Redis 基础特性讲解
Redis基础杂项小节
是什么
Redis: Remote Dictionary Server(远程字典服务器)
是一个高性能的(key/value) 分布式内存数据库,是当前热门的NoSql数据库之一
能干嘛
- 内存存储和持久化
- 模拟类似于HttpSession这种需要设定过期时间的功能
- 发布、订阅消息系统 (横向对比MQ,有一定差距,毕竟不是专门做消息系统的中间件)
- 定时器、计数器
去哪下
Redis启动后基础知识讲解
- 单机版默认16个数据库,集群环境该配置不生效,只有一个数据库,默认Select 0;
- Dbsize 查看当前数据库的key的数量
- Flushdb 清空当前库
- Flushall 通杀全部库
- 端口号默认是6379
- 单进程,单线程

Redis数据类型
常用的五大数据类型
String
String是redis最基本的类型,可以理解成与Memcached一模一样的类型,一个key对应一个value。
String类型是二进制安全的。String类型的值最大能存储512MB

Hash
Redis hash 是一个键值(key->value)对集合。
Redis hash 是一个string 类型的 field 和 value的映射表 , hash 特别适合用于存储对象

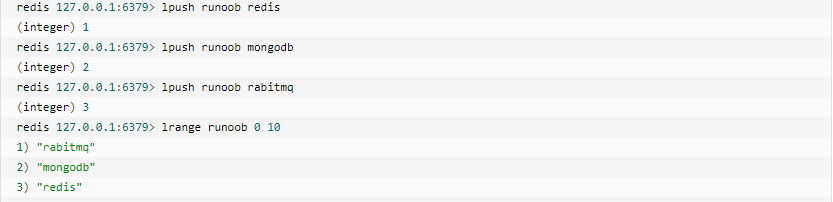
List
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
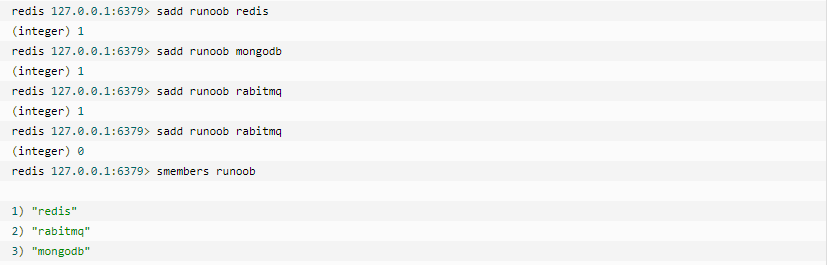
Set
Redis的Set是string类型的无序集合。它是通过哈希表来实现的。所以添加,删除,查找的复杂度都是O(1)
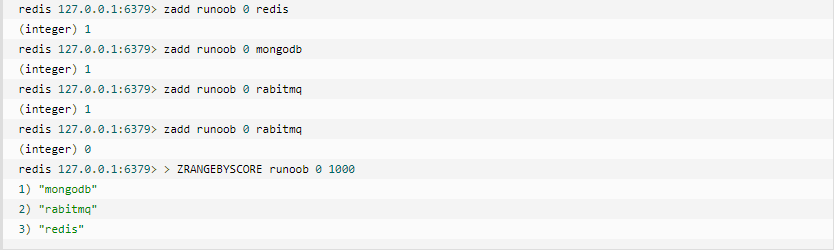
Zset
Redis Zset和Set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大排序的。Zset的成员是唯一的,但分数(score)却可以重复。
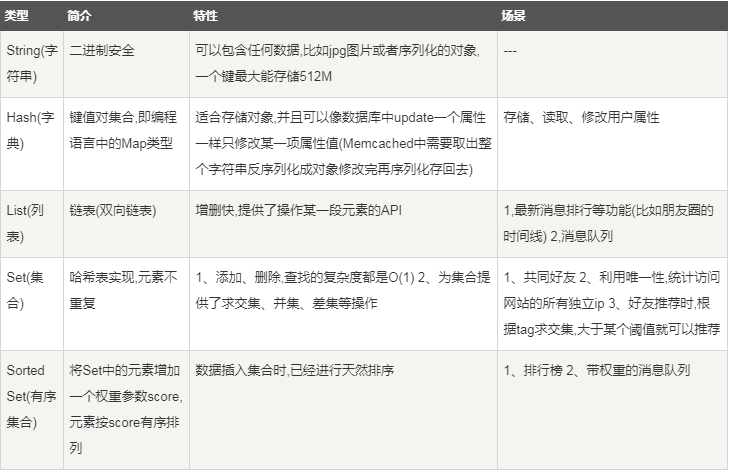
小结
各个数据类型应用场景:
高级‘玩家’才知道的其他数据类型
Bitmap
Redis从2.2.0版本开始新增了setbit,getbit,bitcount等几个bitmap相关命令。虽然是新命令,但是并没有新增新的数据类型,因为setbit等命令只不过是在set上的扩展。在bitmap上可执行AND,OR,XOR以及其它位操作。
HyperLogLog
HyperLogLog 可以接受多个元素作为输入,并给出输入元素的基数估算值:
- 基数:集合中不同元素的数量。比如 {'apple', 'banana', 'cherry', 'banana', 'apple'} 的基数就是 3 。
- 估算值:算法给出的基数并不是精确的,可能会比实际稍微多一些或者稍微少一些,但会控制在合
理的范围之内。
HyperLogLog 的优点是,即使输入元素的数量或者体积非常非常大,计算基数所需的空间总是固定的、并且是很小的。
每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基
数。但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以
HyperLogLog 不能像集合那样,返回输入的各个元素。
使用HyperLogLog进行数据统计时,需要考虑三要素:
- 是否需要很少的内存去解决问题
- 是否能容忍一定误差
- 是否需要单挑数据
首先,hyperloglog有一定的错误率,在使用hyperloglog进行数据统计的过程中,hyperloglog给出的数据不一定是对的
按照维基百科的说法,使用hyperloglog处理10亿条数据,占用1.5Kb内存时,错误率为2%其次,没法从hyperloglog中取出单条数据,这很容易理解,使用16KB的内存保存100万条数据,此时还想把100万条数据取出来,显然是不可能的
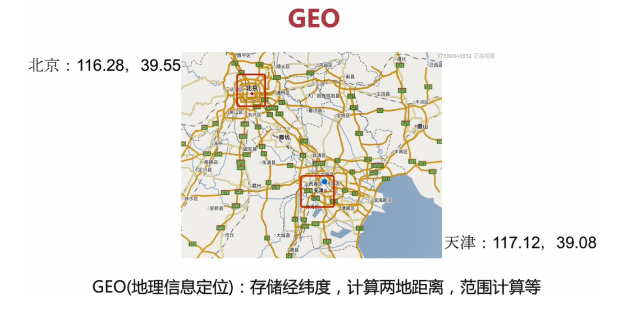
GEO
GEO即地址信息定位
可以用来存储经纬度,计算两地距离,范围计算等
PipeLine
流水线功能,允许客户端可以一次发送多条命令,而不等待上一条命令执行的结果,主要的核心就是降低了多命令交互时网络通信的时间。
Redis的持久化
RDB (Redis DataBase)
是什么
在指定的时间间隔内将内存中的数据集快照写入磁盘,它恢复时是将快照文件直接读到内存里
Redis会单独创建(fork)一个子进程来进行持久化,会将数据写入到一个临时文件,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行IO操作的,确保了极高的性能。
如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那么RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
配置位置 (redis.conf)

RDB 保存的是 dump.rdb 文件
触发与恢复
触发:配置、save/bgsave命令、flushall命令
- 配置文件默认的快照配置
- 手动执行 save 或者 bgsave 命令
- 执行flushall 命令,也会产生dump.rdb文件,但里面是空的,无意义
SAVE:save时只管保存,其他不管,全部阻塞
BGSAVE:redis会在后台异步进行快照操作,快照同时可以响应客户端请求
恢复:将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可
AOF
是什么
以日志的形式来记录到每个写操作,将Redis执行过的所有写指令记录下来
配置位置
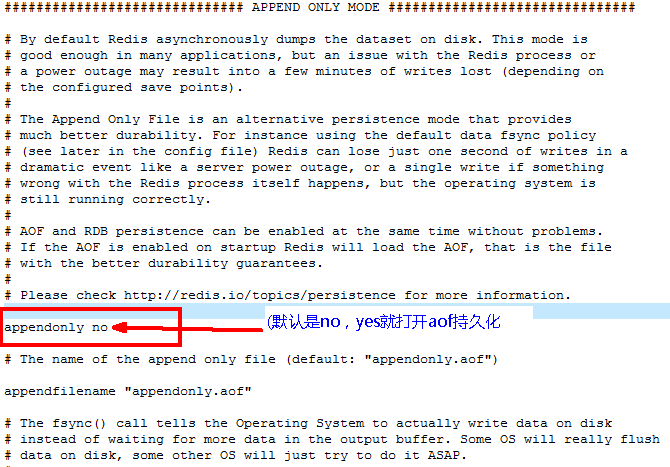
AOF保存的是 appendonly.aof文件
AOF启动/修复/恢复 以及 Rewrite
正常恢复:
启动:设置YES,修改默认的 appendonly no,改为yes
将有数据的 aof 文件复制一份保存到对应目录 (config get dir)
恢复:重启redis然后重新加载
异常恢复:
启动:设置YES,修改默认的 appendonly no,改为yes
备份被写坏的AOF文件
修复:Redis-check-aof --fix 进行修复
恢复:重启redis然后重新加载
Rewrite
是什么: AOF采用文件追加的方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过设定的阀值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集,可以使用命令bgrewriteaof
重写机制:AOF文件持续增长而过大时,会fork出一条新进程来将文件重写 (也就是先写临时文件最后再rename),遍历新进程的内存中的数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式,重写了一个新的aof文件,这点和快照类似
触发机制: Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发
每修改同步:appendfsync always 同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差
每秒同步:appendfsync everysec 异步操作,每秒记录 如果一秒内宕机,有数据丢失
不同步:appendfsync no 从不同步
总结
-
RDB 持久化方式能够在指定的时间间隔能对你的数据进行快照存储
-
AOF持久化方式记录每次对服务器写的操作,当体积过大时会触发重写机制
-
只做缓存:当然也可以不使用任何持久化方式
-
同时开启两种持久化的方式:
在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢?作者建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),快速重启,而且不会有AOF可能潜在的bug,留着作为一个万一的手段。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号