

程序的内存分布
-
栈:维护函数调用上下文以及局部变量等
-
堆:动态分配的内存区域
-
可执行文件映像:可执行文件在内存中的映像
-
保留区:保留区并不是⼀个单⼀的内存区域,⽽是对内存中受到保护⽽禁⽌访问的内存区域的总称
-
动态链接库映射区:用于映射装载的动态链接库

栈与调用惯例
-
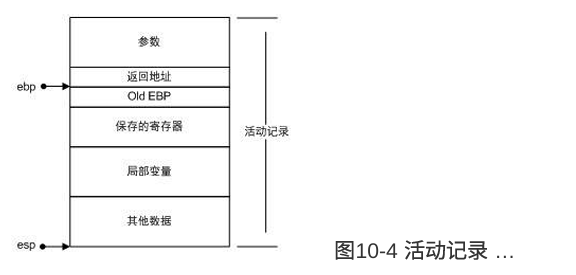
栈帧或活动记录:
-
函数的返回地址和参数
-
临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量
-
保存的上下文:包括在函数调⽤前后需要保持不变的寄存器
-
- 调用惯例

此外,不少编译器还提供⼀种称为naked call的调⽤惯例,这种调⽤惯例⽤在特殊的场合,其特点是编译器不产⽣任何保护寄存器的代码,故称为naked call。
堆与内存管理
因为栈上的数据在函数返回的时候就会被释放掉,所以⽆法将数据传递⾄函数外部。⽽全局变量没有办法动态地产⽣,只能在编译的时候定义,有很多情况下缺乏表现⼒。在这种情况下,堆(Heap)是唯⼀的选择。
堆是⼀块巨⼤的内存空间,常常占据整个虚拟空间的绝⼤部分。在这⽚空间⾥,程序可以请求⼀块连续内存,并⾃由地使⽤,这块内存在程序主动放弃之前都会⼀直保持有效。
malloc实现
在实现 malloc 时,通常采用的方式是将内存管理工作从操作系统内核移交给程序的运行库,这样做的原因是直接通过系统调用申请内存的性能开销较大。下面是实现的总结:
-
内存管理的分工:
- 操作系统管理进程的地址空间,但频繁的系统调用会带来较大的性能损耗
- 程序运行库(如
glibc)则向操作系统申请一块较大的内存块,并负责管理该内存块的分配和释放
-
批发与零售:
- 批发:程序运行库向操作系统申请一块较大的内存区域(如堆空间)
- 零售:运行库根据程序的需求,分配内存块给程序(类似零售)
-
内存管理算法:
- 运行库需要管理分配的内存区域,确保每个分配请求都得到合适的内存块,而不发生地址冲突
- 为了高效地管理内存块,运行库通常使用一些堆分配算法,如 首次适应算法、最佳适应算法、伙伴系统等
-
动态管理堆内存:
- 当程序需要更多内存时,运行库可以向操作系统再次申请新的内存区域
- 当程序释放内存时,这些内存块可以再次进入池中,供后续请求使用
堆分配算法
-
空闲链表分配:
简单,但是需要分配额外字节来维护分配出去的内存块的信息(比如大小),
简单来说,就是,用户请求 k 字节,实际分配 k+4 字节,这额外的4个字节就用来维护分配内存块的信息,比如可以是一个 用于验证内存块是否被破坏的数字,内存块的实际大小 等等
-
位图
-
内存划分:堆被划分为 大小相同 的块(block)
-
块的状态:每个块有三种状态:头(已分配区域的开始)、主体(已分配区域的其他部分)和空闲
-
位图表示:通过一个 整数数组 记录块的使用情况,每个块用 两位 表示
-
内存分配:用户请求内存时,分配 整数个块 给用户。
-
优点:
-
速度快:由于整个堆的空闲信息存储在⼀个数组内,因此访问该数组时cache容易命中
-
稳定性好:为了避免⽤户越界读写破坏数据,我们只须简单地备份⼀下位图即可。⽽且即使部分数据被破坏,也不会导致整个堆⽆法⼯作
-
块不需要额外信息,易于管理
-
-
缺点:
-
分配内存的时候 容易产⽣碎⽚(分配整数个块)
-
块小,可减少内存碎片,但同时位图变大,cache命中率可能下降 => 多级位图
-
-
-
对象池
-
内存分配模式:对象池适用于内存请求大小固定的场景,将堆空间划分为多个相同大小的小块
-
管理方法:对象池可以采用空闲链表或位图管理方式,区别在于每次请求的内存大小相同,因此实现简单
-
性能优势:由于每次请求的内存大小相同,避免了查找合适空闲空间的过程,分配和回收速度非常快
-
对象池的思路很简单,如果每⼀次分配的空间⼤⼩都⼀样,那么就可以按照这个每次请求分配的⼤⼩作为⼀个单位,把整个堆空间划分为⼤量的⼩块,每次请求的时候只需要找到⼀个⼩块就可以了。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号