

简介
write 函数
ssize_t write(int fd, const void *buf, size_t count);
- fd:文件描述符,表示要写入的文件或设备
- buf:指向要写入的数据的缓冲区
- count:要写入的字节数
- 返回值:成功时返回写入的字节数;失败时返回 -1
read 函数
ssize_t read(int fd, void *buf, size_t count);
- fd:文件描述符,表示要读取的文件或设备
- buf:指向存储读取数据的缓冲区
- count:要读取的字节数
- 返回值:成功时返回读取的字节数(可能小于 count);到达文件末尾时返回 0;失败时返回 -1
探究
write
-
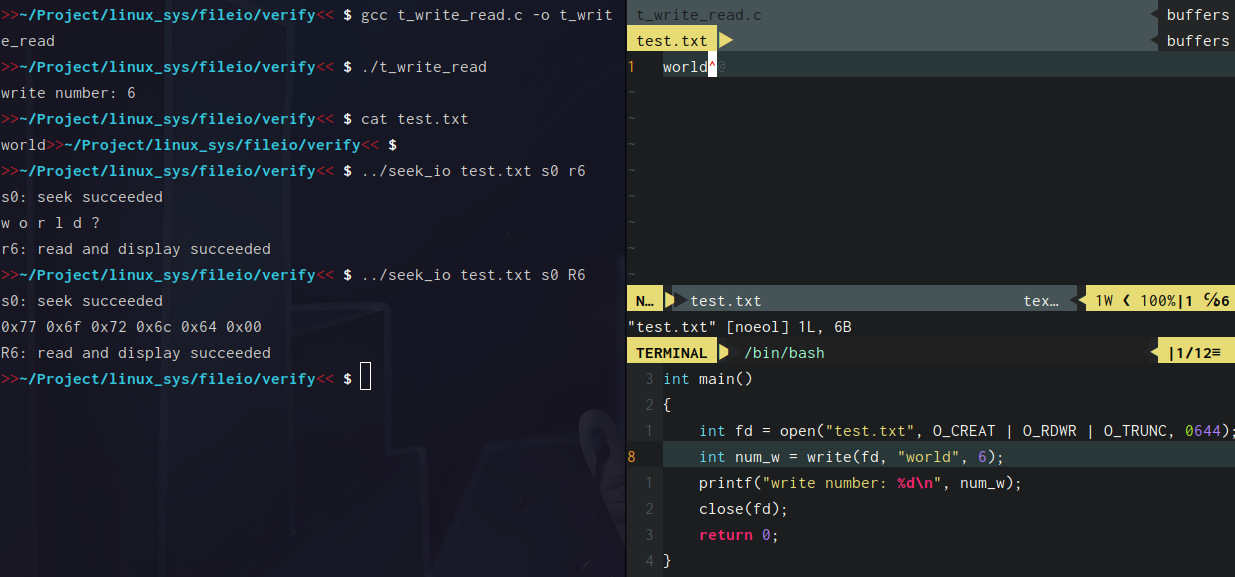
write中count和buf的大小相等的情况下
![1]()

这样子是正常的,我们也正好像文件中写入了5个字节的内容,刚好就是world
这里r6表示显示6个字节的内容,R6表示以十六进制显示,s0是把文件偏移量设置为0
-
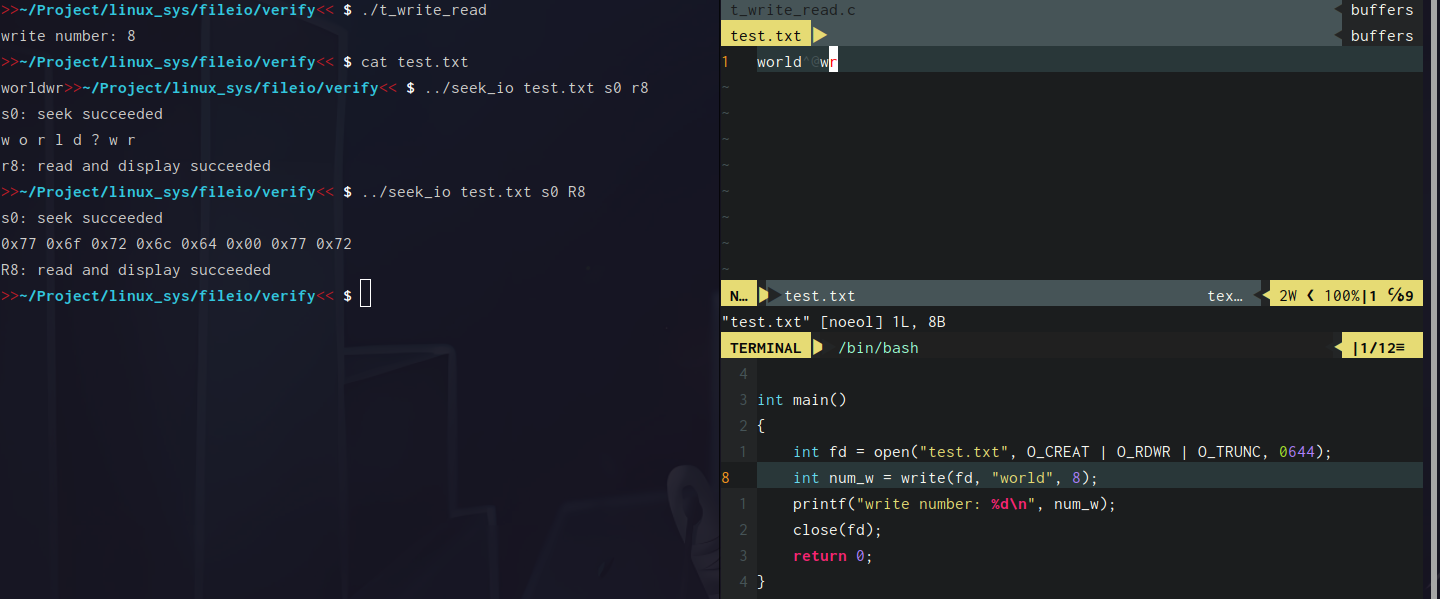
write中count比buf大小大1
![2]()
我们可以看到,这还是正常,这是因为c语言中字符串是以空字节'\0'结尾,所以它在内存中实际的大小还要加上一个字节,换句话说,字符串所占用的字节数比长度大一,所以我们看到文件中的最后一个是一个未知的东西,这其实就是'\0',不过它是不可打印的
我们也能看到r6显示出来最后一个是?,R6则更明显了,0x00其实就是空字节
-
write中count比buf大小大2及以上
以下是大2的情况
![3]()
ok,我们可以看到编译只是发出警告,没有报错,然后最后的一个字节就看内存的具体内容了
以下是大3的情况
![4]()
编译信息还是警告,不过我这里没有截取出来,可以看到最后一个字节是r
大家还是要注意,就是这里没有报错不一定是绝对的,我们从未分配给我们的内存中读取数据会导致不在预期里的行为,比如这里的w和r两个字符,它根本就是取决于内存自己,然后我猜测没有报错只是因为我们访问的比较短,一般来说,分配的可用内存还是比较大的,不会刚好用完,还会留下一点可以使用的空间
这里就要区分虚拟内存和物理内存了,总之大家注意不要越界就行

文件偏移量
它决定了文件io的开始位置
-
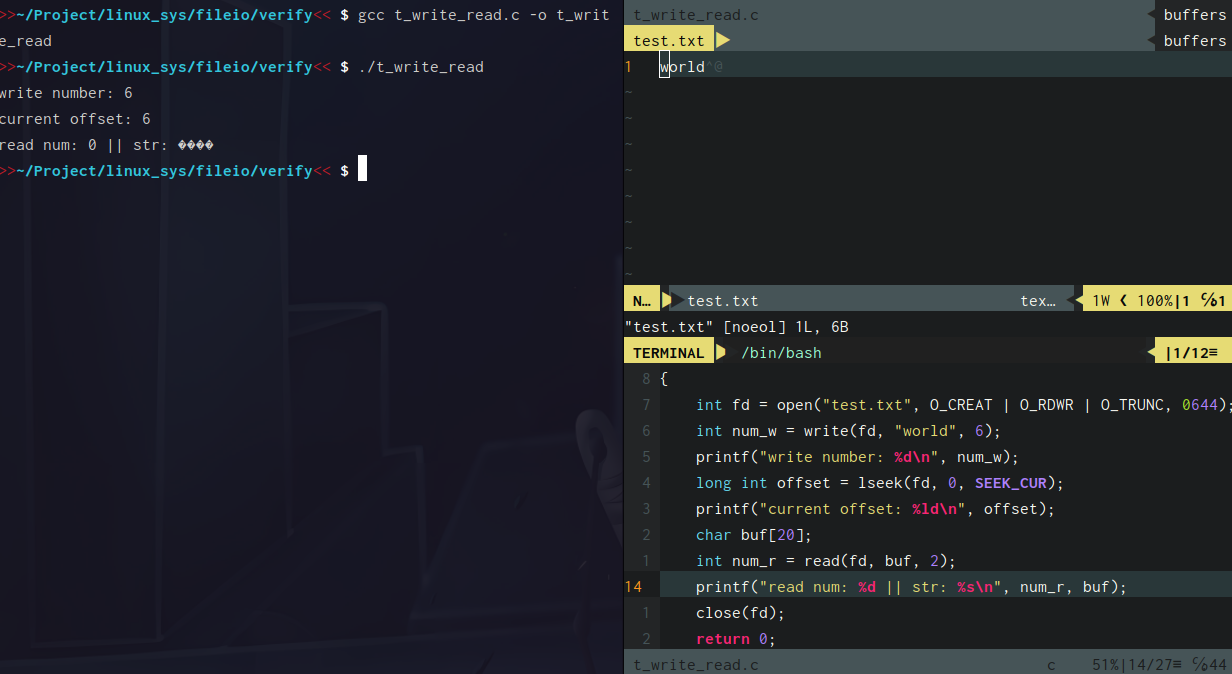
write
![5]()
![6]()
我们可以看到,write调用后,文件偏移的改变量就刚好是写入的字节数(打开文件时,文件偏移量一般是0)
-
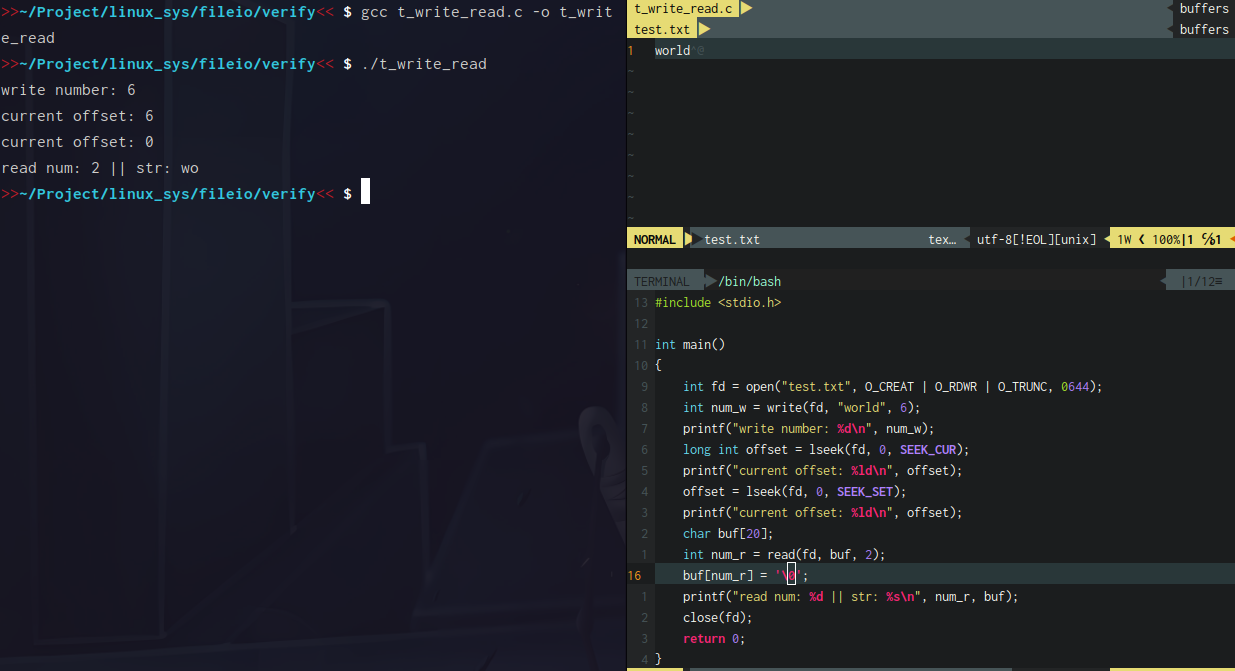
read
可以看到当我们向文件中写入数据后,在直接读取,结果读取到的字节数是0,也就是没有读取到内容,这是因为写入数据后,文件偏移量就改变了,在进行读取就是从文件偏移量的位置开始读啦
![7]()
这里我们在读取前,把文件偏移量设置为开头,也就是0,然后就读取2字节,文件总共有6字节,我们发现读取的字节数正好是2,没问题,可是把它用字符串的形式打印出来,可以看到wo正好是world的前两个字节,没错,可是后面是什么东西
这是因为,字符串的结束要用空字节做标志,这里读取到的内容不是一个字符串,仅仅是两个字节,因为没有空字节,所以打印字符串就会出错
![8]()
ok,我们这里手动给缓冲区加上空字节,然后在输出它,发现结果正确
![9]()
我们这里可以看到,读取内容后,文件偏移量也发生改变了
![10]()




总结
-
write和read都会改变文件偏移量,而文件偏移量决定了io的开始位置
-
write需要注意申请写入的字节数count不要超过buf的大小,这会引发未定义的行为,read就没关系
-
最后C语言中字符串是用空字节结尾的,所以实际大小比长度大1,然后read的内容不一定包括空字节,要打印的话,记得手动加上
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号