


Dify 入门介绍
1. Dify 是什么?
Dify 是一个 开源 LLM 应用开发平台(Low-code/No-code),目标是让开发者和团队更快地构建和运营基于大语言模型(LLM)的应用。
它的名字来自 “Do It For You”。
特点:
-
🛠️ 低代码/可视化:支持在 Web 界面拖拽配置工作流。
-
🧩 即插即用:支持各种大模型(OpenAI、Claude、DeepSeek、Llama、Ollama 等)。
-
🖥️ 开发者友好:支持 Python/JS SDK,API 接口调用。
-
📊 监控 & 调优:提供日志、评测、向量库管理、数据观测等功能。
2. Dify 可以做什么?
-
AI 助手:客服机器人、个人助理。
-
知识库问答:上传 PDF、文档,接入企业知识库。
-
多模型编排:结合不同大模型完成复杂任务。
-
Agent 工作流:让 AI 具备工具调用、Web 搜索、数据库查询能力。
-
RAG 应用:Retrieval-Augmented Generation,结合向量库问答。
3. Dify 的核心功能
Dify 核心组件概览
Dify 的架构主要由 Web Frontend、API Backend、Worker 以及多个核心子系统构成,这些组件通过数据库、缓存和消息队列进行连接与协作。

1. Web Frontend
-
作用: 提供用户与 Dify 平台交互的图形化界面。开发者在这里创建、管理、调试和部署他们的 AI 应用(如聊天机器人、自动化工作流等)。所有操作,包括编排 Workflow、上传文件构建知识库、查看对话历史等,都通过它完成。
-
技术: 通常基于现代框架如 Next.js 和 React 构建。
2. API Backend
-
作用: 这是 Dify 的核心大脑和交通枢纽。它承担了以下关键职责:
-
请求处理: 接收来自 Web Frontend 或第三方集成的所有 RESTful API 请求。
-
业务逻辑: 执行应用程序的核心逻辑,例如管理对话、协调工作流执行、处理检索增强生成(RAG)请求等。
-
系统协调: 它本身不处理所有任务,而是作为协调者,调用其他子系统(如 Model Provider System, RAG System)并与其他基础设施(数据库、缓存)交互来完成请求。
-
身份验证与授权: 验证用户身份和权限。
-
-
技术: 通常使用 Python 框架(如 Flask 或 Django)构建。
3. Celery Worker
-
作用: 专门处理异步和耗时任务的后台进程。它的存在是为了避免长时间运行的任务阻塞 API Backend 的即时响应。
-
典型任务: 为上传的文档构建索引。这个过程涉及读取文件、文本分块、生成向量嵌入(Embeddings)并写入向量数据库,非常消耗资源和时间,必须异步处理。
-
-
关系: 通过消息队列(如 Redis)从 API Backend 接收任务。处理完成后,会更新数据库中的任务状态。
4. 核心子系统 (Core Subsystems)
这些子系统是 API Backend 内部的逻辑模块,是实现不同功能的核心。
-
Conversation System
-
作用: 管理用户与 AI 应用之间的所有对话交互。负责创建对话会话(Session)、保存和检索对话历史消息、维护对话的上下文状态。这是实现连贯多轮对话的基础。
-
-
Workflow System
-
作用: 提供一个可视化工具(基于 ReactFlow 等库),允许用户通过拖放节点(Node)的方式,编排复杂、多步骤的 AI 任务流水线。节点类型包括 LLM 调用、工具调用、条件判断、知识检索等。
-
关系: 在执行时,它会调用 Model Provider System 来获取 LLM 响应,也可以调用 RAG Knowledge System 来检索信息,或执行代码、调用外部 API 工具。
-
-
RAG Knowledge System (或 Dataset System)
-
作用: 实现检索增强生成(RAG)全流程的系统。
-
处理知识库: 管理数据集的创建、文档上传、解析、分块。
-
生成与存储索引: 协调文本的向量化过程,并将向量嵌入(Embeddings)存储到向量数据库(VectorDB)中。
-
检索: 在查询时,根据用户问题从向量数据库中快速检索出最相关的文本片段,作为上下文提供给 LLM。
-
-
关系: 严重依赖 VectorDB 和 Celery Worker(用于异步索引文档)。
-
-
Model Provider System
-
作用: 作为 LLM 的抽象层和统一网关。它集成了众多模型提供商(如 OpenAI, Anthropic, Azure OpenAI, 本地部署模型等),并对上层应用提供一致的调用接口。开发者在这里配置和管理不同模型的 API 密钥和参数。
-
关系: 被 API Backend(处理直接聊天请求时)和 Workflow System(执行 LLM 节点时)调用,是平台与外部 AI 模型连接的桥梁。
-
5. 数据存储与基础设施 (Data Storage & Infrastructure)
-
PostgreSQL:
-
作用: 主数据库。存储所有结构化数据,包括但不限于:
-
用户账户和权限设置
-
AI 应用的配置信息
-
对话记录(Conversation history)
-
Workflow 的编排定义
-
数据集(Dataset)元数据信息
-
-
-
VectorDB (e.g., Qdrant, Weaviate, Milvus):
-
作用: 向量数据库。专门用于存储和高效查询由文本生成的向量嵌入(Embeddings)。是 RAG 知识系统的核心存储,通过相似性搜索实现语义检索。
-
-
Redis:
-
作用: 多功能用途。
-
缓存(Cache): 缓存频繁访问的数据(如会话状态、应用配置),减轻数据库压力,提升响应速度。
-
消息代理(Message Broker): 作为 Celery 的任务队列,在 API Backend 和 Worker 之间传递异步任务消息。
-
-
-
File Storage (e.g., S3, MinIO, Local Storage):
-
作用: 存储用户上传的原始文件(如 PDF、Word 文档、图片等)。
-
组件间如何协作
Dify 的各个组件并非孤立工作,而是紧密协作的:
-
用户通过 Web 前端 发起请求,例如创建一个新的聊天应用或启动一个工作流。
-
请求到达 API 后端 (Flask),后端根据请求类型协调相应的核心子系统。
-
子系统处理:
-
如果是聊天请求,会话系统 会管理对话状态,并可能调用 模型供应系统 来获取LLM的响应,必要时通过 RAG 知识系统 从知识库检索信息增强上下文。
-
如果是工作流执行,工作流系统 会解析流程定义,按顺序执行各个节点。节点可能调用 模型供应系统 中的LLM、通过 工具集成 访问外部服务,或使用 RAG 知识系统 进行检索。
-
-
数据存储与访问:在整个过程中,PostgreSQL 用于存储结构化数据(如用户信息、应用配置),向量数据库 为 RAG 提供支撑,Redis 用于缓存和任务队列,文件存储 系统保存用户上传的文档。
-
异步任务处理:对于耗时操作(如文档索引),API 后端会将任务发送到 消息队列 (Redis),由 Celery 工作节点 在后台异步处理。
-
最终响应 通过 API 后端返回给 Web 前端,呈现给用户。
4. 快速上手(本地部署)
最简单的方式是 Docker 一键部署:
默认会进入 Dify 的 Web 管理界面。
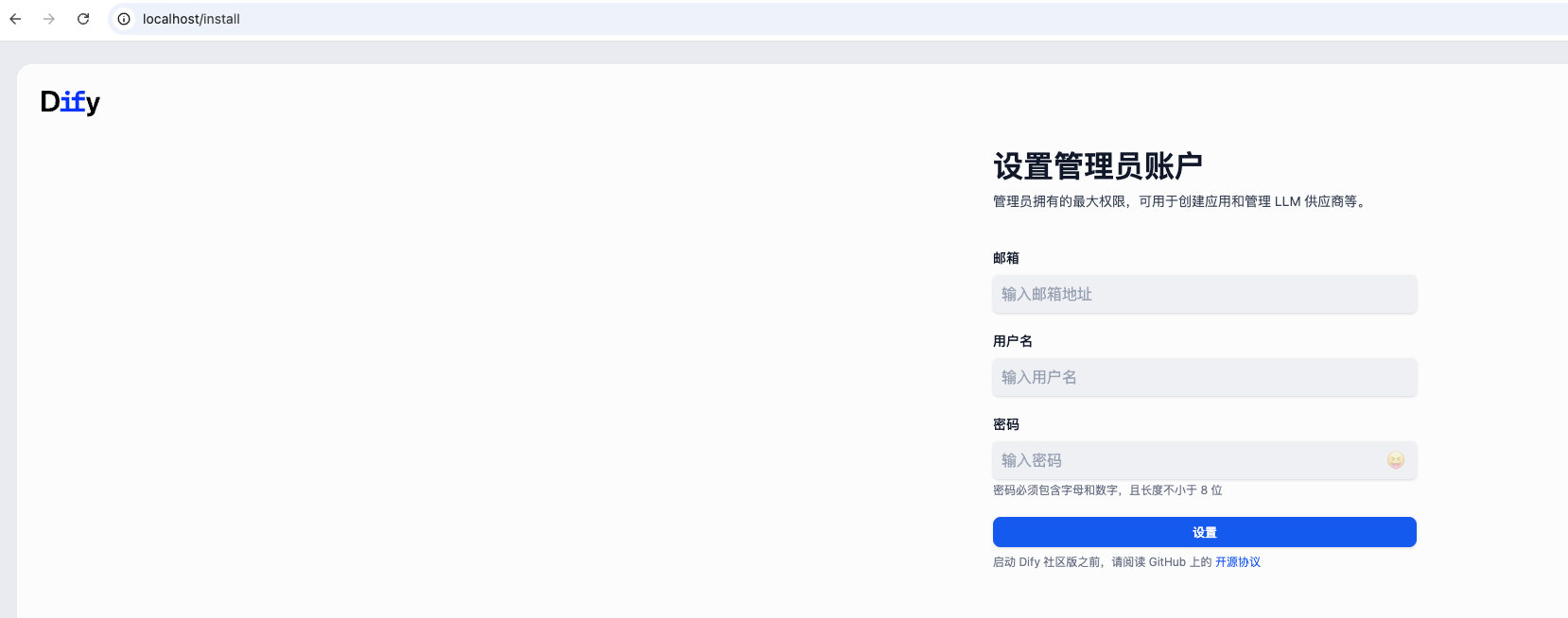
例如我输入的:
设置完成后,进入管理控制台
安装免费大模型:
免费可用的 LLM 方案
1. Ollama(推荐,Mac 上特别方便)
安装(Homebrew 安装(Mac 命令行方式)
如果你习惯用 brew:
安装好之后可以验证:
常见模型(免费):
llama3(Meta 出品,性能不错)
mistral(速度快,轻量)
gemma(Google 出品的小模型)
安装完成后,可以直接在 Mac 终端运行一个模型,例如:
它会自动下载 llama3 模型(几百 MB 到几 GB 不等,看具体模型)。
- llama3 -> 4.7G
-
最小最快 →
tinyllama(0.5G) -
兼顾效果 →
gemma:2b或phi3:mini(1–2G 左右) -
效果更好 →
mistral(4G+,比 llama3 小一些)
在 Dify 里可以配置 Ollama 作为 LLM 提供者,这样就能直接跑免费模型。
2. OpenAI 的免费额度
注册 OpenAI 新账号有时会送少量免费额度(但需要支持的地区手机号),不稳定。
3. 其他可用的免费开源模型
Hugging Face Inference API:部分小模型可以免费调用(有速率限制)。
LM Studio:桌面应用,可以下载并本地运行开源模型,类似 Ollama。
Google Colab / Kaggle Notebook:可以临时跑一些大模型,但需要挂在线 GPU。
dify配置本地大模型
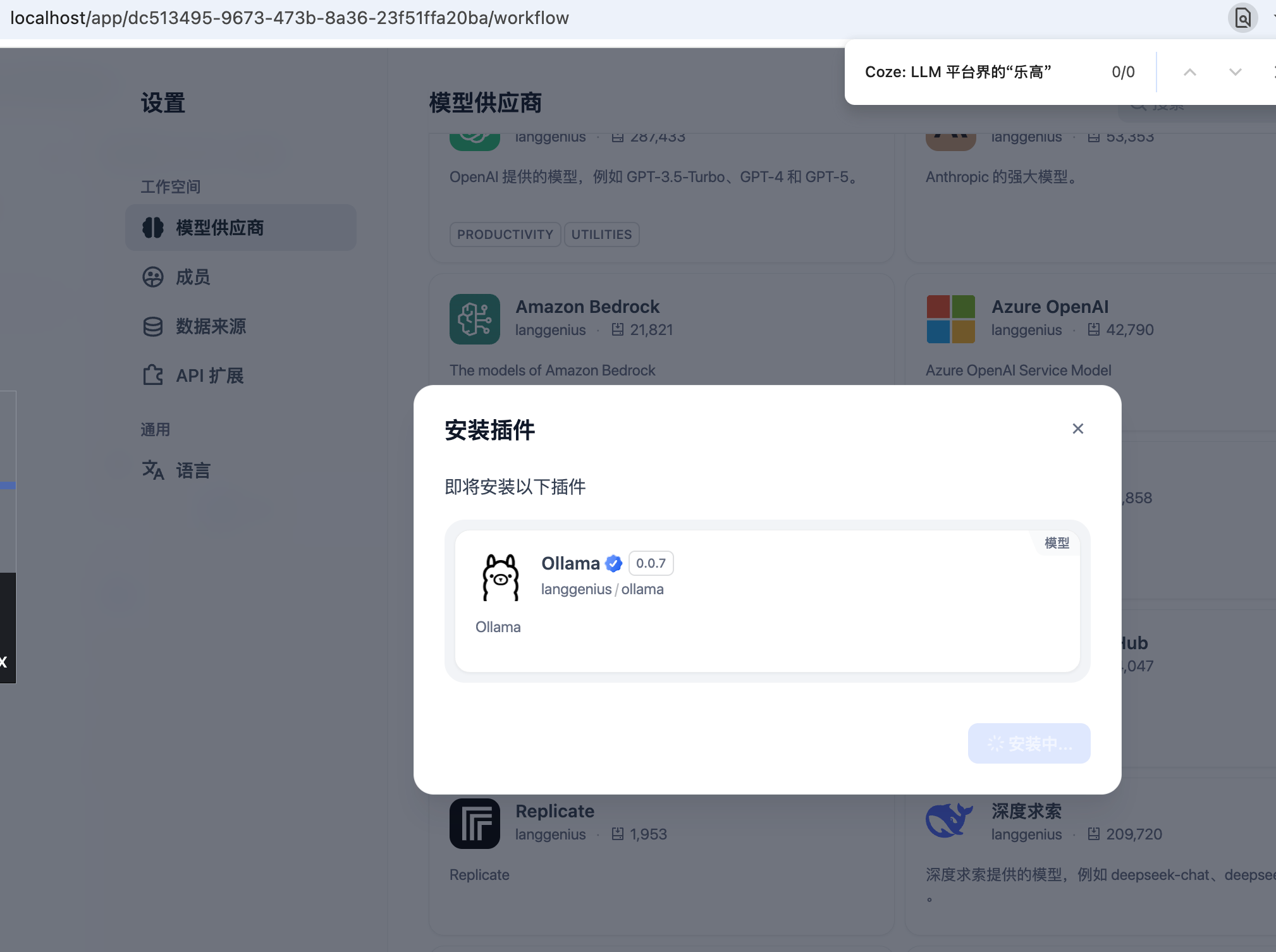
在为Ollama添加本地tinyllama模型之前,先在命令行窗口启动tinyllama模型:

然后在回到dify的配置:
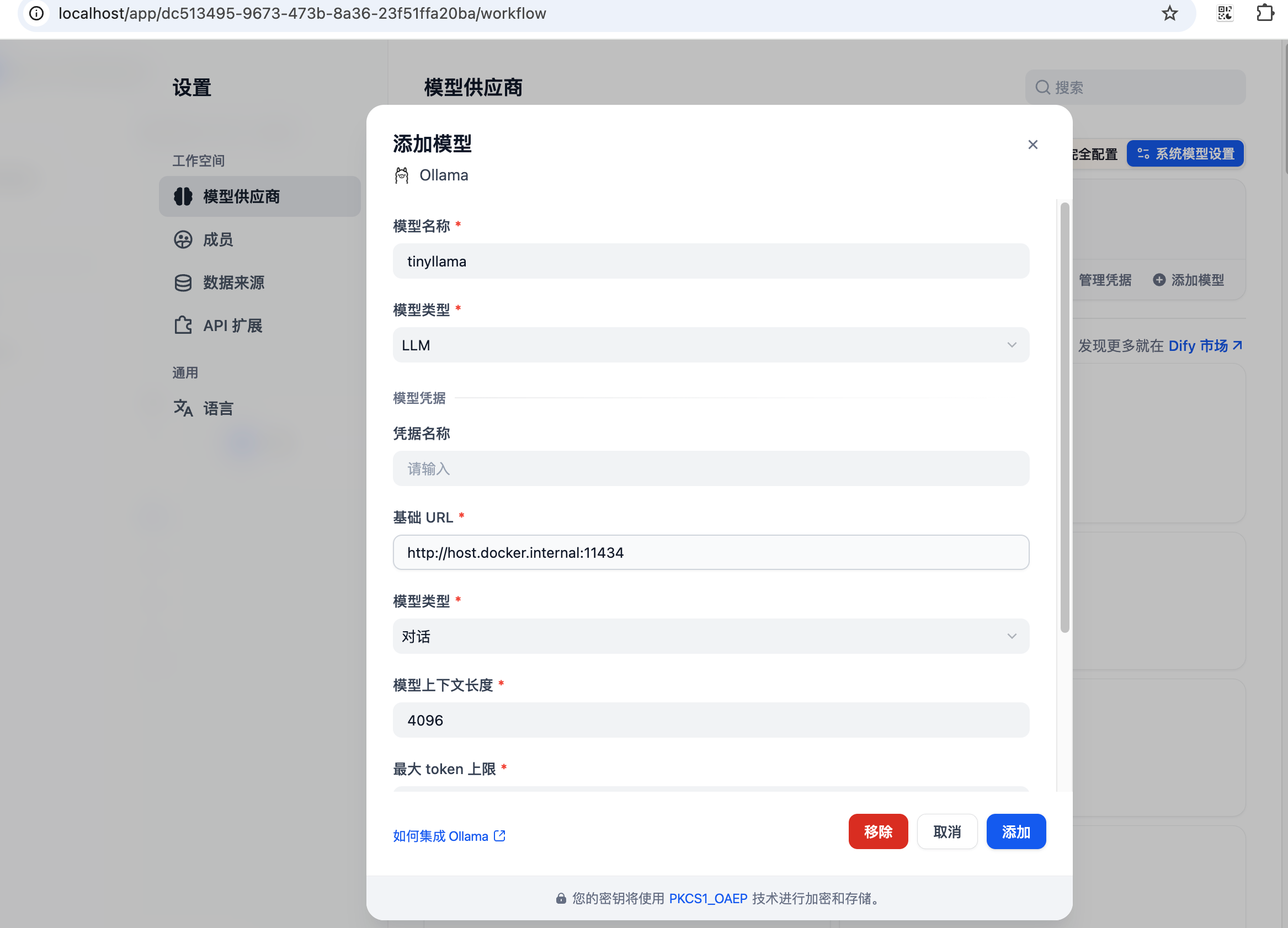
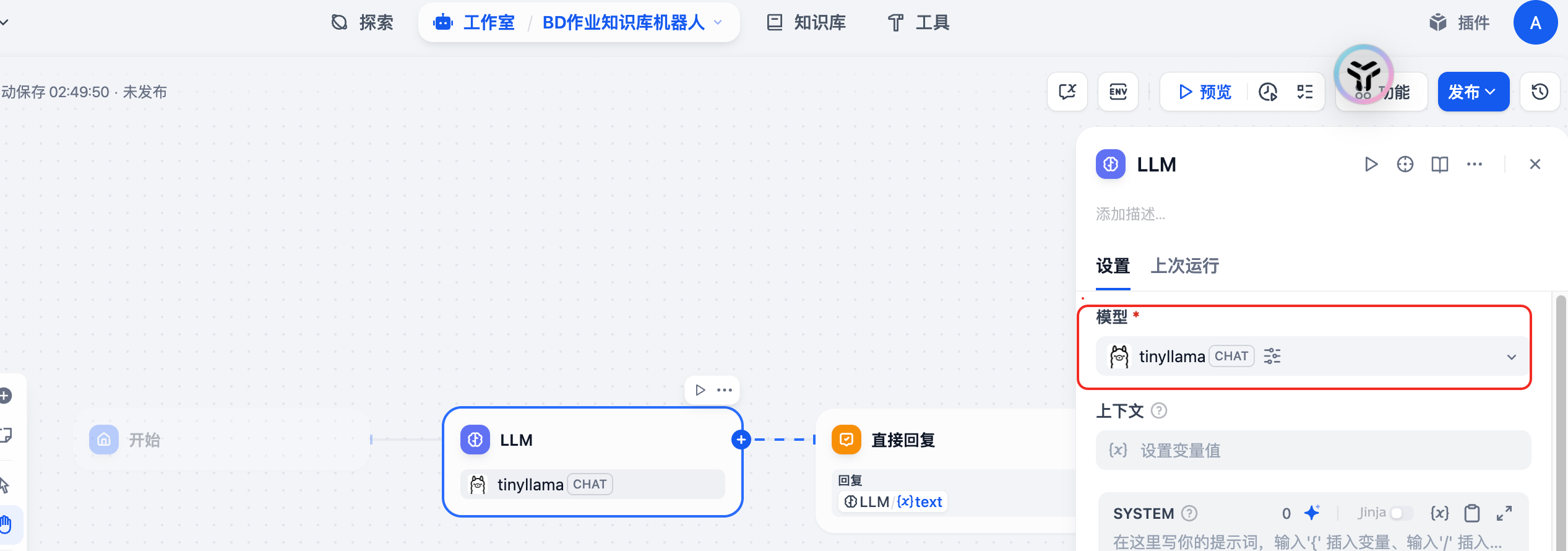
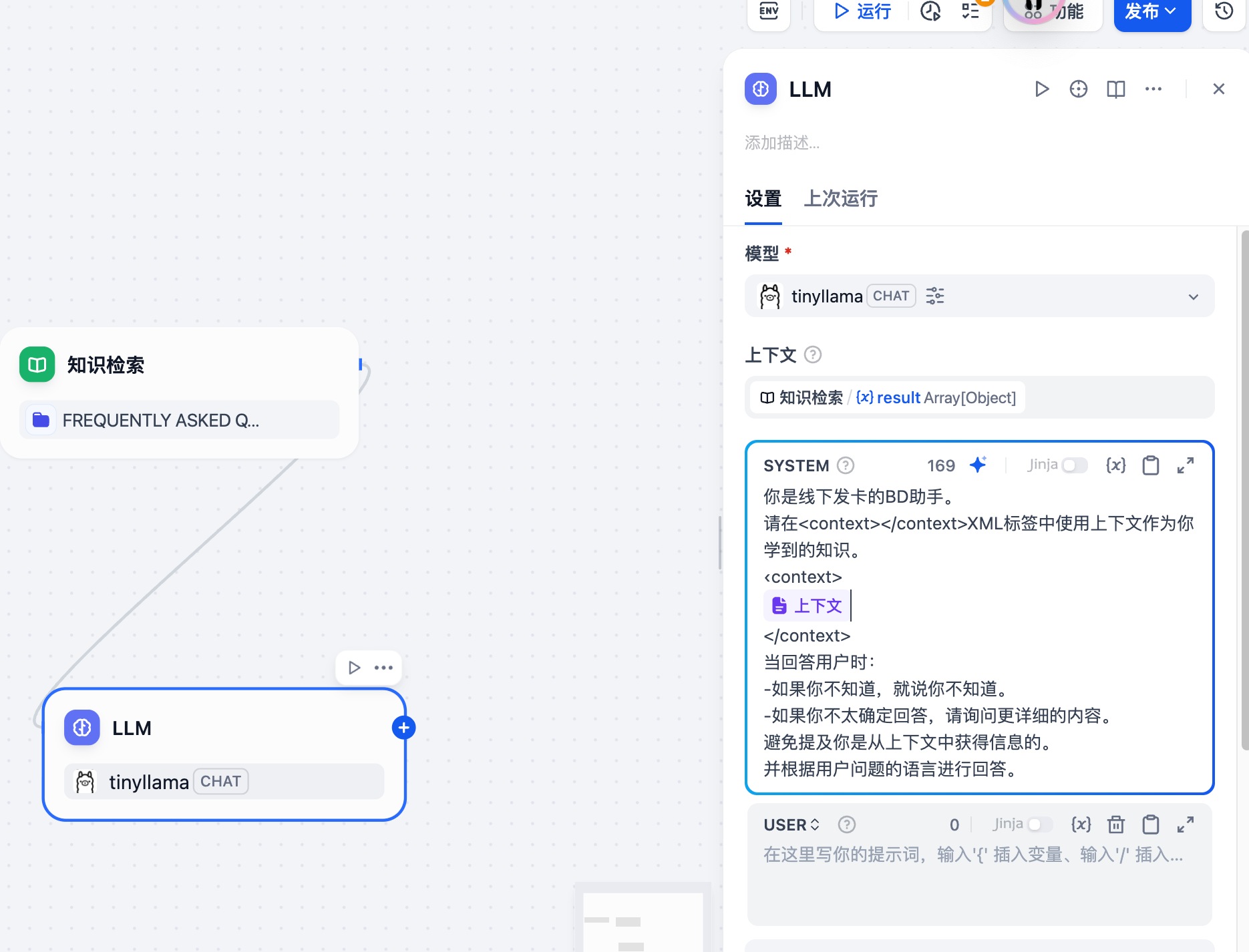
通过ip远程配置ollama
我的测试是讲ollama安装在台式机window10上,其下载的模型是gpt-oss:20b,在ollama的Settings中设置可以暴露在网络上。
在mac电脑访问ip:11434/api/tags后,返回如下:

在dify中集成,配置如下:
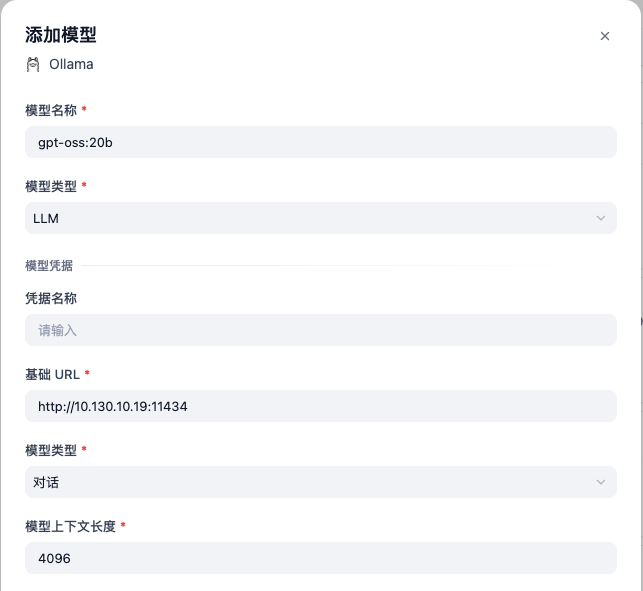
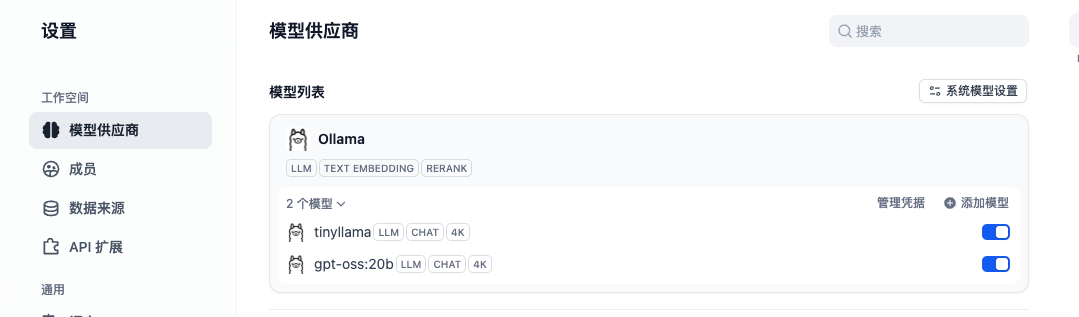
配置成功后,如下:
5. 典型使用流程
-
创建应用
-
在 Web 界面点“新建应用” → 选择模板(如知识库助手)。
-
-
配置模型
-
绑定 OpenAI Key、Claude、DeepSeek 等模型。
-
-
上传数据
-
上传文档作为知识库,选择切分和存储方式。
-
-
测试调试
-
在 Dify 内置 Playground 里直接对话测试。
-
-
对外发布
-
生成 API Key,应用就可以被你的 Web/APP/机器人调用。
-
6. 进阶玩法
Dify 平台设有四种不同层级的 AI 应用搭建模式,能够满足从入门到高阶的开发需求:
- 对话助手(Chatbot) 作为入门级解决方案,能帮助开发者快速搭建智能对话系统。借助可视化界面来配置对话逻辑和知识库,无需编写代码就能创建出具备基础问答能力的 AI 助手,是探索大语言模型应用的绝佳起点。
- 智能代理(Agent) 属于进阶型应用框架,它能赋予 AI 自主决策与执行的能力。系统可以根据用户的意图进行动态推理,并智能调用 API 工具链来完成复杂操作,例如实时数据查询、事务处理等,从而实现从“回答问题”到“解决问题”的转变。
- 对话流程(Chatflow) 是支持上下文记忆的多轮交互系统。它通过状态机机制对对话进程进行管理,能够处理包含分支逻辑的深度会话场景,适用于客户服务、教育辅导等需要持续跟踪对话上下文的专业场景。
- 自动化工作流(Workflow) 是面向单次任务的高效处理引擎。它采用节点式编排设计,支持将大语言模型能力与传统系统服务无缝结合,可快速搭建数据提取、内容生成等批处理任务,有效提升业务自动化水平。
7. 学习资料
-
🌐 官方网站:https://dify.ai
-
📖 GitHub 项目:https://github.com/langgenius/dify
-
📚 文档中心:https://docs.dify.ai
⚡总结一句话:
Dify = 一站式 AI 应用开发平台,既能让小白通过拖拽快速做应用,也能让开发者通过 API 深度集成到业务系统里。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号