mmdetection faster-rcnn yolo
mmdetection安装过程中依靠https://github.com/open-mmlab/mmdetection/blob/master/docs/get_started.md
然后在安装第三步Install mmcv-full时,发现自己的cuda是10.1的,然后pytorch是1.7.1的然后就用了这条命令
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.7.1/index.html
实际上是错误的,但是没有报错,他就直接给你按了一个最新版本的mmcv-full,这和我想要的是不一样的,我要的是
cuda10.1,pytorch1.7.1的。这是因为这个地址是不存在的
https://download.openmmlab.com/mmcv/dist/cu101/torch1.7.1/index.html
想要得到cuda10.1,pytorch1.7.1的mmcv-full,就需要用
https://download.openmmlab.com/mmcv/dist/cu101/torch1.7.0/index.html
因为这个地址是存在的
这是从mmcv-full的参考表格里知道的,连接是这个https://mmcv.readthedocs.io/en/latest/#install-with-pip
表格是这个,这里的torch1.7就指的是torch1.7.0,在那个http地址上既不能写成torch1.7,也不能写成torch1.7.1
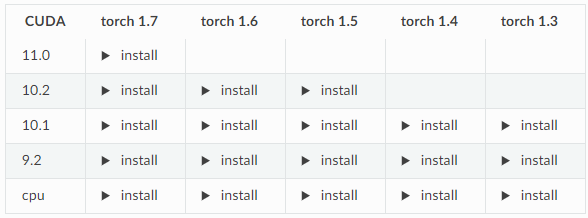
然后第三步重要选一种mmcv的安装方式就行
然后YOLOV3就按下面的弄,然后有一个'`cfg` or `default_args` must contain the key "type"的问题
是因为yolov3_d53_mstrain-608_273e_coco.py文件里的runner = dict(max_epochs=300)这条语句错了,这是一个还未修正的BUG,
应该改为runner = dict(type='EpochBasedRunner', max_epochs=300),也就是加上type='EpochBasedRunner'
在YOLOtest是,需要用checkpoint的绝对路径,用相对路径就会出做错,不知道为什么,明显是个BUG
d=====( ̄▽ ̄*)b 我是小小搬运工!站在各位巨人的肩膀上完成哒~~~
哇,再次撒花花~~~
安装过程
项目地址:https://github.com/open-mmlab/mmdetection
安装细节
环境配置
python 3.7 pytorch 1.6.0 torchvision 0.7.0 cuda 10.2
- conda create -n mmdetection python=3.7
- git clone https://github.com/open-mmlab/mmdetection.git
- conda install pytorch1.6.0 torchvision0.7.0 cudatoolkit=10.2 -c pytorch
https://github.com/open-mmlab/mmcv
根据这个下载对应的mmcv
-
pip install mmcv-full==1.2.2 -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.6.0/index.html
-
pip install -r /home/lhh/workspace/AnacondaProjects/mmdetection/mmdetection/requirements/build.txt
(后面加清华源可能快些,没有尝试) -
运行一段代码,成功!
![在这里插入图片描述]()


使用自己数据集训练
数据集格式

修改路径与配置(/home/lhh/workspace/AnacondaProjects/mmdetection/mmdetection/configs/base)都是在这个文件夹下设置的
- dataset中的.py文件设置路径(用到coco数据集就修改对应的py文件)eg:voc0721.py文件
![在这里插入图片描述]()

- models文件夹修改对应模型的.py文件设置类别数量
- schedules 文件夹修改.py文件设置epoch
- mmdet/datasets/voc.py设置类别名,如果是1类加逗号
- mmdet/core/evaluation/class_names.py设置类别名
以voc数据集,faster_rcnn为例
-
修改schedule_1x.py文件
修改最后一行的训练epoch -
修改配置文件(/home/lhh/workspace/AnacondaProjects/mmdetection/mmdetection/configs/fast_rcnn)中的fast_rcnn_r50_fpn_1x_coco.py设置配置文件的位置,数据类型的位置
![在这里插入图片描述]()
-
创建文件夹work_dir保存训练过程及结果
-
运行(具体需要看train.py文件,需要哪些参数,在tools文件夹下)


比如:python tools/train.py configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py --work-dir work_dir
训练结果: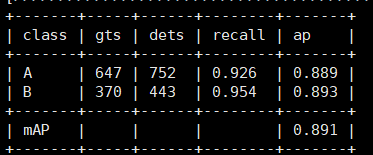
map结果绘制
- mmdetection$ python tools/analyze_logs.py plot_curve ./work_dir/20201228_234809.log.json --keys mAP --legend mAP --out mAP.jpg
之后将训练过程和结果放在统一文件中,上述路径会所更改 - 参考链接:https://www.cnblogs.com/beeblog72/p/12076562.html

- 同理,loss绘制
- python tools/analyze_logs.py plot_curve ./work_dir/20201228_234809.log.json --keys loss --legend loss --out loss.jpg
![在这里插入图片描述]()
- acc
- python tools/analyze_logs.py plot_curve ./work_dir/faster_rcnn_r50_fpn_1x_coco/20201228_234809.log.json --keys acc --legend acc --out acc.jpg


测试
参考链接:https://blog.csdn.net/zxfhahaha/article/details/103754467
注 由于test.py文件只对coco数据集进行eval,所以先用test.py文件生成pkl文件,再用eval_metric.py文件进行计算mAP
- python tools/test.py configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py work_dir/latest.pth --out results.pkl
–out后面可以加路径,不然直接生成再项目根路径下 - python tools/eval_metric.py configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py result.pkl --eval=mAP
使用pkl文件计算每个类的AP
测试结果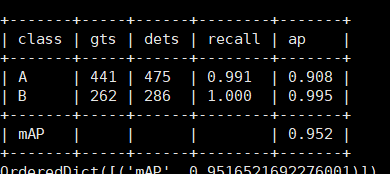
撒花花~~~
以coco数据集,yolov3模型为例
数据集格式:
train2017文件中存放的是图片
annotations存放的是:

先准备三个相同voc格式的数据集,里面分别存放train、test 和val
- 将某一个txt文本中的数字存的是图片的名字,要把这些名字的图片保存到另一个文件夹中
from PIL import Image f3 = open("F:/dataDB/precoco/val/ImageSets/Main/val.txt",'r') #test文件所在路径 for line2 in f3.readlines(): line3=line2[:-1] #读取每行去掉后四位的数 im = Image.open('H:/make_data/AB/Images02/{}.jpg'.format(line3))#打开改路径下的line3记录的的文件名 im.save('F:/dataDB/precoco/val/JPEGImages/{}.jpg'.format(line3)) #把文件夹中指定的文件名称的图片另存到该路径下 f3.close()
- 将某一个txt文本中的数字存的是图片的名字,要把这些名字的图片的xml保存到另一个文件夹中
# -*- coding: UTF-8 -*-
#!/usr/bin/env python
import sys
import re
import numpy as np
import shutil
data = []
for line in open("F:/dataDB/precoco/val/ImageSets/Main/val.txt", "r"): # 设置文件对象并读取每一行文件
data.append(line)
for a in data:
#print(a)
line3=a[:-1] #读取每行去掉后四位的数,本人使用的格式为000001.jpg,即去掉.jpg
#print('line3', line3)
line4 = line3 + '.xml'
print(line4)
oldname = r'H:/make_data/AB/Anotations02/{}'.format(line4)
#print('old', oldname)
newname = r'F:/dataDB/precoco/val/Annotations/{}'.format(line4)
#print('new', newname)
shutil.copyfile(oldname, newname) #将需要的文件从oldname复制到newname
- voc 转coco数据集
import xml.etree.ElementTree as ET
import os
import json
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_set = dict()
image_set = set()
category_item_id = -1
image_id = 20180000000
annotation_id = 0
def addCatItem(name):
global category_item_id
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_set[name] = category_item_id
return category_item_id
def addImgItem(file_name, size):
global image_id
if file_name is None:
raise Exception('Could not find filename tag in xml file.')
if size['width'] is None:
raise Exception('Could not find width tag in xml file.')
if size['height'] is None:
raise Exception('Could not find height tag in xml file.')
image_id += 1
image_item = dict()
image_item['id'] = image_id
image_item['file_name'] = file_name
image_item['width'] = size['width']
image_item['height'] = size['height']
coco['images'].append(image_item)
image_set.add(file_name)
return image_id
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
# bbox[] is x,y,w,h
# left_top
seg.append(bbox[0])
seg.append(bbox[1])
# left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
# right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
# right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
def parseXmlFiles(xml_path):
for f in os.listdir(xml_path):
if not f.endswith('.xml'):
continue
bndbox = dict()
size = dict()
current_image_id = None
current_category_id = None
file_name = None
size['width'] = None
size['height'] = None
size['depth'] = None
xml_file = os.path.join(xml_path, f)
print(xml_file)
tree = ET.parse(xml_file)
root = tree.getroot()
if root.tag != 'annotation':
raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
# elem is <folder>, <filename>, <size>, <object>
for elem in root:
current_parent = elem.tag
current_sub = None
object_name = None
if elem.tag == 'folder':
continue
if elem.tag == 'filename':
file_name = elem.text
if file_name in category_set:
raise Exception('file_name duplicated')
# add img item only after parse <size> tag
elif current_image_id is None and file_name is not None and size['width'] is not None:
if file_name not in image_set:
current_image_id = addImgItem(file_name, size)
print('add image with {} and {}'.format(file_name, size))
else:
raise Exception('duplicated image: {}'.format(file_name))
# subelem is <width>, <height>, <depth>, <name>, <bndbox>
for subelem in elem:
bndbox['xmin'] = None
bndbox['xmax'] = None
bndbox['ymin'] = None
bndbox['ymax'] = None
current_sub = subelem.tag
if current_parent == 'object' and subelem.tag == 'name':
object_name = subelem.text
if object_name not in category_set:
current_category_id = addCatItem(object_name)
else:
current_category_id = category_set[object_name]
elif current_parent == 'size':
if size[subelem.tag] is not None:
raise Exception('xml structure broken at size tag.')
size[subelem.tag] = int(subelem.text)
# option is <xmin>, <ymin>, <xmax>, <ymax>, when subelem is <bndbox>
for option in subelem:
if current_sub == 'bndbox':
if bndbox[option.tag] is not None:
raise Exception('xml structure corrupted at bndbox tag.')
bndbox[option.tag] = int(option.text)
# only after parse the <object> tag
if bndbox['xmin'] is not None:
if object_name is None:
raise Exception('xml structure broken at bndbox tag')
if current_image_id is None:
raise Exception('xml structure broken at bndbox tag')
if current_category_id is None:
raise Exception('xml structure broken at bndbox tag')
bbox = []
# x
bbox.append(bndbox['xmin'])
# y
bbox.append(bndbox['ymin'])
# w
bbox.append(bndbox['xmax'] - bndbox['xmin'])
# h
bbox.append(bndbox['ymax'] - bndbox['ymin'])
print('add annotation with {},{},{},{}'.format(object_name, current_image_id, current_category_id,
bbox))
addAnnoItem(object_name, current_image_id, current_category_id, bbox)
if __name__ == '__main__':
xml_path = 'F:/dataDB/precoco/val/Annotations' # 这是xml文件所在的地址
json_file = 'F:/dataDB/precoco/val/ImageSets/val.json' # 这是你要生成的json文件
parseXmlFiles(xml_path) # 只需要改动这两个参数就行了
json.dump(coco, open(json_file, 'w'))
参考链接:
https://blog.csdn.net/weixin_41765699/article/details/100124689
修改过程
- 修改configs/_ base_/datasets文件下的coco_detection.py文件
- coco.py文件的类别名
- class_names.py文件的类别名


错误: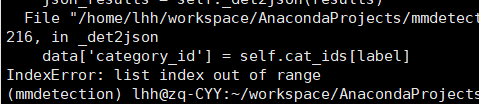
之前使用的yolov3…py文件有问题,没有类别数(num_classes),自己还一直死钻。。。。
换成如下图所示:

- 运行代码:
- python tools/train.py configs/yolo/yolov3_d53_mstrain-608_273e_coco.py --work-dir work_dir/yolov3_d53_320_273e_coco
- 运行成功!

撒花花~~~
测试
- python tools/test.py configs/yolo/yolov3_d53_mstrain-608_273e_coco.py work_dir/yolov3_d53_mstrain-608_273e_coco/latest.pth --out result.pkl --eval bbox


 浙公网安备 33010602011771号
浙公网安备 33010602011771号