BUAAOO Unit3:JML总结
1. 总结自己实现规格所采取的设计策略
-
填写规格的顺序
-
先完成异常类
因为异常类相对来说实现比较简单所以选择先完成异常类
-
再写非
Network的普通类,最后写Network类总的来说,
Network类是实现最复杂的类,它里面也基本上使用了非Network的其他类,所以先写非Network类,有助于对代码的理解,也能在写Network时更得心应手。
-
-
选择合适的容器
详细见第3点
-
选择性能较好的算法
-
在
isCircle -
在
queryblockSum中计算连通分量的个数时,我使用了数据结构课中使用过的dfs算法,边遍历边删除结点 -
在
sim中我采用dijistra算法计算最短路径。
-
2. 结合课程内容,整理基于JML规格来设计测试的方法和策略
-
形式化验证
对照JML规格进行形式化验证。我是先根据JML规格把规格“翻译”成自然语言,然后检查自己实现的代码是不是这样。因为有的时候写着写着就可能“多干一步”、或者“少干一步”,出现难以发现的bug,所以我认为对照JML进行验证算是不错的查找bug方法。
-
Junit测试
-
对于
Network的函数,单独测试其功能正确性。因为我不太会写自动评测机,所以就只能手动构造数据了,基本上把能想到的一些情况都测了,但还有一个注意的地方就是,我有的时候是直接跑而不是debug模式,所以有些时候虽然结果是正确的,但可能多删了一些东西、或者少删了一些东西,在后面测试的时候才发现这个问题。
3. 总结分析容器选择和使用的经验
容器的选择
在这个单元里,我主要使用的容器是HashMap,在要求是List的规格中使用了LinkedList
我选择用HashMap来存储MyNetwork中的people、groups、messages等,选择HashMap的原因是因为这样便可将“取/存”操作变为复杂度为O(1),提高性能。
对于像queryReceivedMessage这种指令,其JML规格要求使用List容器来存放每个人所接收到的Message,因为有很多的“添加”操作,所以我采用了LinkedList而不是ArrayList这种容器。
总而言之,我是能HashMap就HashMap,不能的话再根据情况选择。
HashMap的使用
遍历一个HashMap
HashMap<Integer, String> oneMap = new HashMap<>();
Iterator iter = oneMap.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
//取出当前的key
int key = (Integer) entry.getKey();
//取出当前的value
String value = (String) entry.getValue();
}
边遍历边增删
(与上面给的遍历过程类似,在遍历中使用remove()方法删除)
HashMap<Integer, String> oneMap = new HashMap<>();
Iterator iter = oneMap.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
iter.remove();
}
4. 本单元容易出现的性能问题
-
对
queryBlockSum我最初是没有优化的,只是采用之前数据结构课使用过的BFS算法,结果后来在第二次作业中因为qbs超时了,我才发现其实对于所有的查询操作,是不改变Network中blockSum的值,只有
addPerson和addRelation操作才会改变blockSum的值,所以我当每一次调用addPerson和addRelation时就会将use置0。当调用qbs时,如果use为0,调用BFS计算新的blockSum值,并将其存入lastBlockSum中,并将use置1;如果use为1,则直接返回lastBlockSum即可。 -
对
queryGroupValueSum、queryGroupAgeMean类指令可以在
MyGroup中增加两个变量valueSum和ageMean,当每次对group进行addPerson和delPerson时对valueSum和ageMean进行维护。需要注意的是,当Network进行addRelation操作时,需要遍历groups,当添加关系的两个人都在group中时需要增加该group的ValueSum。 -
对
SendIndirectMessage我采用了
dijistra算法,优化的话,可以使用堆排序的dijistra算法(虽然我没有这么实现),我将dijistra包装成一个类,因为一次travel可以计算目标顶点到其他所有顶点的最短路径,所有我在Dijistra类中使用HashMapminWeight把每个节点到其他节点的最短路径长度都保存下来,跟queryBlockSum类似,当每次addRelation后就将useWeight置0,当调用sim时,如果useWeight为0,则清空minweight里保存的最短路径长度,调用dijistra.travel计算新的最短路径值,并将结果存入minWeight中,将useWeight置1;如果useWeight为1,那么看useWeight中是否计算过iddao其他节点的最短路径,如果计算过则直接从useWeight中取出并返回即可,如果没有计算过,则调用travel计算。
5. 作业架构设计,特别是图模型构建与维护策略
UML图
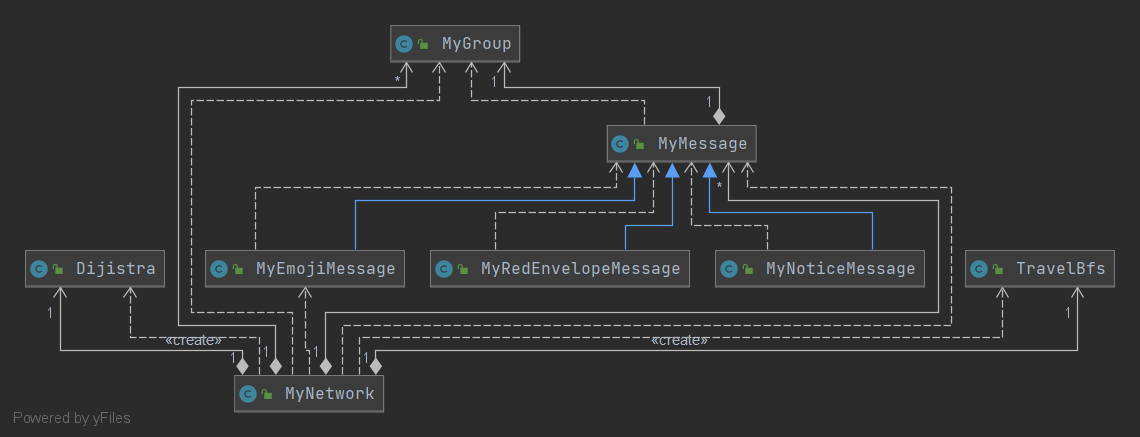
除了官方要实现的类我创建了Dijistra类和TravelBfs,一个是计算最短路径,一个用来计算两个人是否连通。
对于TravelBfs
private HashMap<Integer, MyPerson> people = new HashMap<>();//id, Person
private HashMap<Integer, LinkedList<MyPerson>> linkPeople = new HashMap<>();
private HashMap<Integer, Integer> visit = new HashMap<>();
其中,people、linkPeople与Network中的定义相同,在每次调用时需要将当前Network中的值赋给TravelBfs。visit是标记此节点是否被访问过。
对于Dijistra
private HashMap<Integer, MyPerson> people = new HashMap<>();//id, Person
private HashMap<Integer, LinkedList<MyPerson>> linkPeople = new HashMap<>();
private HashMap<Integer, Integer> wfound = new HashMap<>();
private HashMap<Integer,
HashMap<Integer, Integer>> minWeight = new HashMap<>();//<id, <id, weight>>
其中,people、linkPeople与Network中的定义相同,在每次调用时需要将当前Network中的值赋给Dijistra。minWeight是用来保存计算过的最小路径权重,格式为<id1, <id2, weight>>保存了每一个结点到其他所有结点的最短权重。
我会根据是否有“添加关系”,“所要找的人是否已经算过其最短路径”来判断是否重新计算最短路径还是直接返回之前计算过的最短路径。需要注意的是在“添加关系”后,之前计算过的最短路径可能都不再是当前情况下的“最短路径”,所以此时就要将minWeight清零。

