.NET把Windows开发者引入到正则表达式的世界
正则表达式(regular expression,即Regex)是说明大块文本的一种模式(pattern)。正则表达式引擎把这种模式运用到源文件文本中去。最初的源文本是不相关的——它可以是文本文件、网页的HTML源代码、甚至是数据库表格中的一个栏。
只需要使用几种记号(token),你就可以描述出复杂的模式,而且你还可以对这些模式作些很酷的事,如算术运算(也就是说,计算该模式出现的次数)。
正则表达式应用程序
用到正则表达式的应用程序太多了,以至于不能在本文全部列出,但我们还是列出了一部分让你大概看看正则表达式有些什么作用:
- 验证用户数据的有效性,用户数据(如电话号码、信用卡号码、电子邮件地址等等)可以来自网站或者本地应用程序。
- 在文本文件中搜索诸如“莎士比亚全集”(字数不得少于10个字符或者任意指定的字符数)这样的字句,或者搜索“love”以及“horse”(忽略大小写)并报告它们出现的位置和次数。
- 把重要的数据,如各个网站给出的足球比赛日程表,保存到我自己的数据库中去。
- 对网站搜索引擎来说,为正则表达式保持一个智能的前端并写出模式;然后所有其它工作交由.NET处理。
模式识别
模式是一个字符序列的代数表达式,它满足递加性(也就是说模式可以包含一系列其它模式)和递归性(也就是说模式可以包含子模式)。表A列出了正则表达式中常见的标记。
表A
|
标记 |
含义 |
|
. |
匹配任何单个字符(也就是说,“w.e”匹配“Brawley”,这里“.”匹配单字符“l”)。 |
|
\b |
用来指明不用考虑前后字符的单词(也就是说,定界符是空格、制表符或者逗号都不要紧)。 |
|
\w |
匹配任何单词字符(即A~Z、a~z,以及0~9)。 |
|
\W |
匹配任何非单词字符(即除A~Z、a~z,以及0~9之外的字符。 |
|
\d |
匹配任何数字。 |
|
\D |
匹配任何非数字。 |
|
\. |
表示你实际上搜索点号的换码序列(因为点号有其它意义,所以需要用换码的方式表示它)。 |
|
\s |
表示任何白空格(可以是制表符也可以是空格,我们并不关心它具体是什么)。 |
|
\S |
表示任何非白空格。 |
|
^ |
字符串或者行的起始标记。 |
|
$ |
字符串或者行的结束标记。 |
|
* |
用于指示零或者大于零发生了。 |
|
? |
指示任意字符(也就是说,零或者一发生了。 |
|
+ |
前一标记出现一次或者多次(也就是说“\w+”表示匹配任何字)。 |
|
[] |
表示一个范围,如[A-Z]表明匹配任何大写字母。 |
|
| |
OR(或)运算符,用来指示感兴趣的匹配的集合 |
|
() |
与“|”相同。 |
例如,模式“M[aeiouy]”表示以字符“M”开头,后面跟着任何元音字母(a、e、i、o、u或者y)的字符组合,而模式“M[^aeiouy]”表示字符“M”后没有跟着元音字母的字符组合。
正则表达式选项
你可以利用各种选项来更改正则表达式的行为。有一个选项用来指定对应正则表达式的工作方式——单行还是多行。其默认值为单行工作方式,一般你在处理文本文件时需要这种方式。多行模式可以让你把文本中的所有行当作单一对象来读取。从数据库中导出文本文件(在特定行中用逗号、制表符或者引号来表明字段)的场合下用多行模式是适宜的。表B列出了.NET中常常用到的若干选项。
表B
|
选项 |
描述 |
|
None |
表明没有设定选项。 |
|
IgnoreCase |
表明匹配时大小写不敏感。 |
|
Multiline |
指定多行方式 |
|
ExplicitCapture |
指定有效捕获是明确命名的或者按(? |
|
Compiled |
指明该正则表达式将会编译到汇编(assembly)中去 |
|
Singleline |
指定单行方式 |
|
IgnorePatternWhitespace |
指定该模式去处了所有的保有(unescaped)白空格,并且使得注释以数字符(#)开头。 |
|
RightToLeft |
指明搜索是自右向左,而不是自左向右的 |
|
ECMAScript |
指定该正则表达式使能ECMAScript兼容模式行为 |
正则表达式中的常用选项
集合和字符集
集合和字符集用诸如[A-Za-z]这样的语法表示。这个模式使用英语国家的所有字母字符。你可以认为集合为类似字符的总和。例如,你可以这么写:
[A-Za-z]
该模式匹配所有的大写和小写字母字符,而丢弃数字、不可见(non-printable)字符等等。
Or Else
“|”和“()”可以让你构造强大而又简洁的模式,它们与If/ElseIf/Else构造的功能相同,但是少用了不少字符。
组
你可以定义组并给它们命名或者编号。当你处理SQL Server、Access或者Excel之类应用程序所创建的文本文件时,这个功能就显得非常有用。假设你的源文件包含Title、GivenName、Surname和EmailAddress数据栏(用逗号隔开)。GivenName和Surname栏会包含多个单词,如“Don Diego”、“de la Vega”等等。
.NET中的正则表达式
为了在.NET中使用正则表达式,在你的源代码中添加下面一行代码:
Imports System.Text.RegularExpressions
然后你就可以层次使用正则表达式。考虑到正则表达式的强大作用,该工作的工作量几乎为零。典型的代码片断最多也就是几行。
建立测试工具
接下来,我将建立一个简单的网页,它可以让你在大块文本上来测试任何正则表达式。我用的是VB.NET,但是只要对这些代码做上一两点的修改,也可以使用C#。
创建一个新的名为WebRegex的网络应用程序。在这个页面上放置三个文本框。第一个文本框命名为txtPattern、第二个命名为txtSource、第三个为txtResults。为每个文本框添加一个标签。在页面上再添加一个按钮控件,命名为btnDoIt,并把它上面的文字改为“Do it”。调整后两个文本框到合适的大小,并把它们的TextMode属性改为Multiline。把txtResults文本框上的标签的名字改为lblMatchCount。最后,添加一个检验栏控件,把它的标签改为MultiLine方式,并把它命名为chkMultiLine。现在,你的页面应该如图A所示。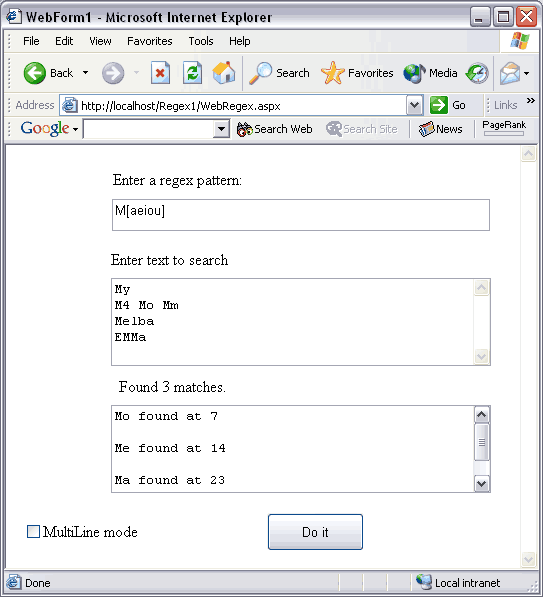
你只需要花上几分钟时间就可以建立好一个正则表达式测试工具。双击按钮控件进入代码窗口,添加下面的代码:
Dim rx As Regex
Try
If chkMultiLine().Checked Then
rx = New Regex(txtPattern().Text, RegexOptions.Multiline)
Else
rx = New Regex(txtPattern().Text)
End If
Catch ex As Exception
Response.Write(ex.Message)
Exit Sub
End Try
Dim mc As MatchCollection = rx.Matches(txtSource().Text)
lblMatchCount.Text = "Found " & mc.Count.ToString & " matches."
Dim m As Match
For Each m In mc
txtResults().Text += m.Value '& " found at " & m.Index & Chr(10) & Chr(13)
Next
为了免去麻烦,我就不再写入读取文本文件的代码(由于你需要做的全部事情就是在任何一个编辑器中打开文本文件并把它的内容拷贝粘贴到txtSource文本框控件中去)。你可能想用你刚刚打开的HTML文件来做这个测试。假设你想找出这个HTML文件中所有的HTML标记。下面的模式将会为你完成这项工作:
<[^>]*>
再举个例子,一个真正的技巧——用来匹配有效VISA卡号码的模式:
^(?:(?:[4])(?:\\d{12}|\\d{15}))$
下面是一个用来匹配年/月/日(年月日均是两位数)格式的模式:
^((0?[1-9])|(1[0-2]))/((0?[1-9])|([12][0-9])|(3[01]))/((19|20)\d\d)
替换文本
即使查找文本的功能在所有的正则表达式中都可以得以实现,它还是非常非常的强有力,而且它还可以做智能替换。从本质上来说,它包括了用某个模式捕获感兴趣的文本,然后调用另一个模式的“Replace”方法。例如,假设你想删除指定HTML文件中的所有HTML标记,你的代码如下:
Dim rx as Regex
Dim strPattern as String = "<[^>]*>"
Dim strIn as String 'importing the text is not shown
Dim strOut as String
rx = New Regex( strPattern )
strOut = rx.Replace( strIn, "" )
上面的代码找到所有的HTML标记并用空白来替换它们。注意,由于该文件有可能包含源代码,所以它不会找到单独出现的< or >。
这种查找/替换模式可能会花上你一段时间去领会。幸好,Visual Studio .NET提供了一个模式向导,该向导包括了一些常用模式,所以你的部分工作就缩减到做几次点击以及在下拉列表中做出若干次选择,仅此而已。
如果你刚刚接触正则表达式,我建议你在熟练使用查找模式之前,暂缓使用替换模式。
一个好工具
在本文中,我只是尝试引起你对构造正则表达式的兴趣并去除你对它的神秘感。我见识过正则表达式的威力,你不妨也试试。如果你现在正在辛辛苦苦的满足客户提出的要求,那么机会可能就来了。用正则表达式花上较少的时间来构建强有力的解决方案吧。
文章来自: http://www.zdnet.com.cn/developer/code/story/0,2000081534,39139567,00.htm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号