漏洞挖掘中的常见的源码泄露
这几天一直想写点啥,偶然间,逛我们团长 小艾 的博客,我看到一个文章,题目是 " 常见的web 源码泄露漏洞 ",其中记录了好多源码泄露,但是我就见过其中三个,所以就想着总结一份挖洞中常见的源码泄露吧。
小艾那篇文章的地址:http://www.htmlsec.com/?p=50
在记录之前,我为了证明我的想法,我以关键词 ' 源码泄露 ' 在乌云漏洞库刷了一遍案例。
 一共 300 多个,但是说白了还是常见的那几种,我就从多到少的方式开始写。
一共 300 多个,但是说白了还是常见的那几种,我就从多到少的方式开始写。
一,svn 源码泄露
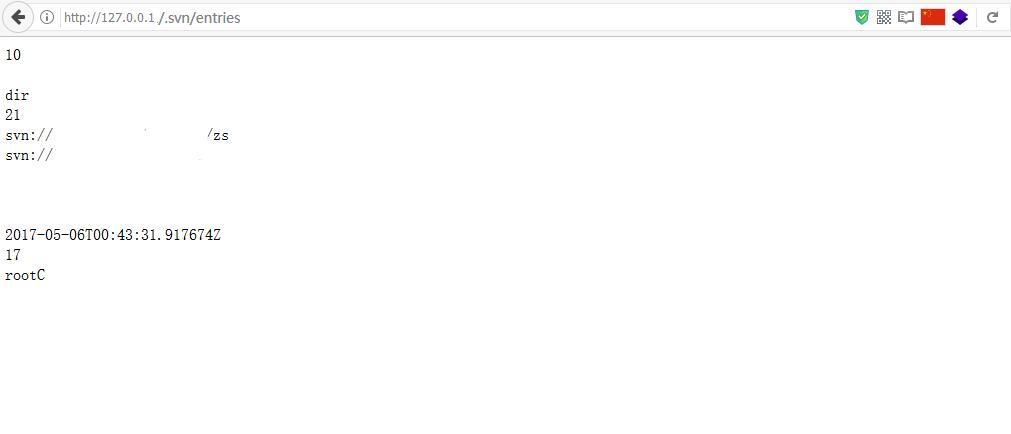
SVN(subversion)是源代码版本管理软件。在使用SVN管理本地代码过程中,会自动生成一个名为.svn的隐藏文件夹,其中包含重要的源代码信息。但一些网站管理员在发布代码时,不愿意使用‘导出’功能,而是直接复制代码文件夹到WEB服务器上,这就使.svn隐藏文件夹被暴露于外网环境,黑客可以借助其中包含的用于版本信息追踪的‘entries’文件,逐步摸清站点结构。
svn 源码泄露示例:
http://127.0.0.1/.svn/entries
1,
 2,
2,
 如果存在以上案例中的情形,说明存在 svn 源码泄露 。
如果存在以上案例中的情形,说明存在 svn 源码泄露 。
svn 源码泄露利用工具:
这个一般都是使用的 'Seay SVN漏洞利用工具' 法师的工具。
链接: http://pan.baidu.com/s/1eSP6lUE 密码: a7b1
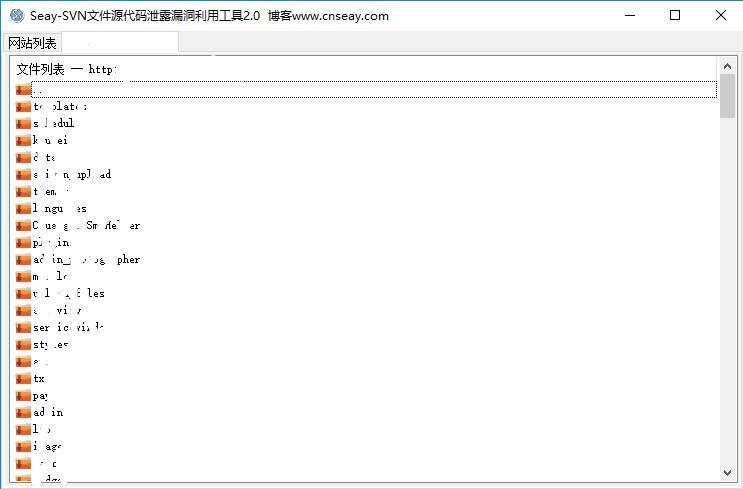
漏洞利用证明截图:
二, 网站源码压缩备份泄露
一般网站管理员在日常维护中,总会把网站源码给备份一下,防止网站出现问题时,能马上的恢复使用,不过一般的管理员安全意识不高,在备份的时候,会使用一些常见的压缩备份名,而且不光使用常见的备份名字,大部分的管理还会把备份好的源码直接放在网站根目录里,这样给一些不法之徒,提供了一个很方便的渗透思路,或者有些直接不需要渗透了,因为备份中的数据,就已经满足那些不法之徒的需求了。
网站源码压缩备份示例:
1,
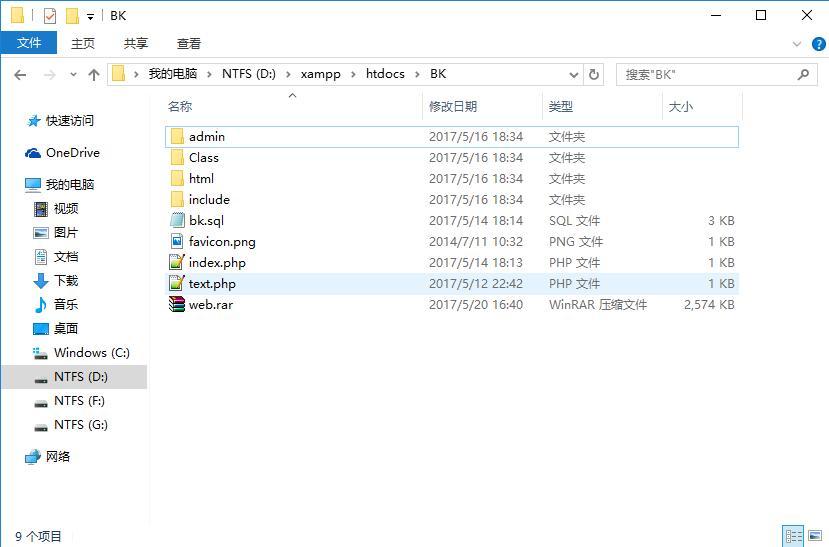 2,
2,
 部分常见的网站源码压缩备份名:
部分常见的网站源码压缩备份名:
0.rar
web.rar
www.rar
wwwroot.rar
back.rar
temp.rar
backup.rar
bbs.zip
website.rar
常用探测源码备份工具:
这个其实不是靠工具的,是靠字典的,工具的话,网上任何能扫目录的工具,都可以用来探测源码备份的,不过常见的还是用的 御剑1.5 ,或者自己写的一些扫目录的小脚本工具。
三, .git 源码泄露
在运行git init初始化代码库的时候,会在当前目录下面产生一个.git的隐藏文件,用来记录代码的变更记录等等。在发布代码的时候,把.git这个目录没有删除,直接发布了。使用这个文件,可以用来恢复源代码。
.git 源码泄露示例:
http://127.0.0.1/.git/config
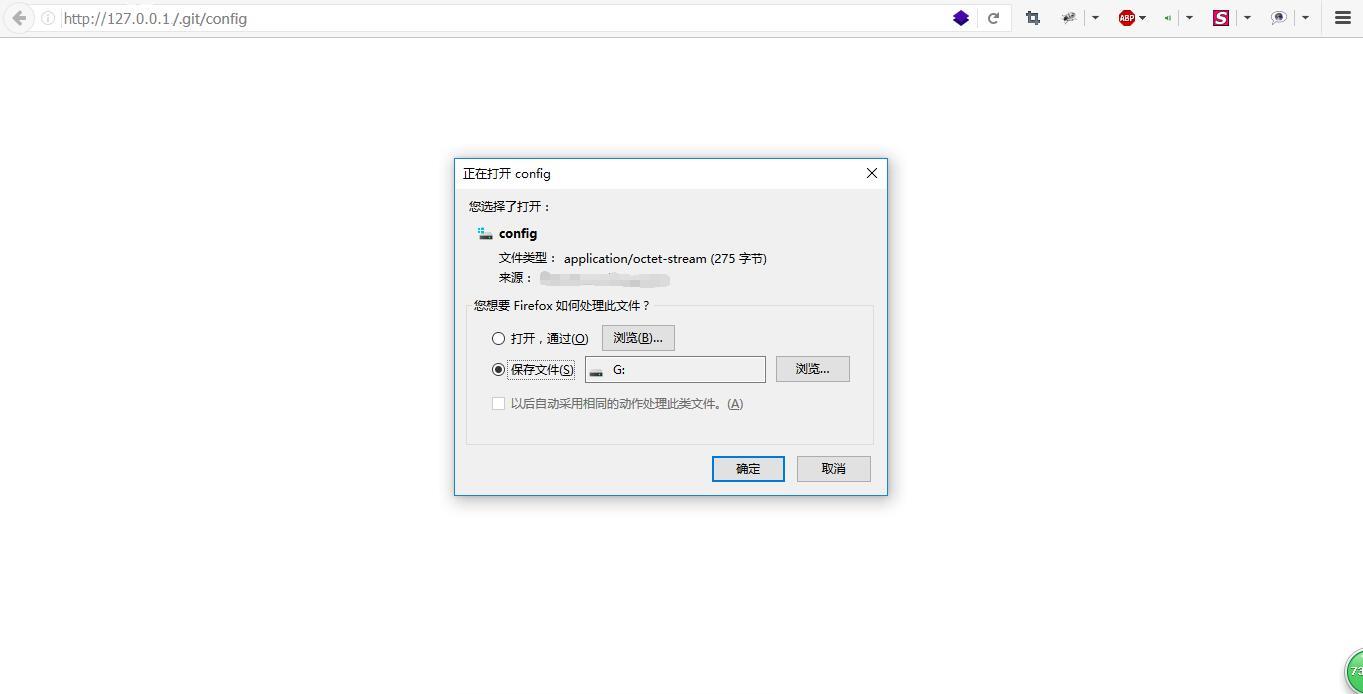 这类案例网站不好站,但是我千找万找,还是找见一个案例。。。
这类案例网站不好站,但是我千找万找,还是找见一个案例。。。
.git 漏洞利用工具:
1, GitHack
GitHack.py http://127.0.0.1/.git/
GitHack 工具使用说明:
GitHack:一个git泄露利用脚本 - FreeBuf.COM | 关注黑客与极客
rip-git.pl -v -u http://127.0.0.1/.git/
暂无使用详细使用说明,推荐使用第一个工具。
四,GitHub 项目源码泄露
github 是全球最大的 那个啥 交流网站,数以百计的大侠,高手,圣手,教主,小白,宗主,等等级别人物的汇集之地,而平台的服务设施,很人性化,而且用户体验度高,所以,用的人很多,而且很人也都喜欢把自己的代码上传到平台,反正是很方便。
有些安全意识不高的程序员大意的把自己的项目源码上传到 GitHub ,一些 不法份子 在收集信息中,通过关键词进行搜索,可以找到关于目标站点的信息,有些信息直接泄露了网站源码,管理员账号密码,数据库信息等。
漏洞示例:

http://www.loner.fm/bugs/searchbug.php?q=github&page=1
----------------------------------------------------------------------------------------------------------------------
总结:
源码泄露,正如一开始我看小艾那个文章,有好多个,但是在实际的漏洞挖掘中,就这不几个常见的,或者说就前三种,剩下的源码泄露的漏洞都是不好找。
-----------------------------------------------------------------------------------------------------------------------
完了吗?肯定不能完啊!主要还是闲的没事,就自己想着自己写一个扫源码泄露的小脚本吧,结果,从一开始远大的抱负,写一个让自己用的脚本,结果越写, bug 越多,,,多到我自己都不会改了。。。
从多线程批量扫描式,删到单线程批量,再继续删到单个网站外接式探测,再继续删到单个网站内接式探测,,,,最后全删完了。。。
恩,然后瞎几把写了一个纯属娱乐的还误报很多的垃圾小脚本。。。
# (幸亏我不是程序员啊!要不然真的成了,钱多,话少,还 ④ 的早的段子了。。。)
# -*- coding:utf-8 -*-
# 导入 request 模块
import requests
# 把需要探测的文件放到这个列表里,并赋值给 mulu
mulu = ['/.git/config', '/.svn/entries', 'web.rar', 'www.rar', 'wwwroot.rar', '1.rar', 'bbs.zip', 'website.rar']
print '- - - - - - - - - - - - - - - - - - - - -' # 没啥用
print u'| 这是一个很娱乐的源码泄露探测脚本 |'# 没啥用
print '- - - - - - - - - - - - - - - - - - - - -' # 没啥用
# 用来输入需要探测的网址
dizhi = raw_input('请输入URL地址:'.decode('utf-8').encode('gbk'))
# 把列表里的元素一个一个遍历出来
for a in mulu:
# 把网址和探测的文件连接到一起
tance = "%s/%s" % (dizhi, a)
# print tance 这一行是我看看到底连接到一起了没的。。。
# 使用 request 模块里的 get 来获取这个网址
qq = requests.get(url=tance)
# 获取响应码并赋值给 dq
dq = qq.status_code
# 判断响应码是否为 200 ,是,就进行下一步
if dq == 200 :
# 输出 响应码和探测地址
print u"响应码:[%s] - 地址:%s" % (dq, tance)
# 如果响应码不是 200 就进行着一步
else:
# 输入响应码和地址
print u"响应码:[%s] - 地址:%s" % (dq, tance)
来,开始玩一玩这个垃圾脚本 (*^__^*) 嘻嘻……
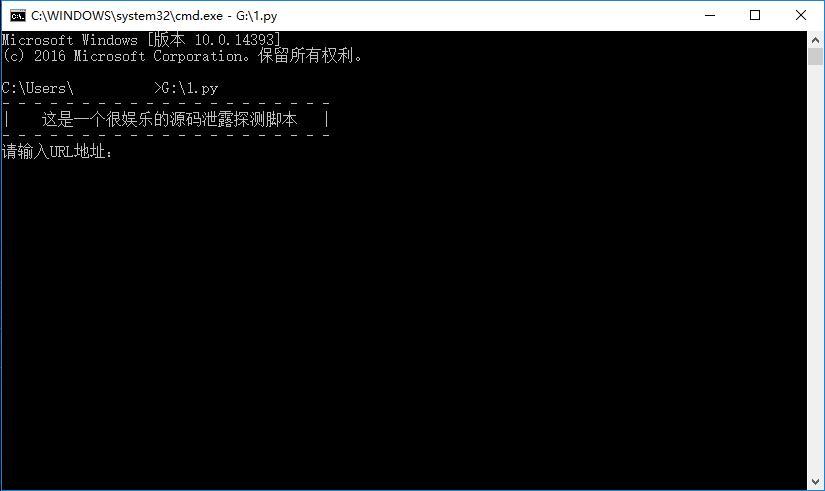 恩,测试测试 离心小姐姐 的博客吧? #(斜眼笑...)
恩,测试测试 离心小姐姐 的博客吧? #(斜眼笑...)
请输入URL地址:http://www.lsafe.org
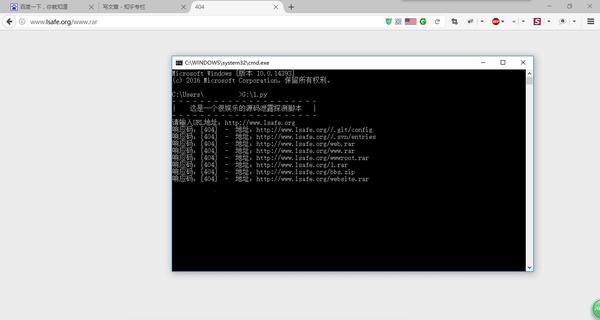 @我是离心 你不会打我把? #( 一脸无辜.GIF )
@我是离心 你不会打我把? #( 一脸无辜.GIF )
完 ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号