分组查找最新的一条记录 ROW_NUMBER() over(partition by orgkey order by ocrdate desc,cls desc)
ROW_NUMBER() over(partition by orgkey order by ocrdate desc,cls desc)
案例:
公司的某份报表需要新增一个最新供应商字段,由于同一个产品可能存在不同供应商的情况,所以采用了先全量导入,后进行排序筛选,在操作过程中发现,有极少数商品在同一时间点出现了两个不同的供应商,但订单编码存在着先后顺序(仅是末两位01/02这样的区别,不含有其他日期信息)
因此,在处理的时候,思路是,进行排序的时候我们要在每一个商品里按照下单的时间点及下单的编号同时进行排序,以防止同一时间点出现了两个供应商,造成数据错误
--查找所有供应商
--单号,商品gid,供应商gid,订单日期,供应商编码,供应商名称
INSERT INto HDTMP_SALDRPT1(cls,orgkey,pdkey,ocrdate,vdrkey,gname)
select ad.num,ad.gdgid,ad.vdrgid,ad.FILDATE,vv.code,vv.name from (
--直配
select aaa.num,aaa.gdgid,aaa.vdrgid,aaa2.time FILDATE
from diralcdtl aaa
inner join diralc aaa1 on aaa.num=aaa1.num and aaa.cls=aaa1.cls
inner join diralclog aaa2 on aaa.num=aaa2.num and aaa.cls=aaa2.cls
where aaa2.stat=1000 and aaa.cls='直配出' and aaa.qty<>0
union all
--自营进货
select bbb.num,bbb.gdgid,bbb.vdrgid,bbb2.time
from stkindtl bbb
inner join stkin bbb1 on bbb.num=bbb1.num and bbb.cls=bbb1.cls
inner join stkinlog bbb2 on bbb.num=bbb2.num and bbb.cls=bbb2.cls
where bbb2.stat=1000 and bbb.qty<>0
union all
--抵扣
select dis.num,dis.gdgid,dis.vdrgid,dis1.FILDATE
from dischgdtl dis
inner join DisChg dis1 on dis.num=dis1.num
where dis.qty<>0
) ad left join vendor vv on vv.gid=ad.vdrgid;
commit;
--方案一
--筛选最新供应商
INSERT INto HDTMP_SALDRPT2(orgkey,pdkey,cls,vdrkey,gname)
select distinct cc.orgkey,cc.pdkey,cc.cls,cc.vdrkey,cc.gname from HDTMP_SALDRPT1 cc
where not exists(
select 1 from HDTMP_SALDRPT1 ee where ee.orgkey=cc.orgkey and ee.ocrdate>cc.ocrdate);
--再次筛选 防止出现同时间不同供应商数据
insert into h4rtmp_collate(collateno,fieldname,fieldlabel)
select distinct dd.orgkey gid,dd.vdrkey vdcode,dd.gname vdname from HDTMP_SALDRPT2 dd
where not exists(
select 1 from HDTMP_SALDRPT2 xx where xx.orgkey=dd.orgkey and xx.cls>dd.cls);
commit;
--方案二
--优化效率
--按最近日期、单号筛选
insert into h4rtmp_collate(collateno,fieldname,fieldlabel)
select orgkey gid,vdrkey vdcode,gname vdname from (
select cls,orgkey,pdkey,ocrdate,vdrkey,gname,ROW_NUMBER() over(partition by orgkey order by ocrdate desc,cls desc) rn
from HDTMP_SALDRPT1)
where rn=1
;
commit;
备注解释:
此案例中,单纯以时间进行的话,可能会存在刚好同一个时间点操作的两个单,虽然这个情况会比较小,但是也是可能出现的,所以要同时对单号和时间进行排序,方案一/方案二 都是需要按时间和单号进行排序,找出唯一的值,在本案例中,方案2比方案1效率仅提高1-2秒,但从,方案一中可以看出,他的一个脚本只支持一个条件排序筛选,因此需要重复两次脚本代码进行,脚本较为复杂,后期维护也比较麻烦,方案二中,使用了函数ROW_NUMBER() 和 OVER(PARTITION BY... ORDER BY...) 组合
函数解释
ROWNUM为劣势排序,他不会受后面的order by影响
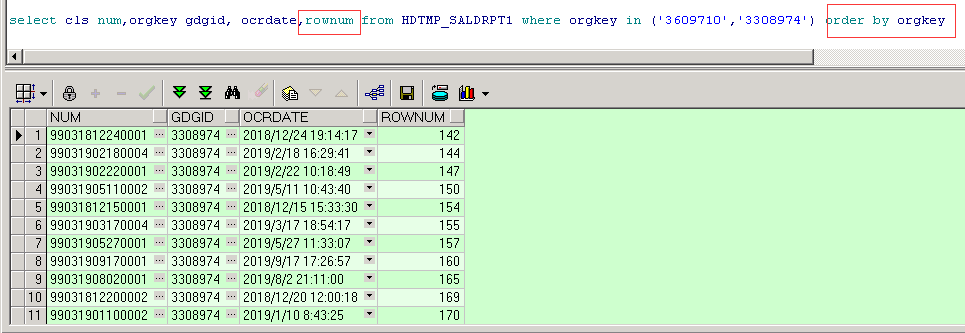
ROWNUM和ROW_NUMBER() 的区别
ROWNUM是先编号后排序,不会受后面order by的影响
ROW_NUMBER()是搭配排序从句使用的,受排序从句影响,先排序后编号
组合使用
ROW_NUMBER() 和 over(order by …) 结合起来使用,也是用作排序,但此时,由于多了over(order by…)的加持,所以他会先根据order by后面的字段进行排序,之后再进行


两个搜索结果显示,数据虽然按照目标列进行排列了,但是他只限于在只有一个商品的时候,也就是GDGID的时候,当出现了需要在每一个商品里进行各自的排序,这还是满足不了我们要的需求
ROW_NUMBER() 和 over(partition by … order by …) 组合
Partition by 中文理解就是分组的意思,在这里 over(partition by… order by…)就是先按照partition by 后面的列进行分组,然后在分组内进行排序
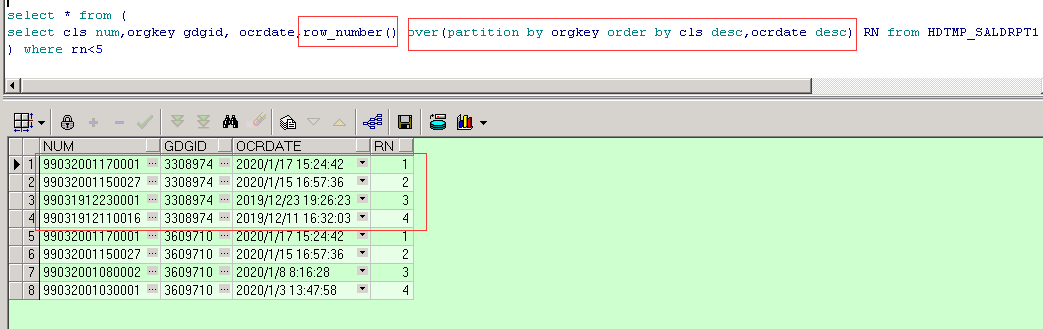
这时就已经满足我们想要的要求,但留意到,我们在展示的时候,外套了一层并筛选了小于5的进行,这是因为开窗函数没有办法与having搭配进行使用
TBC......今天先学习到这里,如果之后有update了,再更新完善,有说错的地方欢迎大家在评论区指正,也期待在评论区看到更有博友分享的不同思路和解决方案


 浙公网安备 33010602011771号
浙公网安备 33010602011771号