
Redis单线程模型,redis6的多线程模型
为什么单线程还能这么快
通常来讲,单线程处理能力要比多线程差,那么为什么Redis使用单线程模型会达到每秒万级别的处理能力呢?可以将其归结为三点:
- 第一:纯内存访问,Redis将所有数据放在内存中,内存的响应时长大约为100纳秒,这是Redis达到每秒万级别访问的最重要的基础。
- 第二:非阻塞I/O,Redis使用epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间
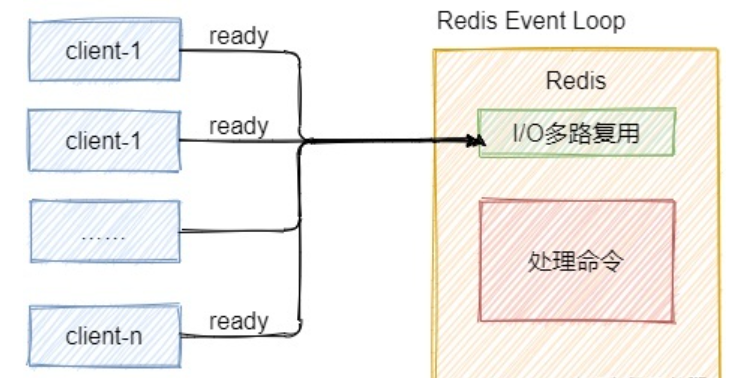
「这里再扩展一下I/O多路复用:」
引用知乎上一个高赞的回答来解释什么是I/O多路复用。假设你是一个老师,让30个学生解答一道题目,然后检查学生做的是否正确,你有下面几个选择:
- 第一种选择:按顺序逐个检查,先检查A,然后是B,之后是C、D。。。这中间如果有一个学生卡主,全班都会被耽误。这种模式就好比,你用循环挨个处理socket,根本不具有并发能力。
- 第二种选择:你创建30个分身,每个分身检查一个学生的答案是否正确。 这种类似于为每一个用户创建一个进程或者线程处理连接。
- 第三种选择,你站在讲台上等,谁解答完谁举手。这时C、D举手,表示他们解答问题完毕,你下去依次检查C、D的答案,然后继续回到讲台上等。此时E、A又举手,然后去处理E和A。
第一种就是阻塞IO模型,第三种就是I/O复用模型,Linux下的select、poll和epoll就是干这个的。将用户socket对应的fd注册进epoll,然后epoll帮你监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻塞模式。
这样,整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor模式。
- 第三:单线程避免了线程切换和竞态产生的消耗。
我们继续来看Redis单线程却很快的最后一条原因,在多线程开发中,存在线程的切换和竞争,这样一来,是有时间的消耗的。对于需要磁盘I/O的程序来讲,磁盘I/O是一个比较耗时的操作,所以对于需要进行磁盘I/O的程序,我们可以使用多线程,在某个线程进行I/O时,CPU切换到当前程序的其他线程执行,以此减少CPU的等待时间。
那么问题来了。Redis的数据存放在内存中,将内存中的数据读入CPU时,CPU不是依然需要等待吗,为什么不能在等待数据从内存读入CPU期间执行其他线程,以此提高CPU的使用率呢?这个问题的答案很简单,内存的读些速度虽然比CPU慢很多,但是也是非常快的。CPU切换线程需要花费一定的时间,而多次切换线程所花费的时间,可能比直接使用单线程执行相同的任务,花费的时间要更多,这是非常不划算的。
单线程也会有一个问题:对于每个命令的执行时间是有要求的。如果某个命令执行过长,会造成其他命令的阻塞,对于Redis这种高性能的服务来说是致命的,所以Redis是面向快速执行场景的数据库。
Redis文件事件处理器
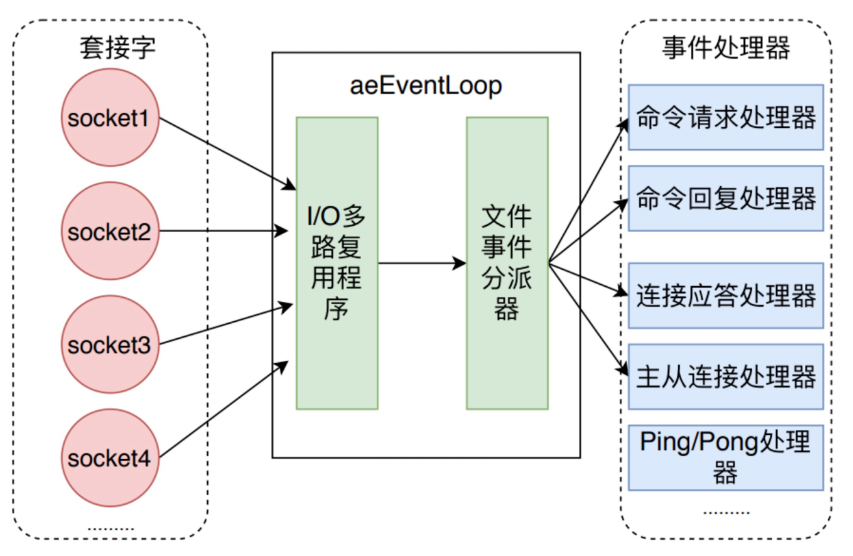
一、Redis 文件事件处理器由四个部分组成:套接字、I/O多路复用程序、文件时间分派器(dispatcher)、事件处理器。
文件事件是对套接字操作的抽象,每当一个套接字准备好执行连接应答(accept)、写入(write)、读取(read)、关闭(close)等操作时,就会相应产生一个文件事件。
I/O多路复用器负责通过loop循环监听多个套接字,同时将一系列套接字按循序存储到一个队列中,由队列向文件事件分派器传送队列中套接字。这个队列中套接字是有序的,它会当一个套接字事件被处理完毕后,会立马向文件事件分配器传送下一个套接字。
文件事件分配器接受队列中的套接字并根据套接字产生的事件类型,相应调用不同的事件处理器。
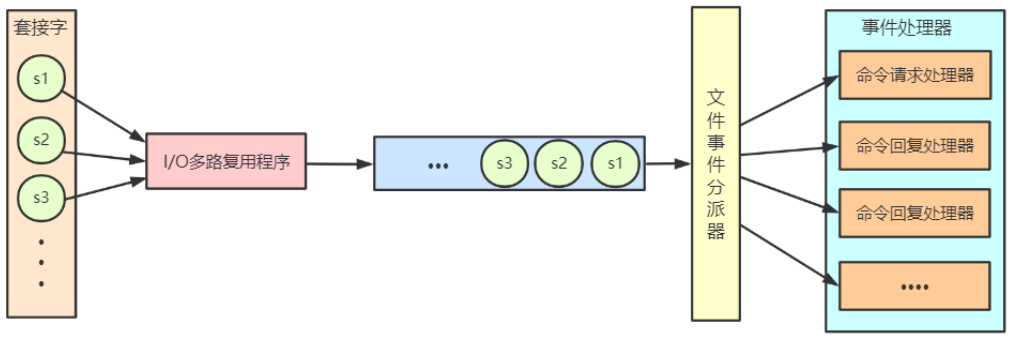
图1 Redis 文件事件处理器过程

图2 I/O多路复用程序通过队列向文件事件分派器传送套接字
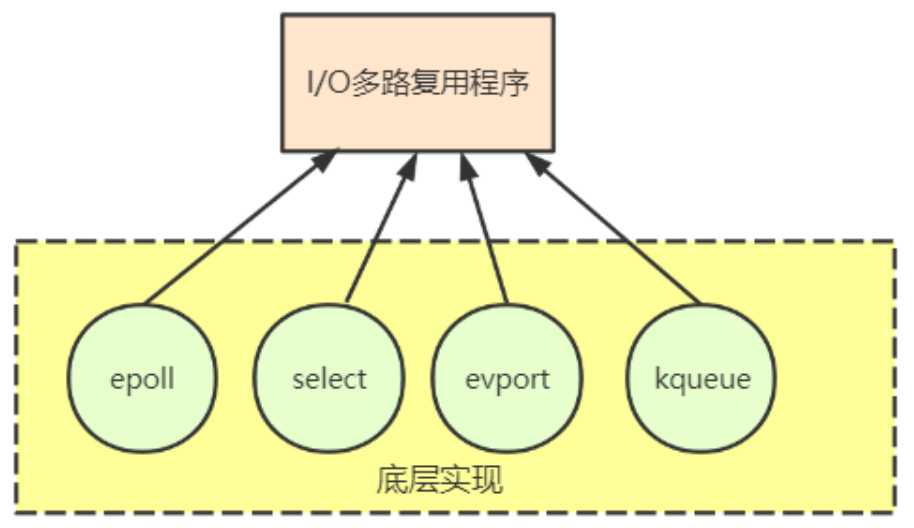
图3 Redis I/O 多路复用调用的多路复用库
二、在 Redis 的事件处理器中,服务器中最常用有:
(1)连接应答处理器 (2)命令请求处理器 (3)命令恢复处理器
前言
Redis 是一个事件驱动的内存数据库,服务器需要处理以下两类事件:
文件事件:Redis服务器通过套接字与客户端(或者其他Redis服务器)进行连接,而文件事件就是服务器对套接字操作的抽象;服务器与客户端的通信会产生相应的文件事件,而服务器则通过监听并处理这些事件来完成一系列网络通信操作,比如连接accept,read,write,close等;时间事件:Redis服务器中的一些操作(比如serverCron函数)需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象,比如过期键清理,服务状态统计等。
下面就会介绍这两种事件的实现原理。
文件事件
Redis 服务器通过 socket 实现与客户端(或其他redis服务器)的交互,文件事件就是服务器对 socket 操作的抽象。 Redis 服务器,通过监听这些 socket 产生的文件事件并处理这些事件,实现对客户端调用的响应。
Reactor
Redis 基于 Reactor 模式开发了自己的事件处理器。Redis将文件事件和时间事件进行抽象,时间轮训器会监听I/O事件表,一旦有文件事件就绪,Redis就会优先处理文件事件,接着处理时间事件。在上述所有事件处理上,Redis都是以单线程形式处理,所以说Redis是单线程的。此外,如下图,Redis基于Reactor模式开发了自己的I/O事件处理器,也就是文件事件处理器,Redis在I/O事件处理上,采用了I/O多路复用技术,同时监听多个套接字,并为套接字关联不同的事件处理函数,通过一个线程实现了多客户端并发处理。
这里就先展开讲一讲 Reactor 模式。看下图:
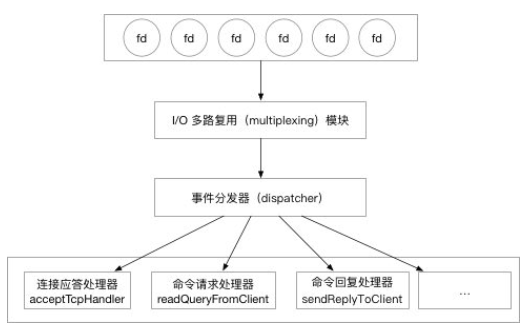
多路复用件:“I/O 多路复用模块”会监听多个 FD ,当这些FD产生,accept,read,write 或 close 的文件事件。会向“文件事件分发器(dispatcher)”传送事件。
正因为这样的设计,在数据处理上避免了加锁操作,既使得实现上足够简洁,也保证了其高性能。当然,Redis单线程只是指其在事件处理上,实际上,Redis也并不是单线程的,比如生成RDB文件,就会fork一个子进程来实现,当然,这不是本文要讨论的内容。
文件事件分发器(dispatcher)在收到事件之后,会根据事件的类型将事件分发给对应的 handler。
我们顺着图,从上到下的逐一讲解 Redis 是怎么实现这个 Reactor 模型的。Redis的文件事件处理器的四个组成部分:
- 套接字;
- IO 多路复用程序;
- 文件事件分派器(dispatcher);
- 事件处理器;
I/O 多路复用模块
Redis 的 I/O 多路复用模块,其实是封装了操作系统提供的 select,epoll,avport 和 kqueue 这些基础函数。向上层提供了一个统一的接口,屏蔽了底层实现的细节。
一般而言 Redis 都是部署到 Linux 系统上,所以我们就看看使用 Redis 是怎么利用 linux 提供的 epoll 实现I/O 多路复用。
首先看看 epoll 提供的三个方法:
再看 Redis 对文件事件,封装epoll向上提供的接口:
所以看看这个ae_peoll.c 如何对 epoll 进行封装的:
- aeApiCreate() 是对 epoll.epoll_create() 的封装。
- aeApiAddEvent()和aeApiDelEvent() 是对 epoll.epoll_ctl()的封装。
- aeApiPoll() 是对 epoll_wait()的封装。
这样 Redis 的利用 epoll 实现的 I/O 复用器就比较清晰了。
再往上一层次我们需要看看 ea.c 是怎么封装的?
首先需要关注的是事件处理器的数据结构:
mask 就是可以理解为事件的类型。
除了使用 ae_peoll.c 提供的方法外,ae.c 还增加 “增删查” 的几个 API。
- 增:aeCreateFileEvent
- 删:aeDeleteFileEvent
- 查: 查包括两个维度 aeGetFileEvents 获取某个 fd 的监听类型和aeWait等待某个fd 直到超时或者达到某个状态。
事件分发器(dispatcher)
Redis 的事件分发器 ae.c/aeProcessEvents 不但处理文件事件还处理时间事件,所以这里只贴与文件分发相关的出部分代码,dispather 根据 mask 调用不同的事件处理器。
可以看到这个分发器,根据 mask 的不同将事件分别分发给了读事件和写事件。
文件事件处理器的类型
Redis 有大量的事件处理器类型,我们就讲解处理一个简单命令涉及到的三个处理器:
- acceptTcpHandler 连接应答处理器,负责处理连接相关的事件,当有client 连接到Redis的时候们就会产生 AE_READABLE 事件。引发它执行。
- readQueryFromClinet 命令请求处理器,负责读取通过 sokect 发送来的命令。
- sendReplyToClient 命令回复处理器,当Redis处理完命令,就会产生 AE_WRITEABLE 事件,将数据回复给 client。
文件事件实现总结
我们按照开始给出的 Reactor 模型,从上到下讲解了文件事件处理器的实现,下面将会介绍时间事件的实现。
时间事件
Reids 有很多操作需要在给定的时间点进行处理,时间事件就是对这类定时任务的抽象。
先看时间事件的数据结构:
/* Time event structure * * 时间事件结构 */ typedef struct aeTimeEvent { // 时间事件的唯一标识符 long long id; /* time event identifier. */ // 事件的到达时间 long when_sec; /* seconds */ long when_ms; /* milliseconds */ // 事件处理函数 aeTimeProc *timeProc; // 事件释放函数 aeEventFinalizerProc *finalizerProc; // 多路复用库的私有数据 void *clientData; // 指向下个时间事件结构,形成链表 struct aeTimeEvent *next; } aeTimeEvent;
看见 next 我们就知道这个 aeTimeEvent 是一个链表结构。看图:

注意:这是一个按照id倒序排列的链表,并没有按照事件顺序排序。
processTimeEvent
Redis 使用这个函数处理所有的时间事件,我们整理一下执行思路:
- 记录最新一次执行这个函数的时间,用于处理系统时间被修改产生的问题。
- 遍历链表找出所有 when_sec 和 when_ms 小于现在时间的事件。
- 执行事件对应的处理函数。
- 检查事件类型,如果是周期事件则刷新该事件下一次的执行事件。
- 否则从列表中删除事件。
综合调度器(aeProcessEvents)
综合调度器是 Redis 统一处理所有事件的地方。我们梳理一下这个函数的简单逻辑:
以上的伪代码就是整个 Redis 事件处理器的逻辑。
我们可以再看看谁执行了这个 aeProcessEvents:
然后我们再看看是谁调用了 eaMain:
我们在 Redis 的 main 方法中找个了它。
这个时候我们整理出的思路就是:
- Redis 的 main() 方法执行了一些配置和准备以后就调用 eaMain() 方法。
- eaMain() while(true) 的调用 aeProcessEvents()。
所以我们说 Redis 是一个事件驱动的程序,期间我们发现,Redis 没有 fork 过任何线程。所以也可以说 Redis 是一个基于事件驱动的单线程应用。
总结
在后端的面试中 Redis 总是一个或多或少会问到的问题。
读完这篇文章你也许就能回答这几个问题:
为什么 Redis 是一个单线程应用?
为什么 Redis 是一个单线程应用,却有如此高的性能?
如果你用本文提供的知识点回答这两个问题,一定会在面试官心中留下一个高大的形象。
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对服务器之家的支持。
2、支持多线程的Redis6.0
“Redis不是单线程吗?怎么又支持多线程了?”
Redis作为一个基于内存的缓存系统,一直以高性能著称,因没有上下文切换以及无锁操作,即使在单线程处理情况下,读速度仍可达到11万次/s,写速度达到8.1万次/s。但是,单线程的设计也给Redis带来一些问题:
- 只能使用CPU一个核;
- 如果删除的键过大(比如Set类型中有上百万个对象),会导致服务端阻塞好几秒;
- QPS难再提高。
针对上面问题,Redis在4.0版本以及6.0版本分别引入了Lazy Free以及多线程IO,逐步向多线程过渡,下面将会做详细介绍。
Redis6.0引入了多线程的特性,这个多线程是在哪里呢?——「是对处理网络请求过程采用了多线程」。
Redis 6.0采用多个IO线程来处理网络请求,网络请求的解析可以由其他线程完成,然后把解析后的请求交由主线程进行实际的内存读写。提升网络请求处理的并行度,进而提升整体性能。
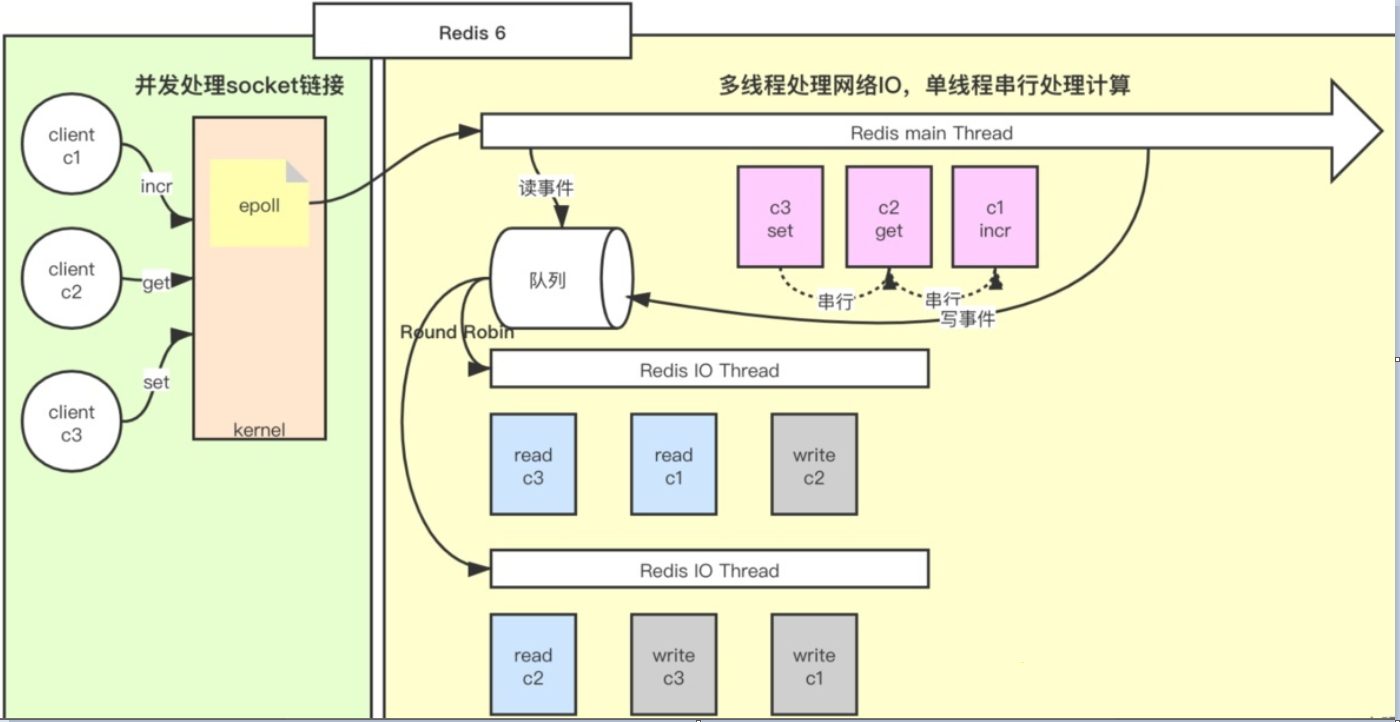
那么多并发的线程安全问题存在吗?——当然不存在。Redis 的多 IO 线程只是用来处理网络请求的,对于命令的执行,Redis 仍然使用单线程来处理。
Lazy Free机制
如上所知,Redis在处理客户端命令时是以单线程形式运行,而且处理速度很快,期间不会响应其他客户端请求,但若客户端向Redis发送一条耗时较长的命令,比如删除一个含有上百万对象的Set键,或者执行flushdb,flushall操作,Redis服务器需要回收大量的内存空间,导致服务器卡住好几秒,对负载较高的缓存系统而言将会是个灾难。为了解决这个问题,在Redis 4.0版本引入了Lazy Free,将慢操作异步化,这也是在事件处理上向多线程迈进了一步。
要解决慢操作,可以采用渐进式处理,即增加一个时间事件,比如在删除一个具有上百万个对象的Set键时,每次只删除大键中的一部分数据,最终实现大键的删除。但是,该方案可能会导致回收速度赶不上创建速度,最终导致内存耗尽。因此,Redis最终实现上是将大键的删除操作异步化,采用非阻塞删除(对应命令UNLINK),大键的空间回收交由单独线程实现,主线程只做关系解除,可以快速返回,继续处理其他事件,避免服务器长时间阻塞。
多线程I/O及其局限性
Redis在4.0版本引入了Lazy Free,自此Redis有了一个Lazy Free线程专门用于大键的回收,同时,也去掉了聚合类型的共享对象,这为多线程带来可能,Redis也不负众望,在6.0版本实现了多线程I/O。

多线程IO实现
如上图红色部分,就是Redis实现的多线程部分,利用多核来分担I/O读写负荷。在事件处理线程每次获取到可读事件时,会将所有就绪的读事件分配给I/O线程,并进行等待,在所有I/O线程完成读操作后,事件处理线程开始执行任务处理,在处理结束后,同样将写事件分配给I/O线程,等待所有I/O线程完成写操作。
局限性
从上面实现上看,6.0版本的多线程并非彻底的多线程,I/O线程只能同时执行读或者同时执行写操作,期间事件处理线程一直处于等待状态,并非流水线模型,有很多轮训等待开销。
Tair多线程实现原理
相较于6.0版本的多线程,Tair的多线程实现更加优雅。如下图,Tair的Main Thread负责客户端连接建立等,IO Thread负责请求读取、响应发送、命令解析等,Worker Thread线程专门用于事件处理。IO Thread读取用户的请求并进行解析,之后将解析结果以命令的形式放在队列中发送给Worker Thread处理。Worker Thread将命令处理完成后生成响应,通过另一条队列发送给IO Thread。为了提高线程的并行度,IO Thread和Worker Thread之间采用无锁队列和管道进行数据交换,整体性能会更好。
转:
http://www.zzvips.com/article/28719.html
参考:《Redis设计与实现》
https://www.zhihu.com/question/55818031/answer/2247511664

 浙公网安备 33010602011771号
浙公网安备 33010602011771号