虚拟映射的办法是行不通的(符号的引用地址需要被修正,即物理内存中的值也要被修正,所以无法共享)
但是对于可修改的数据区域来说,就可以使用 装载时重定位 了,因为他们本身就有可能会被修改,所以不能共享并没有太大问题
总而言之,就是装载时重定位虽然可以解决固定装载地址带来的困扰,但是他没办法让指令部分在多个进程之间共享
地址无关代码
共享模块中的地址引用分为4类

在编译时,我们有时没法确定一个文件中的函数调用或者数据访问是发生在模块内还是模块外,因为他们有可能被定义在同一个共享对象模块内,由于没法确定,所以只能将他们当作 模块外引用 来处理
不过有些编译器会有对应的扩展,用来显示的说明是模块内还是模块外
-
模块内引用:可以使用 相对地址,因为在同一个模块内,相对位置是固定的
-
模块外引用:使用 GOT(全局偏移表) 来实现 指令的地址无关性
模块在编译时,能够确定模块内部变量相对于当前指令的偏移,也能够确定GOT相对于当前指令的偏移

就像上面这张图,GOT 位于数据段,存储符号的 运行时地址,他的位置是在编译期确定的,因为动态库同样也会参与 链接阶段(提供符号信息),所以我们将动态库的 模块间地址引用 全部转换成 通过GOT的间接引用,这样不就实现了 指令的地址无关性 了吗
换句话说,我们是将,动态库中本来要在装载时改变的部分,移动到了 GOT 中,GOT 变成了每个进程独有的数据项
-
不使用 GOT:
lib1 -> lib2lib1依赖于lib2,假设lib1使用了lib2的符号那么当lib1被装载进内存后,它需要对 引用lib2符号的地址 进行重定位,而每个进程的情况不同,他们装载 lib2 的地址也不同,那么导致的结果就是 lib1重定位的结果也不同,所以指令无法共享
-
使用 GOT:
lib1 -> GOT <- lib2lib1依赖于lib2,假设lib1使用了lib2的符号在编译阶段,我们可以确定 GOT 相对于当前指令的偏移位置,那么 lib2在参与链接时,将自身的符号导出到 GOT 中,相当于占个位置,表示这个槽位是 lib2 的 符号A,那么当 lib1 参与链接时,只需要将 引用lib2符号的地址 重定位为 GOT 中对应的地址即可
注意这里的一切都是发生在 链接阶段,然后当程序运行时,在装载某个动态库时,动态链接器会更新 GOT 中的符号地址为具体地址(GOT位于可修改的数据区),当 lib1 装载后,它的指令无需更改,因为 GOT 的位置没有变化,变化的是 GOT 中的内容,所以 lib1 可以正常调用

-
如何产生地址无关代码(以gcc为例)
地址无关代码的生成与硬件平台相关
- -fPIC: 产生的代码较大,跨平台性好
- -fpic:产生的代码较小,相对较快,跨平台性差
-
如何判断一个共享文件是不是地址无关的
readelf -d foo.so | grep TEXTREL,有输出就不是,PIC是不会包含代码重定位表的
-
地址无关可执行文件
- fPIE
- fpie
延迟绑定(PLT)
动态链接为什么较慢
- 通过GOT间接寻址
动态链接⽐静态链接慢的主要原因是动态链接下对于全局和静态的数据访问都要进⾏复杂的GOT定位,然后间接寻址;对于模块间的调⽤也要先定位GOT,然后再进⾏间接跳转
- 运行时链接
另外⼀个减慢运⾏速度的原因是动态链接的链接⼯作在运⾏时完成,即程序开始执⾏时,动态链接器都要进⾏⼀次链接⼯作
什么是延迟绑定
基本的思想就是当函数第⼀次被⽤到时才进⾏绑定(符号查找、重定位等),如果没有⽤到则不进⾏绑定。所以程序开始执⾏时,模块间的函数调⽤都没有进⾏绑定,⽽是需要⽤到时才由动态链接器来负责绑定。
延迟绑定是如何是实现的呢?
在此之前,我们要先知道绑定是如何实现的?函数原型可以看成是下面这样
lookup(module, function) 即在哪个模块,是哪个函数,找到后 更新GOT
实现 PLT 的指令序列大致如下:

假设我们有一个函数 bar,当我们调用 bar 时,我们会先去 PLT 表中查找,然后执行对应的指令,如上图
首先会跳转到 GOT 中对应的位置,如果已经绑定了,那就直接继续执行就好,bar@plt 剩下的指令不在执行,如果没有绑定(GOT中对应的表项被设置成 push n 这条指令的地址),会跳回到第二条指令继续执行
第⼆条指令将⼀个数字n压⼊堆栈中,这个数字是bar这个符号引⽤在重定位表“.rel.plt”中的下标
接着⼜是⼀条push指令将模块的ID压⼊到堆栈,然后跳转到_dl_runtime_resolv
然后调⽤动态链接器的_dl_runtime_resolve()函数来完成符号解析和重定位⼯作。_dl_runtime_resolve()在进⾏⼀系列⼯作以后将bar()的真正地址作填⼊bar@GOT中。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号