
第一次OO总结
第一次作业
设计思路
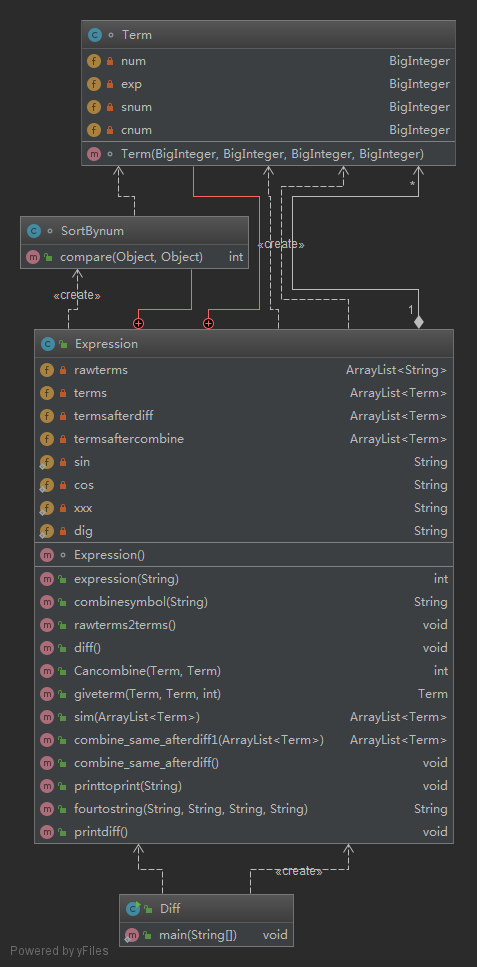
设计两个类,表达式类Expression,项类Term,下说明这些类的成员以及需要完成的功能。
项类Term
项类较为简单,有两个成员,系数和指数,以及一个以系数和指数为输入的构造函数,用以表征一个项。
表达式类Expression
表达式类有四个成员,原始输入字符串切割成项并去掉空格得到的ArrayList<String> rawterms,将rawterms转换为项的标准形式得到的ArrayList<Term> terms,将每一项求导得到的ArrayList<Term> termsafterdiff,合并排序优化后得到的ArrayList<Term> termsaftercombine。相应的,表达式类中方法的设计也就是通过正则将原输入切割成原始项的方法,将原始项转化成标准项Term形式的方法,对项求导的方法,对项合并和优化输出的方法。
优化输出
我的优化输出按这样的顺序进行,首先是合并,将指数相同的合并。然后是去零,将系数为零的项去除。之后是排序,按系数大小排序,将系数大的放在左边输出。最后输出时有判断,指数为1的不输出指数,如果一项都没有,要输出0。
Bug
在第一次作业中没注意到大整数BigInteger的问题导致吃亏后面要吸取教训。正则表达式匹配的时候可以按项匹配而不是整个表达式一起匹配,这样能解决表达式过长贪婪匹配回溯爆栈的问题。
UML类图

度量

第二次作业
设计思路
第二次作业与第一次作业相比,每一项的内容加入了sin,cos。如此以来,在第一次作业的基础上需要改动的内容有:
改写Term类,将其成员从系数和指数扩充到系数,指数,sin的指数,cos的指数。即从二元组扩充到四元组。
改动正则表达式,让其识别由x,sin,cos构成的新项。
将原始的字符串项转化为标准项的过程中要加入遍历累积计算sin,cos的个数从而确定sin的指数,cos的指数。
总体来说第一次作业的架构能支持第二次作业,改动并不算大。
优化
第二次作业的一个重要环节就是输出表达式长度优化。我做的优化原理基于以下三条数学公式:
sin(x)^2 + cos(x)^2 = 1
1 - sin(x)^2 = cos(x)^2
1 - cos(x)^2 = sin(x)^2
这三条公式代表三种条件,即如果两项之间的系数相等或相反,x指数相等,sin和cos的指数满足上面三种公式提出的关系,就能将这两项合并到一起,成为一项。下为判定两项能合并的代码。
public int Cancombine(Term term1, Term term2) {
BigInteger a1 = term1.num;
BigInteger b1 = term1.exp;
BigInteger c1 = term1.snum;
BigInteger d1 = term1.cnum;
BigInteger a2 = term2.num;
BigInteger b2 = term2.exp;
BigInteger c2 = term2.snum;
BigInteger d2 = term2.cnum;
BigInteger two = new BigInteger("2");
if (a1.compareTo(a2) == 0 && b1.compareTo(b2) == 0 &&
(((c1.subtract(c2)).compareTo(two) == 0
&& (d2.subtract(d1)).compareTo(two) == 0) ||
((c2.subtract(c1)).compareTo(two) == 0
&& (d1.subtract(d2)).compareTo(two) == 0))) {
return 1;
}
else if ((a1.add(a2)).equals(BigInteger.ZERO) &&
b1.compareTo(b2) == 0 && ((c1.subtract(c2)).compareTo(two) == 0
|| (c2.subtract(c1)).compareTo(two) == 0) &&
d1.compareTo(d2) == 0) {
return 2;
}
else if ((a1.add(a2)).equals(BigInteger.ZERO) && b1.compareTo(b2) == 0
&& c1.compareTo(c2) == 0 &&
((d1.subtract(d2)).compareTo(two) == 0 ||
(d2.subtract(d1)).compareTo(two) == 0)) {
return 3;
}
else {
return 0;
}
}
有一个需要考虑的情况是当两项合并后会产生一个新的项,这个新的项可能又能与其他项合并,我的做法是循环十次这个合并的过程,每次产生的新项放在下一轮判断,这样大部分新项都能进行处理,毕竟十次合并后还能产生新项的情况并不多。采用这个方式是为了避免随机算法带来的时间复杂度不便于控制的麻烦,下为合并和遍历的代码。
public Term giveterm(Term term1, Term term2, int kind) {
BigInteger two = new BigInteger("2");
BigInteger a = new BigInteger("0");
BigInteger b = new BigInteger("0");
BigInteger c = new BigInteger("0");
BigInteger d = new BigInteger("0");
if (kind == 1) {
a = term1.num;
b = term1.exp;
c = term1.snum.min(term2.snum);
d = term1.cnum.min(term2.cnum
);
}
else if (kind == 2) {
if (term1.snum.compareTo(term2.snum) == -1) {
a = term1.num;
b = term1.exp;
c = term1.snum;
d = term1.cnum.add(two);
}
else {
a = term2.num;
b = term2.exp;
c = term2.snum;
d = term2.cnum.add(two);
}
}
else if (kind == 3) {
if (term1.cnum.compareTo(term2.cnum) == -1) {
a = term1.num;
b = term1.exp;
c = term1.snum.add(two);
d = term1.cnum;
}
else {
a = term2.num;
b = term2.exp;
c = term2.snum.add(two);
d = term2.cnum;
}
}
else {
System.out.println("WRONG FORMAT!");
System.exit(-1);
}
Term term = new Term(a, b, c, d);
return term;
}
public ArrayList<Term> sim(ArrayList<Term> terms) {
ArrayList<Term> before = new ArrayList();
ArrayList<Term> after = new ArrayList();
before = terms;
int time = 0;
while (time <= 10) {
after = new ArrayList();
int[] flag = new int[before.size()];
for (int i = 0; i < before.size(); i++) {
flag[i] = 1;
}
for (int i = 0; i < before.size(); i++) {
if (flag[i] == 1) {
flag[i] = 0;
int find = 0;
for (int j = i + 1; j < before.size(); j++) {
if (flag[j] == 1 &&
Cancombine(before.get(i), before.get(j)) != 0) {
find = 1;
flag[j] = 0;
if (Cancombine(before.get(i), before.get(j)) == 1) {
after.add(giveterm(before.get(i),
before.get(j),1));
}
else if (Cancombine(before.get(i),
before.get(j)) == 2) {
after.add(giveterm(before.get(i),
before.get(j),2));
}
else {
after.add(giveterm(before.get(i),
before.get(j),3));
}
break;
}
}
if (find == 0) {
after.add(before.get(i));
}
}
}
before = after;
time = time + 1;
}
return before;
}
Bug
第二次作业结构较为清晰,未发现较明显bug。
UML类图
度量

可以看到时间复杂度较高的就是求导和优化过程,这也是程序的要点,可考虑使用更好的数据结构来优化。
第三次作业
设计思路
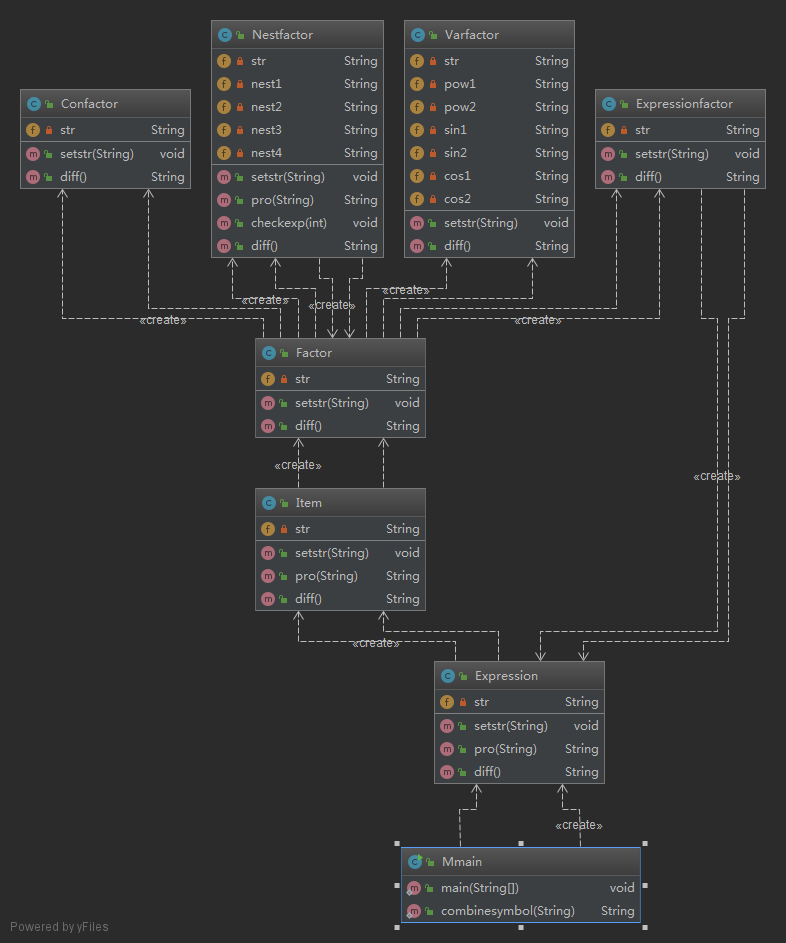
第三次作业支持嵌套,用正则表达式匹配项的方法已经难以进行,故需要重新设计架构,可以采用类似编译器的架构,自顶向下进行语法分析,按照指导书中的定义来设计类。下为我设计的类结构。
表达式类Expression
成员有表达式字符串,方法有设置表达式字符串,预处理表达式,表达式求导方法。
项类Item
成员有项字符串,方法有设置项字符串,预处理项,项求导方法。
因子类Factor
成员有因子字符串,因子求导方法。
常数因子类Confactor
因子类的子类,处理因子是常数的情况(较简单),内用正则表达式检测是否满足常数因子类的格式,并在在求导方法内反馈。
变量因子类Varfactor
因子类的子类,处理因子是幂函数因子和三角函数因子的情况,内用正则表达式检测是否满足幂函数因子和三角函数因子的格式,并在在求导方法内反馈。
嵌套因子类Nestfactor
因子类的子类,处理指导书所规定的嵌套因子情况,内用正则表达式检测是否满足指导书规定的嵌套因子格式,并在求导方法内反馈。
表达式因子类Expressionfactor
因子类的子类,处理指导书规定的左括号+表达式+右括号作为一个因子的情况,其中调用表达式类递归分析,满足自顶向下设计的思想。
UML类图
优化
第三次作业输入输出格式较为复杂,只做了以下几点简单的优化。
输出简化,项中含有常数因子且常数因子为零,删除整个项。输出时,变量因子指数为1则省略^指数部分。检测表达式只有一项时不输出(表达式)而是直接输出表达式。
项内合并,在Item中循环检测其因子是否是同类因子,若是且指数相同则合并为一个因子。
度量
|
Method |
ev(G) |
iv(G) |
v(G) |
|
Confactor.diff() |
2 |
1 |
2 |
|
Confactor.setstr(String) |
1 |
1 |
1 |
|
Expression.diff() |
1 |
3 |
3 |
|
Expression.pro(String) |
1 |
4 |
13 |
|
Expression.setstr(String) |
1 |
1 |
1 |
|
Expressionfactor.diff() |
2 |
2 |
2 |
|
Expressionfactor.setstr(String) |
1 |
1 |
1 |
|
Factor.diff() |
5 |
5 |
5 |
|
Factor.setstr(String) |
1 |
1 |
1 |
|
Item.diff() |
1 |
4 |
7 |
|
Item.pro(String) |
1 |
3 |
7 |
|
Item.setstr(String) |
1 |
1 |
1 |
|
Mmain.combinesymbol(String) |
1 |
1 |
1 |
|
Mmain.main(String[]) |
6 |
9 |
11 |
|
Nestfactor.checkexp(int) |
1 |
2 |
2 |
|
Nestfactor.diff() |
5 |
7 |
7 |
|
Nestfactor.pro(String) |
1 |
6 |
6 |
|
Nestfactor.setstr(String) |
1 |
1 |
1 |
|
Varfactor.diff() |
7 |
7 |
10 |
|
Varfactor.setstr(String) |
1 |
1 |
1 |
可以看到求导方法时间复杂度较高,内聚度较低。因为我的设计思路中各种求导法则也是写在各个类的求导方法中的,例如我的表达式中用加法法则将项的导数合并,在项中用乘法法则将因子的导数合并,在因子中用链式法则处理嵌套,如果将将这些法则独立出来而不是笼统的写在类的求导方法中会更好。
Bug
第三次作业一个难点是将项分出来,因为没法用正则表达式,我最初的想法是先把减号替换成+-,再通过加号来split,考虑到了指数中的加号,括号中的加号要跳过,但没想到因子中常数因子带的加号导致出错,后改正,启示我们当选择简单的方式来直接处理字符串时一点要三思,要么用正则这种高级的方法处理,要么想清楚所有情况自己分类处理。
设计模式总结
在这三次作业中,我开始是一个刚刚接触面向对象的小白。在第一二次作业中,掌握了正则的方法就能对付并没有太多的思考设计模式,但到了第三次作业,我发现我第一二次作业的架构已经完全行不通了,这时我才开始思考设计模式,让自己的程序更为面向对象。以下是我回顾自己前几次的不足之处总结的经验:
分解与封装,在第一二次作业中,因为任务相对简单,我想的就是把输出弄对,把整个任务都写在一个类中,方法的拿捏过于草率,想到什么方法就在里面加,最后代码的维护与扩充很困难。所以,我们在写面向对象程序时,即使是简单的一个操作,只要操作独立,纯粹就应当独立成一个方法,善于把任务分解成简单的成分,即使这个任务并不复杂。清晰的结果并不会多花多少时间,但会让写代码的人写的有条理,让读代码的人便于理解。
善用继承,我在第三次作业中才体会到继承的好处,有了继承,各种因子都可以继承自总的因子,这样的结果与指导书紧密扣合,而不是自己绞尽脑汁做的等价转换,这对于保证程序与需求的贴合性大有帮助,并且求导类的重写让代码有条有理。
用接口和工厂类来优化设计,在我原来的因子类中需要多次new各种因子来进行求导,模式判断等操作,但采用工厂类的编程模式的话,就能将创建对象的工作转移到了工厂类,让程序更为面向对象,这一点我还用的不是很好,需要多多学习。
