
web框架
Web服务器与Web框架关系详解及动态资源处理实现方式
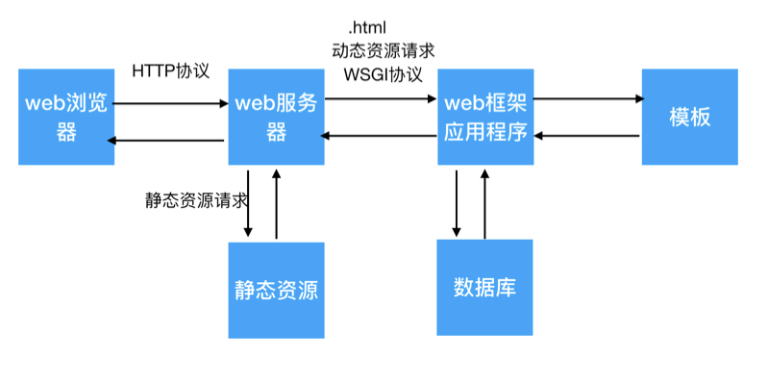
一、Web服务器与Web框架的关系
1. Web服务器是什么?
Web服务器是接收HTTP请求并返回响应内容的程序。它可以:
- 接收用户的HTTP请求(GET、POST等)
- 根据请求路径判断是静态资源还是动态资源
- 对于静态资源:直接从本地文件系统读取并返回
- 对于动态资源:将请求转发给Web框架处理,并等待结果后再返回给浏览器
2. Web框架是什么?
Web框架是一个专门用来处理动态资源请求的应用程序。它通常具备以下功能:
- 处理用户输入参数(如查询条件、表单数据等)
- 调用数据库或其它业务逻辑
- 生成HTML页面或其他格式的数据(JSON、XML等)
3. 它们之间的协作流程
浏览器 → HTTP请求 → Web服务器 → 判断是否为动态资源
↓ 是
Web框架 → 处理请求 → 返回结果
↓
Web服务器 → 构造响应 → 浏览器
二、静态资源 vs 动态资源
| 类型 | 特点 | 示例 |
|---|---|---|
| 静态资源 | 内容固定,不会根据用户请求变化 | CSS、JS、图片、视频等 |
| 动态资源 | 内容根据用户请求参数、时间、登录状态等因素动态生成 | HTML、商品搜索结果页、用户中心页等 |
三、WSGI 协议介绍
WSGI(Web Server Gateway Interface)是Python中用于连接Web服务器和Web框架的标准接口。
WSGI的主要作用:
- 规定Web服务器如何把请求传递给Web框架
- 规定Web框架如何将处理结果返回给Web服务器
Web服务器调用web框架的简单演示
def handle_tcp(client_socket):
"""和浏览器进行交互的小弟socket"""
recv_data_raw = client_socket.recv(1000000)
if not (len(recv_data_raw)):
client_socket.close()
print("客户端连接已结束!!")
return
recv_data = recv_data_raw.decode()
data_list = recv_data.split(" ")
request_path = data_list[1]
if request_path == "/":
request_path = "/index.html"
# 请求的是动态资源
if request_path.endswith(".html"):
response_line = "HTTP/1.1 200 OK\r\n"
response_header = "server:py1.0\r\n"
### 这里调用web框架
response_body = dynamic.my_web_framework.application(request_path)
### -------------------
recv_data = response_line + response_header + "\r\n" + response_body
client_socket.send(recv_data.encode())
client_socket.close()
WSGI接口函数的基本形式:
## 这是 dynamic.my_web_framework.py 文件
def application(environ, start_response):
status = '200 OK'
headers = [('Content-type', 'text/html')]
start_response(status, headers)
return [b"<h1>Hello World</h1>"]
environ:一个字典,包含了客户端请求的所有信息
start_response:回调函数,用于设置响应头
返回值:响应体的内容(必须是可迭代对象)
四、动态资源处理的三种实现方式(WSGI接口函数的几种简单实现)
下面我们将通过完整的代码示例,展示三种不同的动态资源处理方式:
方式一:普通条件判断法(最基础)
✅ 实现原理:
在 application() 函数中使用多个 if-elif 条件判断请求路径,并返回对应的内容。
💻 示例代码:
def application(request_path):
if request_path == "/index.html":
return "这是首页"
elif request_path == "/center.html":
return "这是个人中心页面"
else:
return "404 页面不存在"
⚠️ 注意事项:
- 请求路径需要手动维护
- 不适合页面较多的情况
- 可扩展性差
✅ 优点:
- 简单直观,适合初学者理解
- 不依赖任何高级语法
❌ 缺点:
- 代码臃肿
- 新增页面时需修改原有函数逻辑
方式二:函数列表控制法(面向切面编程思想,即一个函数控制一个页面,这样代码结果简单清晰,易于定位错误和维护)
✅ 实现原理:
定义一个字典 func_list,将URL路径映射到对应的处理函数。通过查找字典来调用相应的函数。
💻 示例代码:
func_list = {}
def index():
return "这是首页"
def center():
return "这是个人中心页面"
# 手动注册路由
func_list["/index.html"] = index
func_list["/center.html"] = center
def application(request_path):
try:
func = func_list[request_path]
return func()
except KeyError:
return "404 页面不存在"
⚠️ 注意事项:
- 每次新增页面都需要手动添加到
func_list字典中 - 更加模块化,便于组织代码结构
✅ 优点:
- 结构更清晰
- 易于维护和测试
❌ 缺点:
- 手动注册繁琐
- 仍不够灵活
方式三:路由装饰器法(自动化注册)
✅ 实现原理:
利用 Python 的装饰器特性,自动将 URL 路径与处理函数绑定,无需手动注册。
💻 示例代码:
route_dict = {}
def route(path):
"""装饰器工厂函数"""
def decorator(func):
route_dict[path] = func # 自动注册路由
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapper
return decorator
@route("/index.html")
def index():
return "这是首页"
@route("/center.html")
def center():
return "这是个人中心页面"
def application(request_path):
try:
func = route_dict[request_path]
return func()
except KeyError:
return "404 页面不存在"
⚠️ 注意事项:
- 装饰器的本质是函数包装器
- 使用装饰器可以让路由注册过程自动化
- 增加新页面只需添加
@route("path")装饰器即可
✅ 优点:
- 高度解耦
- 易于扩展
- 符合现代Web开发理念(如Flask、Django风格)
❌ 缺点:
- 初学者可能对装饰器机制不熟悉
- 代码结构略复杂
五、综合对比表格
| 方法名称 | 是否自动注册 | 是否易扩展 | 是否适合大型项目 | 是否推荐使用 |
|---|---|---|---|---|
| 普通条件判断法 | ❌ | ❌ | ❌ | ❌ |
| 函数列表控制法 | ❌ | ✅ | ✅ | ✅ |
| 路由装饰器法 | ✅ | ✅✅ | ✅✅ | ✅✅ |
六、实际应用建议
| 场景 | 推荐方式 | 说明 |
|---|---|---|
| 小型项目 / 教学练习 | 普通条件判断法 | 快速上手,适合教学演示 |
| 中小型项目 / 学习进阶 | 函数列表控制法 | 提高代码可维护性,适合逐步深入学习 |
| 大型项目 / 工业级开发 | 路由装饰器法 | 自动化路由注册,结构清晰,符合主流Web框架设计思想(如Flask) |
七、总结
- Web服务器负责接收请求、区分静态/动态资源;
- Web框架专注于动态资源的处理;
- WSGI协议作为两者之间的桥梁,规范了通信方式;
- 在实现动态资源处理时,有三种常见方式:
- 普通条件判断法(简单但不灵活)
- 函数列表控制法(结构清晰、适合中型项目)
- 路由装饰器法(高度解耦、适合大型项目)
- 推荐使用路由装饰器法,因为它体现了现代Web框架的设计思想,也更容易扩展和维护。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号