
Transformer 模型(能理解“句子顺序”和“上下文”的神经网络架构)
- 1. 起源与发展
- 2. Transformer 模型分类
- 3. 核心概念
- 3.1 自监督学习
- 3.2 迁移学习与微调
- 3.3 注意力层(Attention Layer)
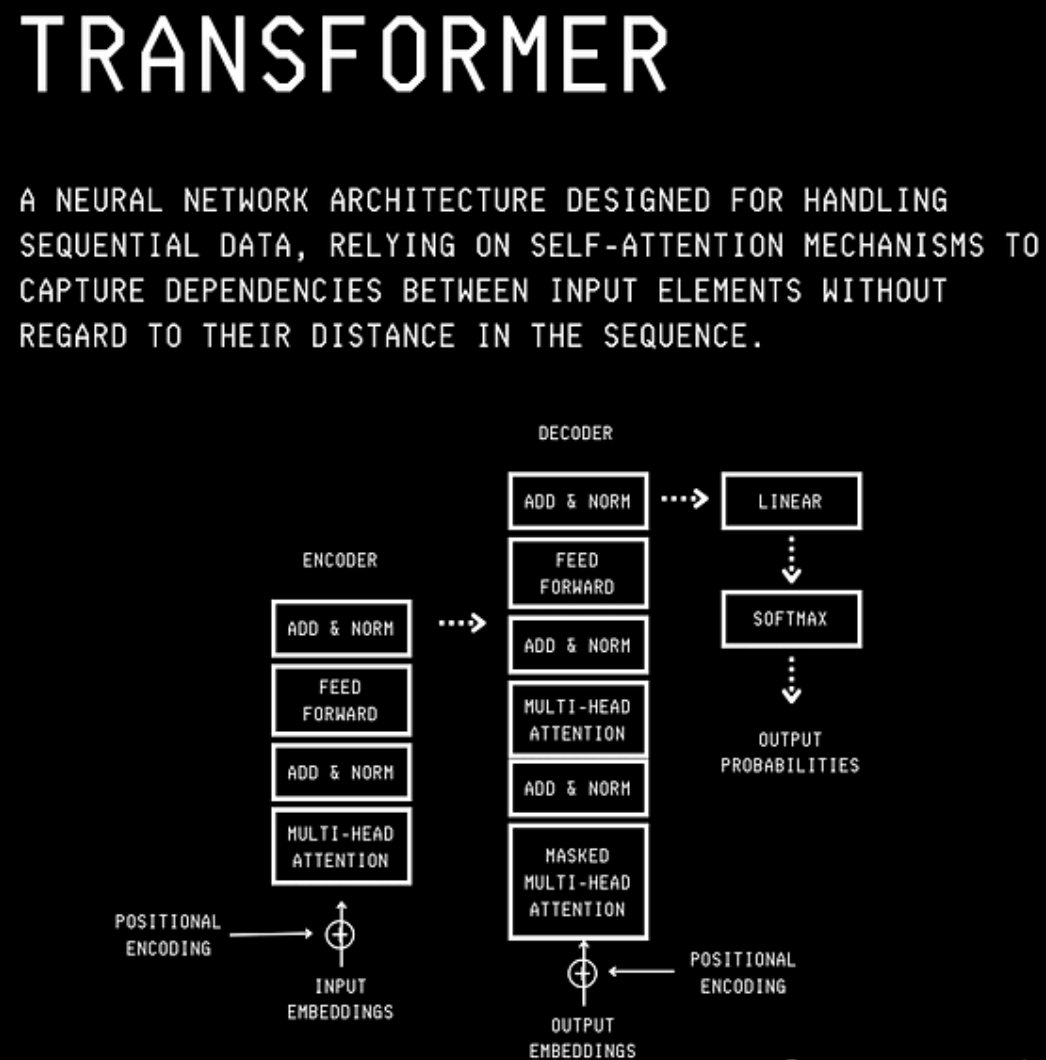
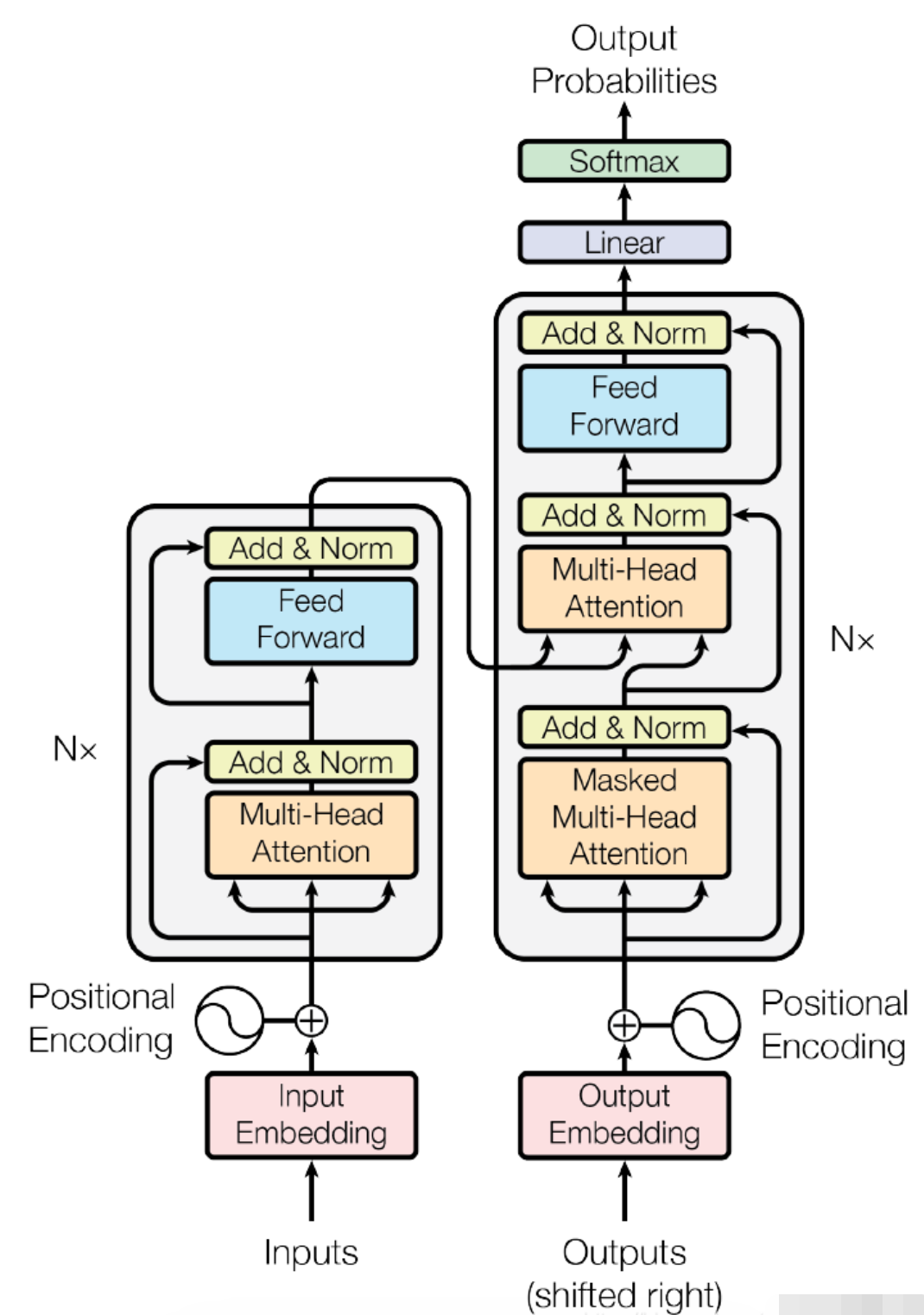
- 4. 模型结构
- 4.1 Encoder
- 4.2 Decoder
- 4.3 Encoder-Decoder
- 5.Transformer Encoder
- 5.1 输入与嵌入
- 5.2 Encoder 层结构(每一层相同)
- 5.3 Encoder 层总结
- 5.4 Encoder 流程图(简化)
Transformer 是自 2017 年提出以来,取代 RNN 和 CNN 的主流 NLP 模型架构,广泛应用于文本理解与生成任务。
1. 起源与发展
- 2017 年:Google 提出《Attention Is All You Need》,用于序列建模和机器翻译任务。
- ULMFiT:Fast AI 提出基于 LSTM 的迁移学习方法,用少量标注数据即可高效训练文本分类模型。
- 标志性模型:
- GPT (Generative Pretrained Transformer)
- BERT (Bidirectional Encoder Representations from Transformers)
- 优势:
- Transformer + 自监督学习 → 不依赖人工标注数据
- 可迁移到各种 NLP 下游任务
- 支持并行计算,加快训练速度
2. Transformer 模型分类
- 三种模型框架
| 类别 | 架构 | 代表模型 | 适用任务 |
|---|---|---|---|
| 纯 Encoder | Auto-Encoding | BERT、RoBERTa、ALBERT、ELECTRA | 文本理解、分类、NER、抽取式问答 |
| 纯 Decoder | Auto-Regressive | GPT 系列、CTRL、GPT-Neo | 文本生成、续写、代码生成 |
| Encoder-Decoder | Seq2Seq | T5、BART、M2M-100、BigBird | 翻译、摘要、生成式问答 |
3. 核心概念
3.1 自监督学习
- MLM: Masked Language Modeling,遮盖语言建模(Word2Vec 模型提出的 CBOW),基于上下文(周围的词语)来预测句子中被遮盖掉的词语 (masked word),被 BERT 首次广泛使用
- CLM: Causal Language Modeling, 因果语言建模(统计语言模型),根据
前文预测下一个词,自回归语言建模,用于 GPT
3.2 迁移学习与微调
-
预训练模型:从头开始训练,需要海量的训练数据,而且时间和经济成本都非常高。
-
迁移学习:在预训练模型基础 上使用
少量标注数据微调下游任务(将别人预训练好的模型权重通过迁移学习应用到自己的模型中,即使用自己的任务语料对模型进行“二次训练”,通过微调参数使模型适用于新任务。) -
避免从头训练,节省时间、数据和计算成本
3.3 注意力层(Attention Layer)
-
核心思想
模型像“专注力”,自动判断哪些词最重要并重点关注。 -
基本概念
- Query - Q:想问的内容
- Key - K:每个词的标签或特征
- Value - V:每个词的实际信息
- Attention:权重矩阵,相关性强的该关注的信息权重大;计算每个 Query 对所有 Key 的相关性,加权求 Value,得到最重要的信息
简单理解:“我想知道当前词最应该关注哪些词,然后把它们的信息加权合成输出。”
-
多头注意力(Multi-Head Attention)
- 多个视角同时观察句子,每个头关注不同关系模式,合并后理解更全面上下文
-
作用
- 抓住长距离关系:可以让句子开头和结尾的词互相关注
- 灵活分配关注:重要词得到更多权重
- 加速训练:比 RNN 并行计算更高效
- 掩码机制:可以屏蔽不该看的词,比如未来的词或填充的空位

4. 模型结构
4.1 Encoder
- 功能:理解输入文本,生成语义表示
- 典型模型:
- BERT:MLM + NSP 预训练
- RoBERTa:去掉 NSP、加大训练数据和批次
- ALBERT:参数共享、降低维度
- DistilBERT:知识蒸馏压缩模型
- 适用任务:文本分类、NER、抽取式问答
4.2 Decoder
- 功能:生成文本,逐步预测下一个词
- 典型模型:
- GPT 系列:纯自回归生成
- CTRL:条件生成,控制文本风格
- GPT-Neo / GPT-J:开源替代 GPT-3
- 适用任务:文本生成、续写、代码生成
4.3 Encoder-Decoder
- 功能:同时理解输入并生成输出
- 典型模型:
- T5:将所有 NLU 和 NLG 任务转为 Seq2Seq
- BART:结合 Encoder 和 Decoder 预训练,适用于理解与生成任务
- M2M-100:多语言翻译模型
- BigBird:处理超长文本,线性稀疏注意力
- 适用任务:机器翻译、文本摘要、生成式问答
5. Transformer Encoder
5.1 输入与嵌入
- 输入序列:原始文本 →(将原始文本切分成模型可以处理的最小单元。Tokenization)→ 词元 /分词(token)
- 词向量嵌入: Embedding(词向量),每个词映射为一个向量,把 离散的Token 映射成一个连续高维向量,用数字表示 Token 的语义信息。
- 位置编码:Positional Encoding,加入词在句子中的顺序信息
- 组合:input_embedding + positional_encoding
词向量表示词语含义,位置编码表示词语顺序 → 让模型既知道“词是什么”,也知道“词在哪”。
5.2 Encoder 层结构
每层 Encoder 主要包含两个子层:多头自注意力层 + 前馈网络。
5.2.1 多头自注意力 (Multi-Head Self-Attention)
- 输入:上一层输出 (或者最初的 embedding)
- 作用:捕捉句子中任意两个词之间的关系
- 计算步骤:
- 将输入投影为 Q、K、V:
- Q - Query:当前词想问的问题
- K - Key:每个词的标签或特征
- V - Value:每个词的实际信息
- 计算注意力权重

-
QK^T → 衡量每个 Query 和所有 Key 的相关性
-
Softmax (常用的归一化函数,用于将一个向量转换成概率分布(0~1,总和 = 1))
→ 把相关性归一化,得到注意力权重
-
权重矩阵 × V → 得到融合上下文的最终 Token 表示
- 多头机制:
- 不同头关注不同关系模式
- 最后合并各头信息,形成更丰富的上下文表示
直观理解:模型问“这个词应该关注哪些词?”,再把关注的词信息加权合并。
5.2.2 前馈网络 (Feed-Forward Network)
- 作用:对每个词的表示做非线性变换,提高表达能力
- 结构:通常是两层全连接 + 激活函数
- 残差连接 + 层归一化: output = LayerNorm(x + FFN(x))
- 残差连接:保留原输入信息,防止梯度消失
- Layer Norm:稳定训练,加快收敛
Token embeddingx
│
▼
LinearW1 + b1 (扩维)
│
激活函数 ReLU/GELU
│
LinearW2 + b2 (降维)
│
残差连接: x + FFN(x)
│
LayerNorm
│
输出表示 → 下一个 Encoder 层
5.3 Encoder 层总结
每层 Encoder 的输入 → 自注意力捕捉上下文 → 前馈网络增强表示 → 输出给下一层。
- 多层堆叠 → 捕捉深层次语义与长距离依赖
- 输出最终语义表示 → 可用于分类、序列标注、抽取式问答等任务
5.4 Encoder 流程图(简化)
输入序列
│
Embedding + Positional Encoding
│
┌───────────────────────────┐
│ Encoder Layer 1 │
│ ┌───────────────┐ │
│ │ Multi-Head │ │
│ │ Self-Attn │ │
│ └───────────────┘ │
│ ┌───────────────┐ │
│ │ Feed Forward │ │
│ └───────────────┘ │
└───────────────────────────┘
│
▼
──> Encoder Layer 2 → … → Encoder Layer N
│
▼
输出语义表示
6.什么是GPT?
GPT,或生成式预训练Transformer,是最早和最广为人知的LLM之一。
GPT诞生于OpenAI的研究,在Google引入Transformer架构一年后,即2018年。
它的继任者ChatGPT是当今最受欢迎的LLM之一。

GPT通过根据提示预测下一个单词/标记来生成文本。
这个过程称为自回归,意味着每个单词都是基于之前的单词生成的。

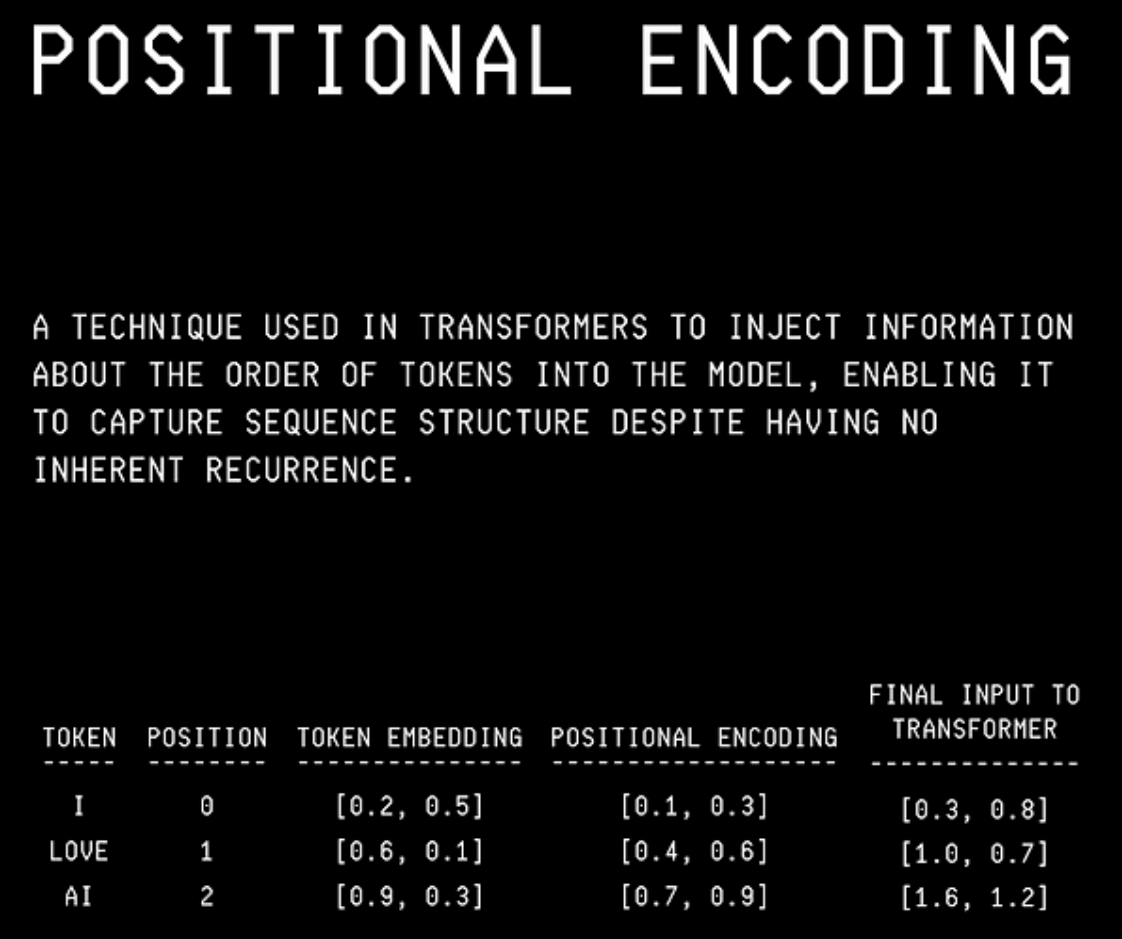
你会在描述GPT的图像中看到,它接受输入嵌入和位置编码作为输入。
这看起来有些奇怪,因为应该是单词/句子进入GPT才能产生下一个单词。
事实是,LLM不理解英语(或任何其他人类语言)。
任何英语单词/句子都必须首先被分解成称为标记的小片段,这个过程称为标记化。
在ChatGPT等LLM中,这是使用称为字节对编码的标记化算法完成的。
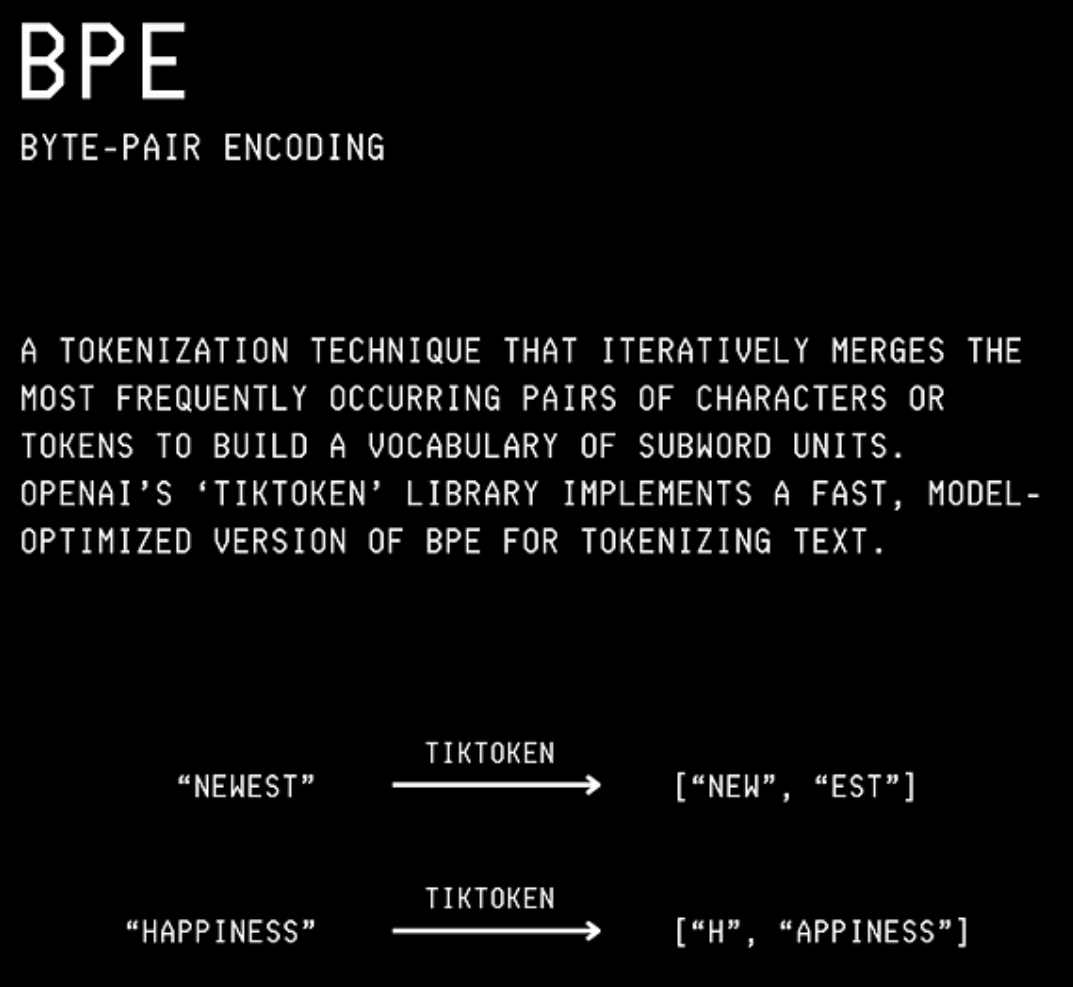
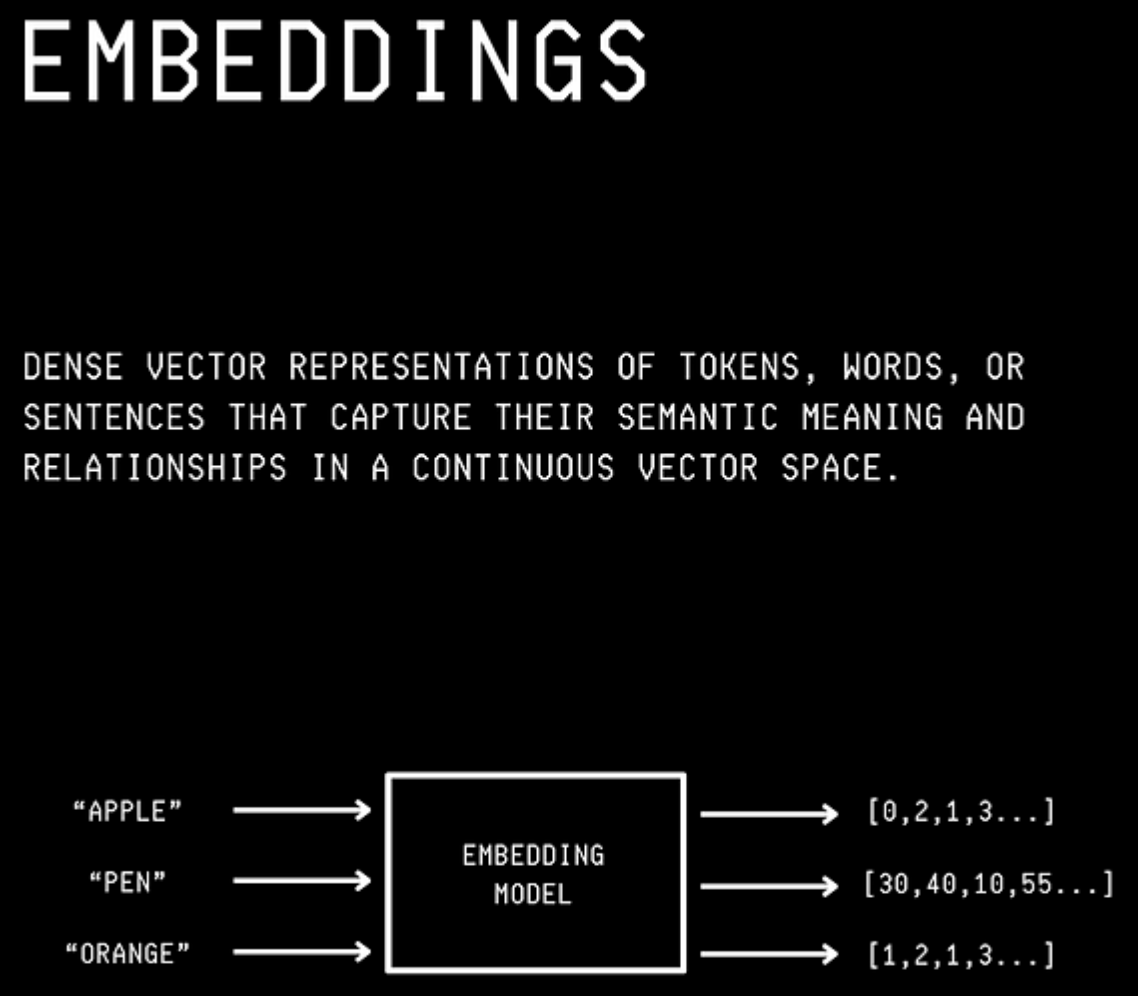
获得的标记然后被编码成称为嵌入的数学形式。
嵌入是高维向量表示,捕获不同单词/句子之间的语义含义和关系。
具有相似含义的单词在更高维空间中具有更接近的嵌入。
如下所示,“Apple”的嵌入比“Pen”更接近“Orange”。
我们之前讨论过LLM中的Transformer架构如何让它们并行处理所有单词/标记。
这可能会导致问题,因为在像英语这样的语言中,单词的位置对于传达含义很重要。
这就是为什么使用位置编码将句子中不同单词/标记的位置信息与这些单词/标记的输入嵌入相结合。
现在我们已经了解了LLM的内部机制,让我们讨论它们是如何训练的。
训练LLM生成文本
从零开始训练文本生成LLM的第一步是预训练。
在这个阶段,LLM通过处理大量未标记的文本数据集来学习。
在每一步中,它都被给予上下文(即之前的单词/标记),并被要求预测接下来的单词/标记。
这使它逐渐学习语法、事实和常识推理。

一旦我们获得了预训练的LLM,就可以通过在特定于这些任务的标记示例上训练它来适应特定任务。
这些任务可能包括模型回答问题、总结文档或更可靠地遵循指令。
这一步称为监督微调(SFT)。

在SFT之后,LLM可能会很好地执行任务,但其响应可能仍然偏离人类价值观。
例如,如果你问LLM“圣诞节是什么时候?”,它可能会回答“不是12月25日吗?”。
尽管这个回答是正确的,但你可能更喜欢听起来更有礼貌的回答,比如“圣诞节在每年的12月25日庆祝。”
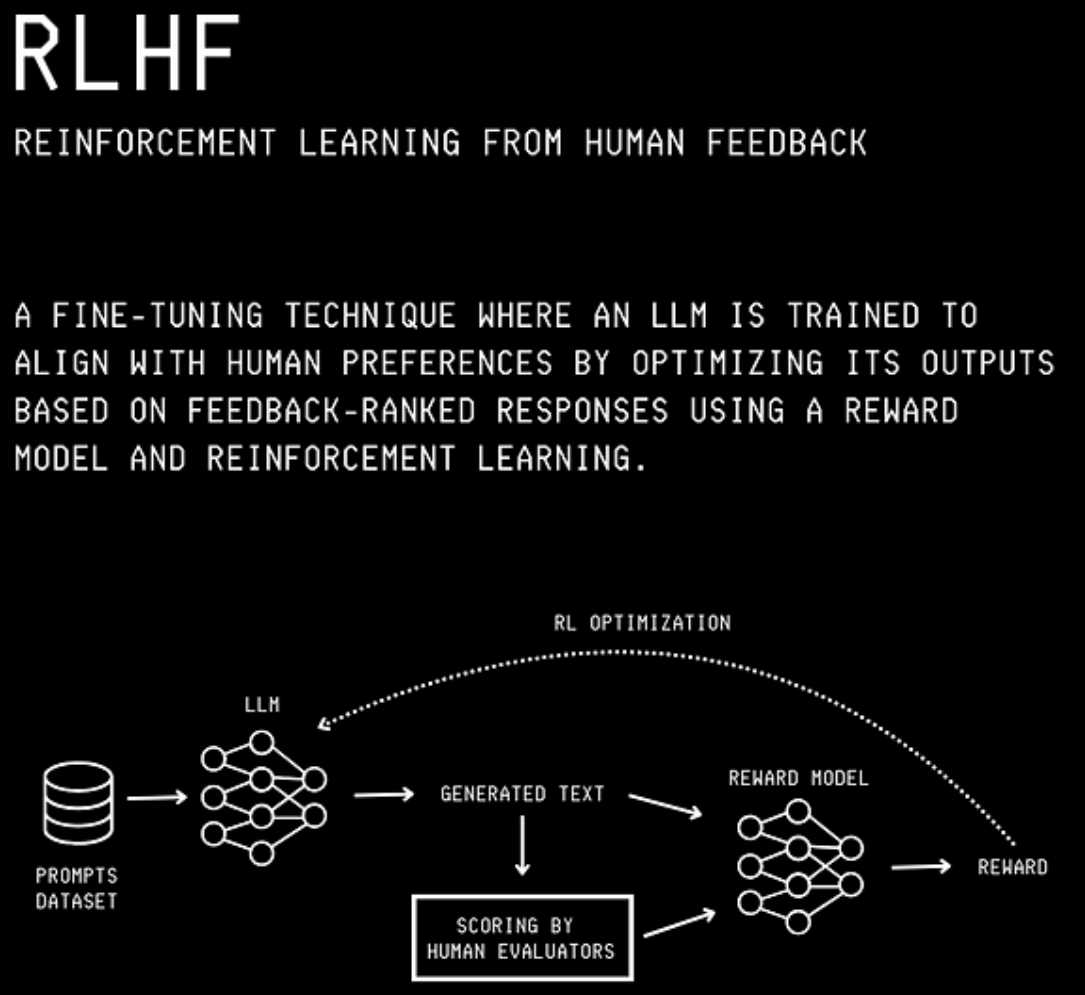
这是通过一种称为人类反馈强化学习(RLHF)的技术实现的。
RLHF通过使用人类判断数据集来指导哪些回答被认为是更好的,从而使LLM与人类价值观、偏好和期望保持一致。
它是使现代LLM(如ChatGPT)实现高对话质量和安全性的关键技术。
如何从LLM获得更好的响应?
提示是一种流行的技术,可以帮助你从LLM获得响应,整个称为提示工程的领域已经围绕这种做法出现。

两种提示方法很流行

除了这些,还引入了许多专门的提示技术,其中之一称为思维链(CoT)提示。
当遵循思维链(CoT)提示时,LLM被指示在提供答案之前逐步推理。
这提高了它在数学、逻辑和推理任务中的准确性

还有一种进一步训练LLM的方法,使它们内化这种思维链方法。这有助于它们在响应复杂问题时更好地思考和推理。
这是通过使用强化学习在大量提示示例及其思维链响应的数据集上训练LLM来实现的。
产生的LLM被称为大型推理模型(LRMs)。这些模型在回答查询之前会花时间思考。
当今使用的一些流行LRM包括:

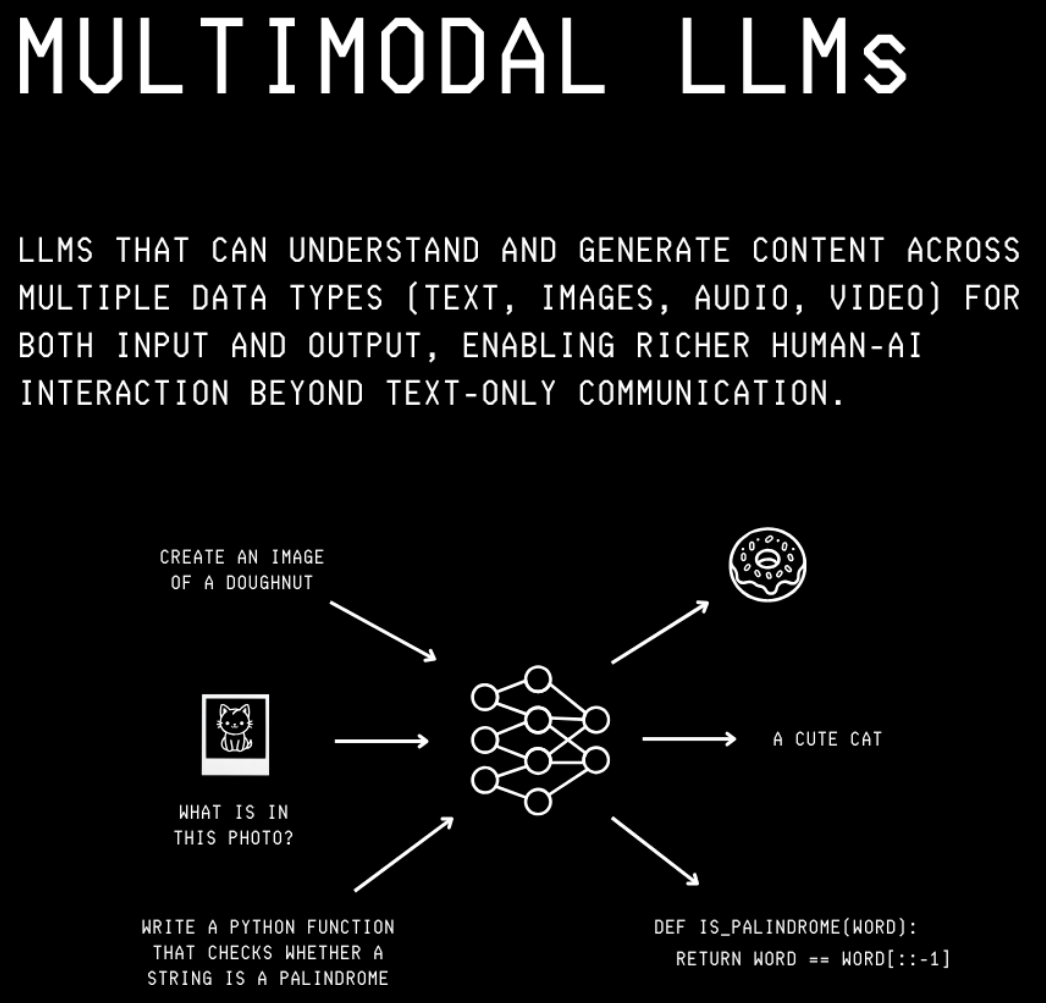
现代LLM是多模态的
LLM不仅仅是文本生成器,它们能做的远不止这些。
现代LLM是多模态的。这意味着它们可以处理来自不同模态(音频、图像和视频)的数据作为输入和输出。
https://mp.weixin.qq.com/s/taElsp0IdCPk7vt0hiMR3A

 浙公网安备 33010602011771号
浙公网安备 33010602011771号