




零拷贝(Zero Copy)
以前刚接触Dubbo框架的时候,也随带粗浅的了解了一下Netty,但是现在时间久了,有必要重新熟悉下Netty,并且记录下学习笔记。
首先需要了解一个概念零拷贝(Zero Copy),零拷贝在Netty中的位置还是举足轻重,如下图(镇楼)
来源Netty官网:https://netty.io/index.html
零拷贝(Zero Copy),涉及到操作系统中的一些知识,深感自己的这方面的知识浅薄,如果有谬误,也属于正常。
传统IO
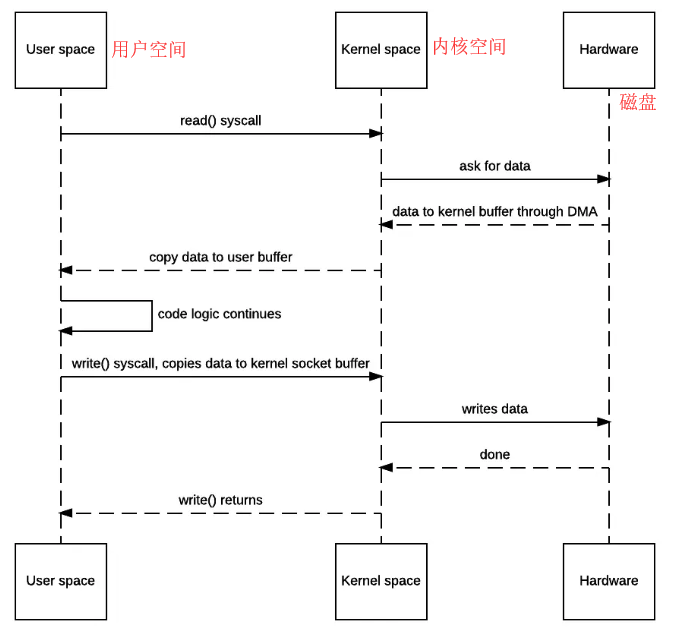
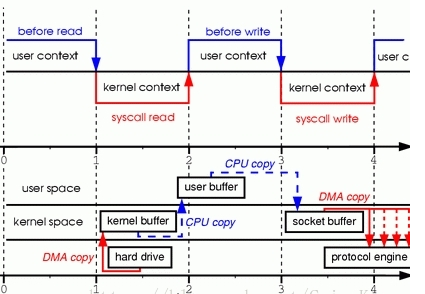
- JVM调用read()
- OS会从用户态陷入内核态,向disk请求调用读取文件数据,之后DMA会把文件数据读入到内存的内核地址空间的buffer中。
- OS内核再把上面buffer的文件数据通过上下文切换copy到用户态的buffer,我们的程序就可以读到了数据。
- 我们程序读到文件内容做了某些修改后调用write()。
- OS再次上下文切换到用户态把文件数据copy到内核态socket描述符的buffer,最后数据刷出到socket。
- 刷到socket后,OS上下文切换回用户态,返回JVM的程序成功。
传统IO:4次OS上下文切换,2次昂贵的文件数据拷贝。
改进版本一: sendfile()/transferTo() 实现zero-copy
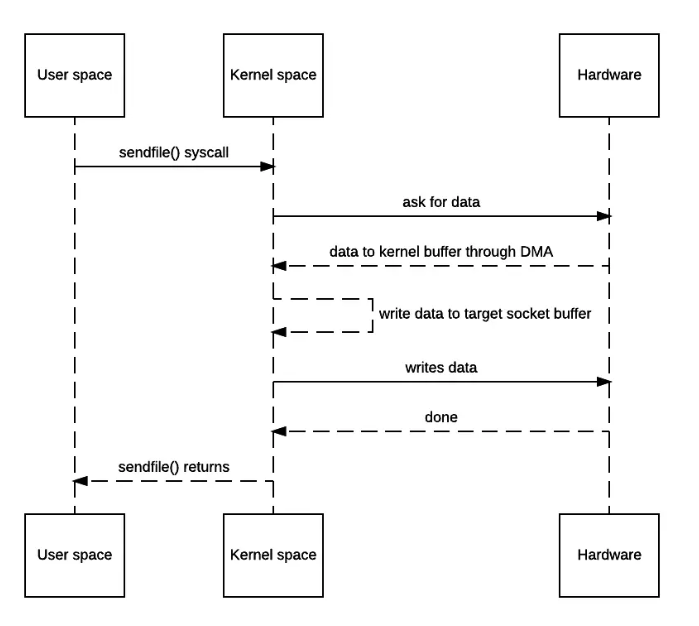
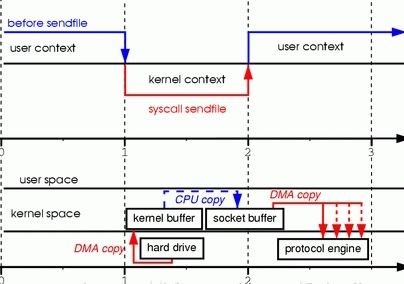
- 发出sendfile系统调用,导致用户空间到内核空间的上下文切换(第一次上下文切换)。通过DMA将磁盘文件中的内容拷贝到内核空间缓冲区中(第一次拷贝: hard driver ——> kernel buffer)。
- 然后再将数据从内核空间缓冲区拷贝到内核中与socket相关的缓冲区中(第二次拷贝: kernel buffer ——> socket buffer)。
- sendfile系统调用返回,导致内核空间到用户空间的上下文切换(第二次上下文切换)。通过DMA引擎将内核空间socket缓冲区中的数据传递到协议引擎(第三次拷贝: socket buffer ——> protocol engine)。
版本一实现的I/O:只使用了2次用户空间与内核空间的上下文切换,以及3次数据的拷贝(1次CPU执行的,2次DMA执行的)。 你可能会说操作系统仍然需要在内核内存空间中复制数据(kernel buffer —>socket buffer)。 是的,但从操作系统的角度来看,这已经是零拷贝,因为没有数据从内核空间复制到用户空间。 内核需要复制的原因是因为通用硬件DMA访问需要连续的内存空间(因此需要缓冲区)。
改进版本二: sendfile()+DMA scatter-and-gather实现zero-copy

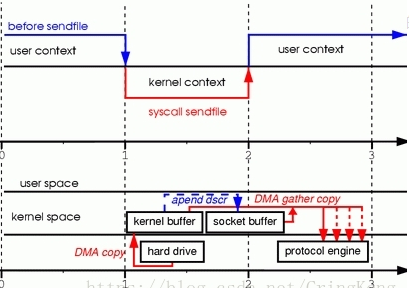
socket buffer 并非copy kernel buffer中的数据,拷贝fd(kernel buffer内存地址和偏移量), 协议引擎(protocol engine) 从 kernel buffer和socket buffer 中gather(收集)信息,利用的就是scatter/gather的思想。
- 发出sendfile系统调用,导致用户空间到内核空间的上下文切换(第一次上下文切换)。通过DMA引擎将磁盘文件中的内容拷贝到内核空间缓冲区中(第一次拷贝: hard drive ——> kernel buffer)。
- 没有数据拷贝到socket缓冲区。取而代之的是只有相应的描述符信息会被拷贝到相应的socket缓冲区当中。该描述符包含了两方面的信息:kernel buffer的内存地址,kernel buffer的偏移量。
- sendfile系统调用返回,导致内核空间到用户空间的上下文切换(第二次上下文切换)。DMA gather copy根据socket缓冲区中描述符提供的位置和偏移量信息直接将内核空间缓冲区中的数据拷贝到协议引擎上(第二次拷贝: kernel buffer ——> protocol engine),这样就避免了最后一次CPU数据拷贝。
版本二实现的I/O:只使用了2次用户空间与内核空间的上下文切换,以及2次数据的拷贝,而且这2次的数据拷贝都是非CPU拷贝。这样一来我们就实现了最理想的零拷贝I/O传输了,不需要任何一次的CPU拷贝,以及最少的上下文切换。
改进版本三,通过mmap实现zero-copy
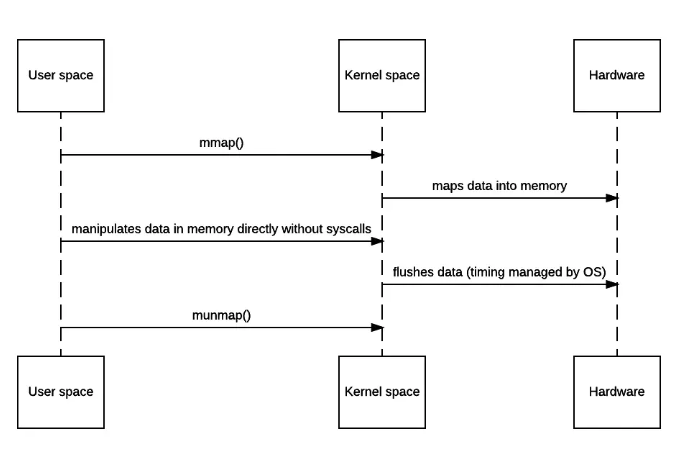
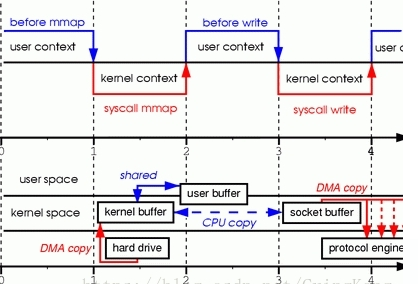
具体分析消耗步骤如下:
- 发出mmap系统调用,导致用户空间到内核空间的上下文切换(第一次上下文切换)。通过DMA引擎将磁盘文件中的内容拷贝到内核空间缓冲区中(第一次拷贝: hard drive ——> kernel buffer)。
- mmap系统调用返回,导致内核空间到用户空间的上下文切换(第二次上下文切换)。接着用户空间和内核空间共享这个缓冲区,而不需要将数据从内核空间拷贝到用户空间。因为用户空间和内核空间共享了这个缓冲区数据,所以用户空间就可以像在操作自己缓冲区中数据一般操作这个由内核空间共享的缓冲区数据。
- 发出write系统调用,导致用户空间到内核空间的上下文切换(第三次上下文切换)。将数据从内核空间缓冲区拷贝到内核空间socket相关联的缓冲区(第二次拷贝: kernel buffer ——> socket buffer)。
- write系统调用返回,导致内核空间到用户空间的上下文切换(第四次上下文切换)。通过DMA引擎将内核空间socket缓冲区中的数据传递到协议引擎(第三次拷贝: socket buffer ——> protocol engine)
版本三实现的I/O: 4次用户空间与内核空间的上下文切换,以及3次数据拷贝。其中3次数据拷贝中包括了2次DMA拷贝和1次CPU拷贝。明显,它与传统I/O相比仅仅少了1次内核空间缓冲区和用户空间缓冲区之间的CPU拷贝。这样的好处是,我们可以将整个文件或者整个文件的一部分映射到内存当中,用户直接对内存中对文件进行操作,然后是由操作系统来进行相关的页面请求并将内存的修改写入到文件当中。我们的应用程序只需要处理内存的数据,这样可以实现非常迅速的I/O操作。
=========================================================================================================================================
我只是一粒简单的石子,未曾想掀起惊涛骇浪,也不愿随波逐流
每个人都很渺小,努力做自己,不虚度光阴,做真实的自己,无论是否到达目标点,既然选择了出发,便勇往直前
我不能保证所有的东西都是对的,但都是能力范围内的深思熟虑和反复斟酌


 浙公网安备 33010602011771号
浙公网安备 33010602011771号