
现在使用的是Djago的ORM,只能在Django中使用!!其他数据库不一样
1、Django中的ORM
ORM -- 对象关系映射表!! Django中,用对象对应表,成员变量映射表的字段。
一个实例就是一个记录。。所有对表的操作就变成了对对象得出操作
功能:1、根据对象的数据类型生成表结构,2、将对象列表转化为SQL语句!3、将sql查询的结果转化为对象,列表
2、在pycharm中配置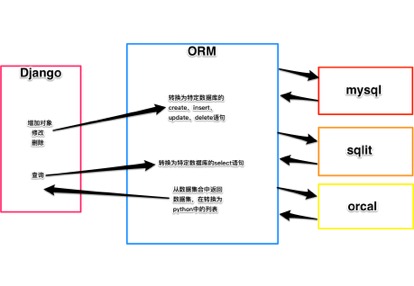
django 默认的数据库是:SQLite(轻量级数据库,android 也曾用过)
2.1、在项目的_init_.py中配置默认
## 把mysql作为默认的数据库-- 否则Django还是把SQLite作为默认数据库 import pymysql pymysql.install_as_MySQLdb()
2.2 、在全局配置settings中:
注释掉原来的默认数据库,添加上SQL的用户名、密码等信息
注释:
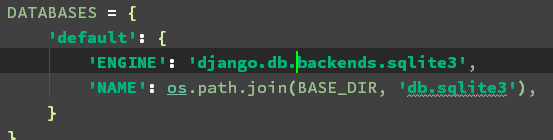
添加内容:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'django', # 你的数据库名称 'USER': 'root', # 你的数据库用户名 'PASSWORD': '111111', # 你的数据库密码 'HOST': '', # 你的数据库主机,留空默认为localhost 'PORT': '3306', # 你的数据库端口 } }
2.3 在models中,创建表对象
1 # Create your models here. 2 3 # create table book( 4 # name varchar(20), 5 # price float(4,2) 6 # ) 7 ## 创建表 -- 必须要继承models.Model,django才知道这个类是表 8 ## -- 这个表必须要有主键,没有的话,默认也会加上ID主键 9 class Boook(models.Model): 10 name = models.CharField(max_length=20) 11 price = models.FloatField() 12 pub_time = models.DateField() 13 14 class Author(models.Model): 15 name = models.CharField(max_length=32)
2.3 配置完成后:
执行: python3 manage.py makemigrations -- (因为我安装了py2和py3) 生成对应的表py文件 ## 用沙盒啊!笨蛋!
再执行:python3 manage.py migrate ----- 真正在数据库中生成表
3、(单表)记录的增删改查:
3.1表数据的添加:
1 --------------- views-------------- 2 def addbook(req): 3 # 添加一条记录的方式 4 # 方式1: 5 ## 1、实例化表对象 6 b = Book(name="python基础",price=99,author="dyl",pub_time="2018-4-1") 7 # 2、保存到数据库 8 b.save() 9 10 # 方式2: 这个方式不用保存!创建就可以了 11 # data : 事件格式必须是2010-9-1,否则直接报错!! 12 Book.objects.create(name="算法导论",price=128,author="图灵",pub_time="2010-9-1") 13 14 return HttpResponse("保存成功")
3.2、数据的修改:
1 def update(req): 2 #方法1: 3 ##先找到,把作者是图灵的所有书籍价格改为9999, QuerySet 有update对象 4 # Book.objects.filter(author="图灵").update(price=9999) 5 6 # 修改数据集的单个数据!! 7 # b = Book.objects.filter(author="图灵") 8 # 9 # print(b)#<QuerySet [<Book: Book object (2)>]> QuerySet数据类型 10 # # 意味着b 并不是一个对象,是一个数据集合 11 # print(type(b)) #<class 'django.db.models.query.QuerySet'> 12 # 13 # ## 取出集合中的第一个对象,就是我们想要的对象 14 # b[0].price=123 15 # b[0].save() ## 一定要保存!! ,否则无效 --- 16 17 ## 方法2: 18 b = Book.objects.get(author="图灵") 19 ## 取出集合中的第一个对象,就是我们想要的models对象 20 print(type(b)) #<class 'app01.models.Book'> 21 b.price=123 # 没有update方法!!models 22 b.save() ## 一定要保存!! ,否则无效 23 return HttpResponse("修改成功")
注意的问题:
1、使用对象.objects.filter(条件)的时候返回的是一个QuerySet数据集合,意味着数据不止一个!!
2、get方法返回的是一个models对象,它没有update方法,只能使用:对象.save()
3、我们推荐使用的是update方法,因为save方法,会把所有数据重新全部写一遍,效率很低!!
3.3、删除记录
1 def delete(req): 2 Book.objects.filter(author="dyl").delete() 3 return HttpResponse("删除成功")
3.4、查询记录
# 查询相关API: # <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 # <2>all(): 查询所有结果 # <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 #-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()-------- # <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 # <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 # <6>order_by(*field): 对查询结果排序 # <7>reverse(): 对查询结果反向排序 # <8>distinct(): 从返回结果中剔除重复纪录,但是主键相同,才是同一本书!!所以主要的用途是筛选相同的字段!! # <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 # <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。 # <11>first(): 返回第一条记录 # <12>last(): 返回最后一条记录 # <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False。
实例:
1 def select(req): 2 #1、取出所有数据 3 # BooKList = Book.objects.all() 4 # print(BooKList[0]) ##得到Qquery集合,里面是对象 ---<QuerySet [ <Book: Book object>,<Book: Book object> ....] > 5 6 #2、取出前3条数据-- 切片 -- 跟python一毛一样!! 7 BooKList = Book.objects.all()[:3] 8 9 #3、取第一个或者最后一个,可以用切片实现 10 # BooKList = Book.objects.last() 11 # BooKList = Book.objects.first() 12 13 #4、get 只能取出一条结果,才不会报错 -- 若是得到多条,或者不存在都会报错!!慎用! 14 # BooKList = Book.objects.get(id=1) ## 成功时,直接得到Book对象 15 16 #5、只取某个条件下的结果vaues -- 作者是图灵的书名!! 17 ret = Book.objects.filter(author="图灵").values("name") 18 print(ret) ##输出: 得到一个字典 <QuerySet [{'name': '算法导论'}, {'name': '数据结构'}]> 19 20 # 6、只取某个条件下的结果values_list -- 作者是图灵的书名!! 21 ret2 = Book.objects.filter(author="图灵").values_list("name") 22 print(ret2) ##输出: 得到一个元祖 <QuerySet [('算法导论',), ('数据结构',)]> 23 24 # 7、查询出除条件以外的书籍 25 ret3 = Book.objects.exclude(author="图灵").values() 26 ret4 = Book.objects.exclude(author="图灵") 27 print(ret4)## 输出:<QuerySet [<Book: GO>, <Book: 骆驼样子>, <Book: 悲惨世界>]> 28 29 30 #8、筛选或者过滤出的结果,去掉重复的数据 31 ret5 = Book.objects.all().values("name").distinct() 32 print('ret5 == ',ret5) 33 for i in ret5: 34 print(i) 35 return render(req,"index.html",{"BooKList":BooKList})
3.5 模糊查询--万能的双下划线 ,单表、多表都适用
##1、书本价格大于50 BooKList = Book.objects.filter(price__gt=50).values('name','price') BooKList = Book.objects.filter(name__icontains='g').values('name','price') #---------------了不起的双下划线(__)之单表条件查询---------------- # models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 # # models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 # models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in # # models.Tb1.objects.filter(name__contains="ven") # models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 # # models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and # # startswith,istartswith, endswith, iendswith,
4、多表查询--一对多
4.1 添加外键,产生主表和从表的关系
a、在创建表的时候,就添加外键
外键都是,建在多的那一方!!(这里出版社可以出版多本书,这里外键建在书的表中!)
1 class Book(models.Model): 2 name=models.CharField(max_length=20) 3 price=models.IntegerField() 4 pub_date=models.DateField() 5 publish=models.ForeignKey("Publish",models.DO_NOTHING)#外键,这里的第二个参数!!不知道是啥?? 6 #这个外键加上以后,publish字段变成了public_id字段!!
#Django会把publish外键关联到从表的主键上,publish变成了publish_id--- 不要手残加id!! ^-^ 8 def __str__(self): 9 return self.name 10 11 class Publish(models.Model): 12 name=models.CharField(max_length=32) 13 city=models.CharField(max_length=32) 14 15 def __str__(self): 16 return self.name
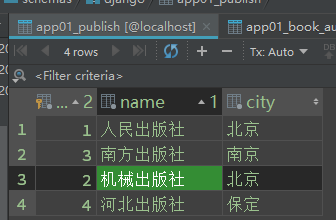
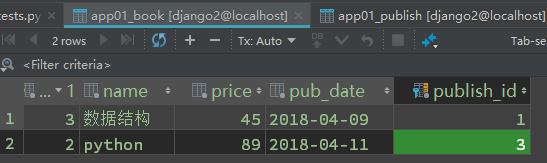
b、其他方式添加:
4.2 添加一个包含外键的记录
## 方法1、添加包含外键的记录 def addbook(req): # 方法1: publish_id数据库的字段值 # Book.objects.create(name="算法导论",price=88,pub_date="2018-8-8",publish_id=1)#表的外键字段!! #方法2: # 添加从表出版社对象给主表 public_obj = Publish.objects.filter(name="人民出版社")[0] Book.objects.create(name="Django",price=23,pub_date="2018-8-8",publish=public_obj) ## 从表对象 return HttpResponse("OKOK")
4.3 正向查询 -基于对象
直接通过主表外键关系,拿到从表的数据!
1 # 查数据的出版社信息!
2 # 1对多的关系,查询到的结果是一个对象!!! 3 # 主表找从表的数据! 4 # 获得书名python的信息-- 若是有两本书为python,报错! 5 book_obj = Book.objects.get(name="python")# get只能获得1个对象,否则报错!!! 6 print(book_obj.name) 7 print(book_obj.pub_date) 8 print(book_obj.publish.city) ## 直接. 查到数据 9 print(book_obj.publish.name)
4.4 反向查询-基于对象
从表通过主键反向查询主表的数据!!
1 ## 3、反向查询 2 # 人民出版社,出版的所有书籍 3 # 写法1: 4 pub_obj = Book.objects.filter(publish=1) ## 不适用! 5 print(pub_obj) 6 7 # 写法2: 比较复杂 8 # 在Publish表中取出一个出版社对象!!一个!! 9 pub_obj = Publish.objects.filter(name="人民出版社")[0] 10 #在Book表中过滤出与出版社对象相同的数据 11 ret = Book.objects.filter(publish=pub_obj).values("name","price") 12 print(ret) 13 14 ##写法3: ---- 推荐使用!! 15 # 从表 找主表的数据 16 ## 1、拿到出版社对象 17 pub_obj = Publish.objects.filter(name="人民出版社")[0] 18 # 2、出版社对象.book_set.all 反向拿到所有=出版社对象的书籍 19 # 从表对象.主表名_set.all 通过外键,反向拿到主表的数据 ## 这个名字可以改!! 20 print(pub_obj.book_set.all())#<QuerySet [<Book: 算法导论>, <Book: 数据结构>]> ##related_name
21 print(type(pub_obj.book_set))
4.5 查询记录-- 双下划线查找
1 ##1、查找人民出版出的书 2 ## 分析:结果在主表,条件在从表 3 ## 正向查找: 4 set = Book.objects.filter(publish__name="人民出版社") ##最简单! 5 print(set) 6 7 #2、查询pyhton的出版社 8 # 分析:最终是从表 条件在主表 9 ## 反向查找: 10 p1 = Publish.objects.filter(book__name="python").values("name") 11 print(p1) 12 13 #另外一种写法 14 p2 =Book.objects.filter(name='python').values("publish__name") 15 print(p2) 16 17 18 ##在北京的出版社,出版的所有书? 19 p3 = Book.objects.filter(publish__city="北京").values('name',"publish__name") 20 print(p3) 21 22 ##2018年初过多少本书? 23 ret4 = Book.objects.filter(pub_date__lt="2018-7-1",pub_date__gt="2018-01-01").values("name") 24 print(ret4) 25 return HttpResponse("OKOK")
5、多对多
5、1自动生成第三张表
通过第三个表(Django自动创建,写上多对多),这个表处理自己的主键外,另外两个字段是另外两个表的主键:
authors = models.ManyToManyField("Author") ## 多对多
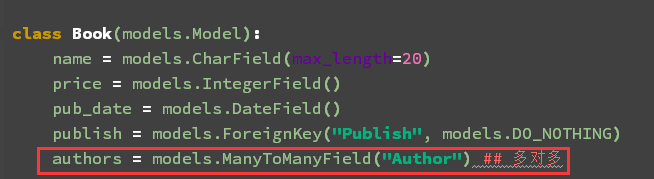
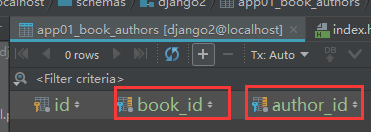
第三张表:
这个表虽然真实存在在数据库,但是我们不能通过ORM操作它。。。只能通过对象!!
但是,但是,我们这个表自家创建的情况下,就可以用ORM的方法,去操作了!!
5.1.1 写入多对多的记录
1 ## 1、添加多对多的记录--只能通过对象 2 # 一本书有三个作者 3 book_obj = Book.objects.get(id=4) 4 5 # author_obj = Author.objects.get(id=1) # 取一个作者 6 # book_obj.authors.add(author_obj) #添加 7 8 author_obj = Author.objects.all()##取出3个作者信息 9 book_obj.authors.add(*author_obj)## 把作者信息放到这本书的关系中,加*号 10 11 #2、删除记录-- 多对多关系 12 # book_obj.authors.remove(*author_obj)#移除多对多的关系,移除一条同理! 13 # book_obj.authors.remove(id =1) ## 移除表中第一条多对多的关系
#3、查询
ret2 = Book.objects.filter(authors__name="alex").values("name","price") ##因为Book表中有外键这个字段,所有可以这样查!
print(ret2)
5.2手动创建第三张表
先去掉 ManyToManyField,
再手动创建之后就可以用ORM的方法,添加记录
1 ## 手动创建第三张表 2 class Book_Author(models.Model): 3 book = models.ForeignKey("Book",models.DO_NOTHING) 4 author=models.ForeignKey("Author",models.DO_NOTHING)
再执行 python3 manage.py makemigrations 和 python3 manage.py migrate 重新生成表!!
1 ## 给手动创建的表添加记录 2 Book_Author.objects.create(book_id=2,author_id=3) 3 4 #1、 对象查询 5 # obj = Book.objects.get(id=2) 6 # print(obj.book_author_set.all()[0].author) 7 8 #2、使用__查询 9 # alex 出的书籍名称和价格 10 # book_author:是表名,第三张表 11 #book_author__author:关联的作者表 12 #book_author__author__name:作者的名字 13 14 ret = Book.objects.filter(book_author__author__name="alex").values("name","price")## 因为没有关联字段(外键),只能通过第三张表,这样查询数据 15 print(ret)
主要是有点乱!作为补充
##########################################################################################################################################
首先创建3张表:
1 # Create your models here. 2 # 1、班级表 3 class Classes(models.Model): 4 title = models.CharField(max_length=32) 5 m = models.ManyToManyField("Teachers") # 自动创建第三张表 6 7 8 # 2、老师表 9 class Teachers(models.Model): 10 name = models.CharField(max_length=32) 11 12 ## 3、学生表 13 class Student(models.Model): 14 username = models.CharField(max_length=32) 15 age = models.IntegerField() 16 gender = models.BooleanField() ##男或者女 17 cs = models.ForeignKey("Classes",related_name='s') ## 外键约束,cs_id列名 ,cs本身是代表Classes类的一个对象!!!! 18 ## 可以将student_set的名字改为其他,通过 related_name
1、单表操作
1 ## 1、添加记录的方式 2 #1、直接写入数据,等同于下面两句话 3 Teachers.objects.create(name="周老师") 4 #2、创建对象在保存数据!! 5 obj = Teachers(name='周老师') 6 obj.save() # 必须保存 7 8 ## 2、删除数据 9 Teachers.objects.filter(id=1).delete() 10 11 ## 3、改变数据 12 # 1、更新所有数据 13 Teachers.objects.all().update(name='大傻子') 14 #2、更新一个数据 15 Teachers.objects.filter(id=1).update(name='大傻子2') 16 17 #4、查询数据 18 Teachers.objects.filter(id=1,name='周老师') 19 ## 神器的双下划线!!? 20 Teachers.objects.filter(id__gt=1) ## id大于1 21 Teachers.objects.filter(id__gt=1).first() ## id大于1,只取第一个
2、一对多跨表操作
1 # 一对多表 !!! -- 跨表查询,外键条件 2 # 这个外键代表的是,约束表的一个对象,通过这个外键才能做跨表查询!!! 3 # 自身表这个外键在数据库的真实字段名是:外键名_id 4 # 1、增加数据-- 要么增加一个外键关联的对象,要么是外键名_id 5 Student.objects.create(username='大傻子', age=12, gender='女', cs_id=1) ##cs_id列名!! 关键 6 Student.objects.create(username='大傻子', age=12, gender='女', cs=Classes.objects.filter(id=1).first()) ##cs 对象!! 关键 7 8 # 取出全部数据 9 # 但凡是all或者filter都是一个QuerySet集合,集合里面全部是对象!! 10 # 2、查找数据- 跨表查询l 11 ret = Student.objects.all() 12 for i in ret: ## 遍历QuerySet集合,用点!!!!!! 在filter中,跨表查询用双下划线!! 13 print(i.username) 14 print(i.age) 15 print(i.gender) 16 print(i.cs_id) ##一个数 对应表的一个橘绿 17 print(i.cs.id) # 一个对象.id!!! 18 print(i.cs.title) # 一个对象.title!!! 19 20 # 3、删除数据 21 Student.objects.filter(id= 1).delete() ## 删除id=1 的学生 22 Student.objects.filter(cs_id=1).delete() ## 把三班的人全部删除 23 24 25 # 样例: 26 # 方法1: 输入班级的id,删除对应的学生 27 # cid = input("请输入班级的id") 28 # Student.objects.filter(id=cid).delete() 29 # 30 # # 方法2:输入班级的名称,删除对应的学生 31 # sid = input('请输入班级的名称') 32 # Student.objects.filter(cs__name=sid).delete() ##若是filter做跨表查询,就一定要用双下划线!!规定!!若是遍历!! 33 # Student.objects.filter(cs=Classes.objects.filter(title=sid)).delete()
3、多对多的跨表操作
1 ## 多对多的操作 2 ''' 3 班级: 4 id title 5 1 1班 6 老师: 7 id title 8 1 abc 9 10 mmanytomany:不会生成一个字段!! 生成多对多的表,字段为两个表的id 11 12 多对多的表: 13 id 班级id 老师id 14 15 16 ## 这个第三张表,不能直接操作!!,只能间接操作,只能通过manytomany那个字段操作!! 17 ''' 18 ## 操作第三张表 19 obj = Classes.objects.filter(id=1).first() ##取出id=1 的对象 20 21 ## 1、添加 22 obj.m.add(2) ## obj.m 表示第三张表 obj.m.add: 表示在第三张表添加一条记录 23 ## 执行完成,就是第三张表 班级id=1 老师id=2 24 25 # 同时加多个 26 obj.m.add([3, 4, 5]) ##班级id=1 老师id=[3,4,5] 一个班安排3个老师!! 27 28 ## 2、删除 29 obj.m.remove([3, 4]) ##删除班级id=1的老师id为3、4的老师 30 obj.m.clear() ##班级id=1 的所有老师,全部删除!! 31 32 obj.m.set([1, 2, 3]) ##班级id=1 的老师,更新为id为1、2、3的老师; 原来存在老师被清除 33 34 ##3、查找 某个班级的所有老师 35 ## 相当于join,联表查询!!! 36 obj = Classes.objects.filter(id=1).first() 37 ret = obj.m.all() ## obj.m:第三张表,把全部取出来,得到的老师的对象集合!! 38 ## manytomany 关联的是老师 ret=<QuerySet[obj().....]> ## 39 40 41 # 总结: 42 1、ORM中,类代表数据库的一张表,对象代表一条记录 43 2、FK字段,代表关联表的一行数据(类的对象) 44 3、manytomany,自动生成第三张表,依赖关联表对第三张表进行操作!! 45 4、正向查询: 通过__(双下划线跨表查询)--- 有外键关系 46 5、反向查询: 通过 --小写类名_set--- (正向反向,也是通过外键的关系的,隐约)-- 无外键 但是,这个小写类名_set可以更改!!
4、取出数据的类型
1 # 取出的数据一种是集合、一种是字典、一种是元祖 ,都是QuerySet 2 3 # 实例: 所有学生以及所在的班级 4 # 1、 5 obj_list = Student.objects.all() ## 等价于 select * from Student 这个集合 [obj,obj,obj] 6 for row in obj_list: 7 row.username, row.cs_id, row.cs.title ## 里面是对象 8 # 2、 9 stu_list = Student.objects.all().values("id","username") ##v alues()表示要取某些字段 10 ## values():# 里面是字典!! [{'id':1 ,'username':'xx'}] 11 12 # 3、 13 stu_list = Student.objects.all().values_list() 14 ## [(1,'root')] #里面是元祖 15 16 # 取出姓名,以及所在的班级 17 stu_list = Student.objects.all().values("username","cs__name") 18 for row in stu_list: 19 print(row['username'],row['cs__name '])
5、理论上的正向查询和反向查询
1 ##########################重点的重点!!!##################################### 2 3 ## 拿到3班的学生 4 ## 1、正向查找 5 ret = Student.objects.filter(cs__title='2班') ## 拿到对象__ 正向跨表 正向跨表和模糊查询用双下划线!! 反向查询用:没有外键的表名_set 6 print(ret) 7 8 ## 2、反向查找 -- 反向跨表 9 # student有个外键class,class直接拿不到student,但是可以通过隐藏的student_set方法@@!!反向 10 obj =Classes .objects.filter(title='2班').first() 11 print(obj.id) 12 print(obj.title) 13 ##小写的类名_set,也可以related_name='s' ,改变student_set = s 14 # print(obj.student_set.all()) ## 拿到反向的queryset的对象!!!! 等价于上面那个!! 15 print(obj.s.all()) ## 改成了s 等价于上面这个一句!! 16 17 18 ret = Classes.objects.all().values('id','title') 19 print(ret) 20 ret = Classes.objects.all().values('id','title','s') ## s是隐藏字段, student_set 21 ## 就相当于sql里面join,谁在前面,谁是主表!! 22 print(ret) 23 24 ## 25 Student.objects.all().values('username','cs__title') #Student 主表 26 Classes.objects.all().values('title','s__username') #Classes 主表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号