Kafka 问题分析以及面试总结
Kafka 问题分析以及面试总结
1、面试官:你简单说明下你使用Kafka的场景吧?
候选者:使用消息队列的目的总的来说可以有三种情况:解耦、异步和削峰。
2、面试官:嗯,那我想问下,你觉得为什么消息队列能做到削峰? 或者换个问法,为什么Kafka能承载这么大的QPS?
候选者:消息队列「最核心」的功能就是把生产的数据存储起来,然后给各个业务把数据再读取出来。跟我们处理请求时不一样:在业务处理时可能会调别人的接口,可能会需要去查数据库…等等等一系列的操作才行。在存储消息时,Kafka内部是顺序写磁盘的,并且利用了操作系统的缓冲区来提高性能。在读写数据中也减少CPU拷贝文件的次数【零拷贝】。
3、面试官:嗯,你既然提到减少CPU拷贝文件的次数,可以给我说下这项技术吗?
候选者:嗯,可以的,其实就是零拷贝技术。
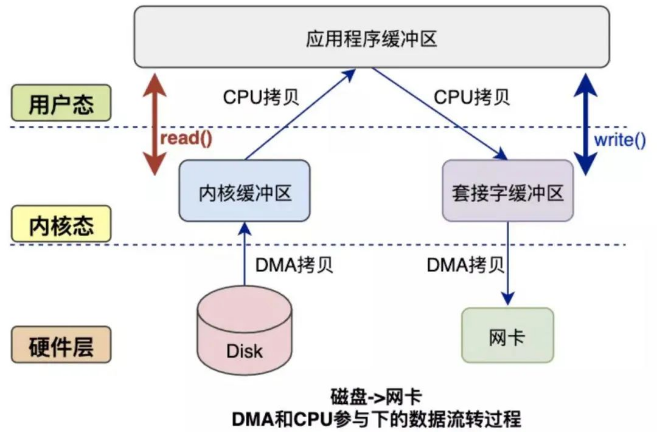
比如我们正常调用read函数时,会发生以下的步骤:
1. DMA把磁盘数据的拷贝到读内核缓存区。
2. CPU把读内核缓冲区的数据拷贝到用户空间。
正常调用write函数时,会发生以下的步骤:
1. CPU把用户空间的数据拷贝到Socket内核缓存区。
2. DMA把Socket内核缓冲区的数据拷贝到网卡。
可以发现完成「一次读写」需要2次DMA拷贝,2次CPU拷贝。而DMA拷贝是省不了的,所谓的零拷贝技术就是把CPU的拷贝给省掉。并且为了避免用户进程直接操作内核,保证内核安全,应用程序在调用系统函数时,会发生上下文切换(上述的过程一共会发生4次)。目前零拷贝技术主要有:mmap 和 sendfile,这两种技术会一定程度下减少上下文切换和CPU的拷贝。
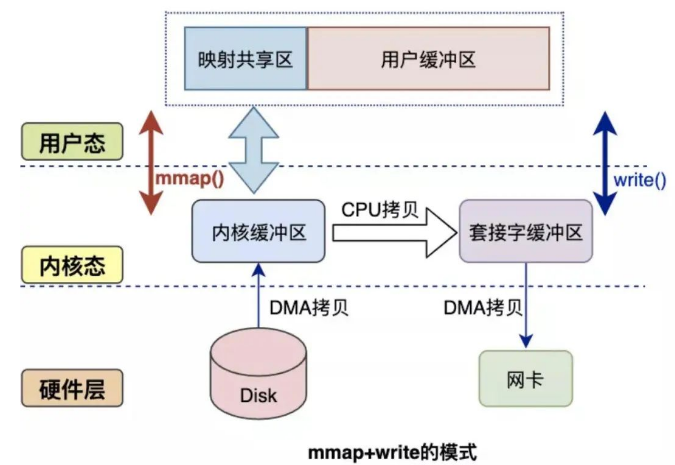
比如说:mmap是将读缓冲区的地址和用户空间的地址进行映射,实现读内核缓冲区和应用缓冲区共享。从而减少了从读缓冲区到用户缓冲区的一次CPU拷贝。
使用mmap后一次读写就可以简化为:
一、DMA把硬盘数据拷贝到读内核缓冲区。
二、CPU把读内核缓存区拷贝至Socket内核缓冲区。
三、DMA把Socket内核缓冲区拷贝至网卡。
而sendfile+DMA Scatter/Gather则是把读内核缓存区的文件描述符/长度信息发到Socket内核缓冲区,实现CPU零拷贝。
使用sendfile+DMA Scatter/Gather一次读写就可以简化为:
一、DMA把硬盘数据拷贝至读内核缓冲区。
二、CPU把读缓冲区的文件描述符和长度信息发到Socket缓冲区。
三、DMA根据文件描述符和数据长度从读内核缓冲区把数据拷贝至网卡。
回到Kafka上:
- 从Producer->Broker,Kafka是把网卡的数据持久化硬盘,用的是mmap(从2次CPU拷贝减至1次)。
- 从Broker->Consumer,Kafka是从硬盘的数据发送至网卡,用的是sendFile(实现CPU零拷贝)。
4、面试官:你觉得Kafka会丢数据吗?
候选者:嗯,使用Kafka时,有可能会有以下场景会丢消息:
1、我们用Producer发消息至Broker的时候,就有可能会丢消息。
如果你不想丢消息,那在发送消息的时候,需要选择带有 callBack的api进行发送。其实就意味着,如果你发送成功了,会回调告诉你已经发送成功了。如果失败了,那收到回调之后自己在业务上做重试就好了。
2、等到把消息发送到Broker以后,也有可能丢消息。
一般我们的线上环境都是集群环境下嘛,但可能你发送的消息后broker就挂了,这时挂掉的broker还没来得及把数据同步给别的broker,数据就自然就丢了。不想丢数据,那就使用带有callback的api,设置 acks、retries、factor等等些参数来保证Producer发送的消息不会丢就好啦。
3、一般来说,还是client 消费 broker 丢消息的场景比较多,那你们在消费数据的时候是怎么保证数据的可靠性的呢?
首先,要想client端消费数据不能丢,肯定是不能使用autoCommit的,所以必须是手动提交的。
5、面试官:消息重复消费,你们这业务怎么实现幂等性的呢?
候选者:最终的幂等性是依赖数据库的唯一Key来保证的(唯一Key实际上也是订单编号+状态)
6、面试官:你们那边遇到过顺序消费的问题吗?
只需要把相同userId/orderId发送到相同的partition(因为一个partition由一个Consumer消费),又能解决大部分消费顺序的问题了呢。
7、kafka 消息重复消费问题?
7.1、Producer端:
Producer的send()方法可能会出现异常,配合生产者参数retries>0,生产者会在出现可恢复异常的时候进行重试。若出现不可恢复异常的时候,配合send()的异步发送方式,则可能在回调函数中进行消息重发。上述均可能导致消息重复。
解决方法
Kafka的幂等性就是为了避免出现生产者重试的时候出现重复写入消息的情况。开启幂等性功能配置(该配置默认为false)如下:
enable.idempotence
7.2、Consumer端:
- 强行kill线程,导致消费后的数据,offset没有提交(消费系统宕机、重启等)。
- 设置offset为自动提交,关闭kafka时,如果在close之前,调用 consumer.unsubscribe() 则有可能部分offset没提交,下次重启会重复消费。
- 消费后的数据,当offset还没有提交时,partition就断开连接。比如,通常会遇到消费的数据,处理很耗时,导致超过了Kafka的session timeout时间(0.10.x版本默认是30秒),那么就会re-blance重平衡,此时有一定几率offset没提交,会导致重平衡后重复消费。当消费者重新分配partition的时候,可能出现从头开始消费的情况,导致重发问题。
解决:
1、设置offset自动提交为false
spring.kafka.consumer.enable-auto-commit=false
spring.kafka.consumer.auto-offset-reset=latest
2、消费者在创建时会有一个属性max.poll.interval.ms(默认间隔时间为300s)
如果消费者在默认的5分钟内没有处理完这一批消息。就会触发Kafka的Rebalance机制,从而导致offset自动提交失败。而Rebalance之后,消费者还是会从之前没提交的offset位置开始消费,从而导致消息重复消费。
解决办法:
提高消费端的处理性能避免触发Balance,比如可以用多线程的方式来处理消息,缩短单个消息消费的时长。或者还可以调整消息处理的超时时间,也还可以减少一次性从Broker上拉取数据的条数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号