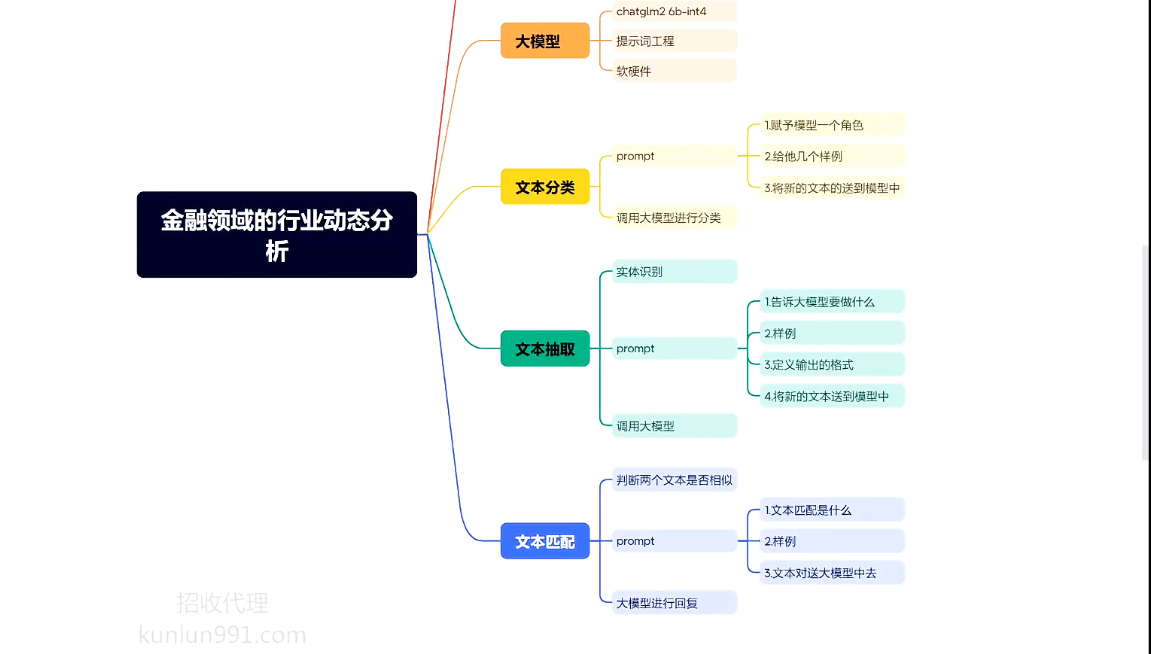
金融行业动态方向实战-文本归类、文本抽取、文本匹配
2025-08-13 20:09 dribs 阅读(80) 评论(0) 收藏 举报文本归类
环境:趋动云
注册薅羊毛连接:https://platform.virtaicloud.com/gemini_web/auth/register?inviteCode=f98509ce3f7da1578a766bde2a41268e
配置信息:
代码示例:
# —*-coding:utf-8-*-
"""
利用 LLM 进行文本分类任务。
"""
from rich import print
from rich.console import Console
from transformers import AutoTokenizer, AutoModel
# 定义init_prompts函数
def init_prompts():
"""
初始化 Prompt,包含类别定义和高质量 few-shot 样例
"""
# 类别定义
class_definitions = {
'新闻报道': '来自媒体或官方新闻发布的报道事件,强调时间性和新闻价值。',
'财务报告': '企业发布的年度、季度财务数据说明,包含收入、利润、负债等数据。',
'公司公告': '企业向公众或股东发布的重要业务、收购、合作、战略变化等信息。',
'分析师报告': '分析师对市场、行业或公司的分析、预测或投资建议。'
}
# 每类示例(越贴近你的真实任务越好)
class_examples = {
'新闻报道': [
'央行今日宣布下调存款准备金率50个基点。',
'全球股市因美联储加息预期波动加剧。',
'新华社报道,国际油价创近半年新高。'
],
'财务报告': [
'本公司2024年度财务报告显示净利润增长15%。',
'第一季度资产负债表显示现金流充足。',
'公司上半年营业收入达到120亿元,同比增长8%。'
],
'公司公告': [
'本公司宣布收购一家人工智能初创公司。',
'董事会批准发行新的公司债券。',
'公司决定更换首席执行官,自下月起生效。'
],
'分析师报告': [
'分析师预计新能源车销量将在未来两年翻倍。',
'行业分析指出,云计算市场将保持年均20%的增长率。',
'券商研报建议买入该公司股票,目标价上调至45元。'
]
}
class_list = list(class_definitions.keys())
# 系统指令 + 类别定义
system_prompt = "你是一个专业的金融领域文本分类器。\n类别定义:\n"
for c, d in class_definitions.items():
system_prompt += f"- {c}:{d}\n"
system_prompt += "请严格按照定义分类,只能从上述类别中选择一个,并且按以下JSON格式输出:{\"类别\": \"<类别名>\"}"
# 构造 few-shot 历史对话
pre_history = [
(system_prompt, "明白")
]
for _type, examples in class_examples.items():
for e in examples:
pre_history.append((f'"{e}"属于哪个类别?', f'{{"类别": "{_type}"}}'))
return {"class_list": class_list, "pre_history": pre_history}
def inference(sentences: list,
custom_settings: dict):
"""
推理函数。
Args:
sentences (List[str]): 待推理的句子。
custom_settings (dict): 初始设定,包含人为给定的 few-shot example。
"""
for sentence in sentences:
with console.status("[bold bright_green] Model Inference..."):
sentence_prompt = f'"{sentence}"是{custom_settings["class_list"]}里的什么类别?'
response, history = model.chat(tokenizer, sentence_prompt, history=custom_settings['pre_history'])
print(f'>>>[bold bright_red]sentence:{sentence}')
print(f'>>>[bold bright_green]inference answer:{response}')
print(f'history-->{history}')
print("*" * 80)
if __name__ == '__main__':
console = Console()
device = 'cuda:0'
# device = 'cpu'
tokenizer = AutoTokenizer.from_pretrained(r"../pretrain/model/chatglm2-6b-int4/", trust_remote_code=True)
model = AutoModel.from_pretrained(r"../pretrain/model/chatglm2-6b-int4/", trust_remote_code=True).half().cuda()
model = model.eval()
# model = AutoModel.from_pretrained("../03-weights/chatglm2-6b-int4",trust_remote_code=True).float()
# model.to(device)
# sentences = [
# "今日,央行发布公告宣布降低利率,以刺激经济增长。这一降息举措将影响贷款利率,并在未来几个季度内对金融市场产生影响。",
# "ABC公司今日发布公告称,已成功完成对XYZ公司股权的收购交易。本次交易是ABC公司在扩大业务范围、加强市场竞争力方面的重要举措。据悉,此次收购将进一步巩固ABC公司在行业中的地位,并为未来业务发展提供更广阔的发展空间。详情请见公司官方网站公告栏",
# "公司资产负债表显示,公司偿债能力强劲,现金流充足,为未来投资和扩张提供了坚实的财务基础。",
# "最新的分析报告指出,可再生能源行业预计将在未来几年经历持续增长,投资者应该关注这一领域的投资机会",
# ]
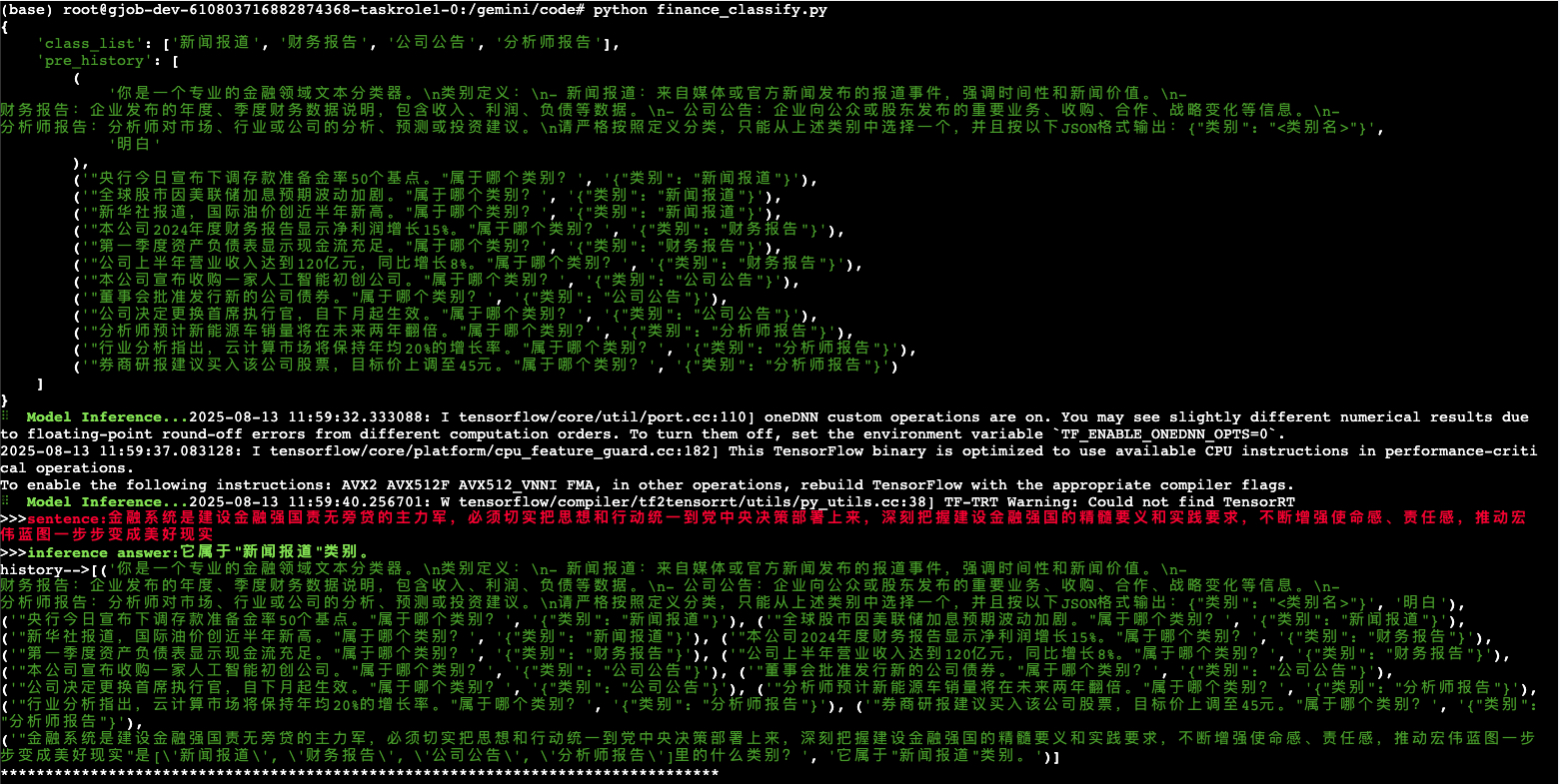
sentences = ["金融系统是建设金融强国责无旁贷的主力军,必须切实把思想和行动统一到党中央决策部署上来,深刻把握建设金融强国的精髓要义和实践要求,不断增强使命感、责任感,推动宏伟蓝图一步步变成美好现实"]
custom_settings = init_prompts()
print(custom_settings)
inference(
sentences,
custom_settings
)
结果输出:
import re
import json
from rich import print
from transformers import AutoTokenizer, AutoModel
# 定义不同实体下的具备属性
schema = {
'金融': ['日期', '股票名称', '开盘价', '收盘价', '成交量'],
}
# 信息抽取的模版
IE_PATTERN = "{}\n\n提取上述句子中{}的实体,并按照JSON格式输出,上述句子中不存在的信息用['原文中未提及']来表示,多个值之间用','分隔。"
# 提供一些例子供模型参考
ie_examples = {
'金融': [
{
'content': '2023-01-10,股市震荡。股票古哥-D[EOOE]美股今日开盘价100美元,一度飙升至105美元,随后回落至98美元,最终以102美元收盘,成交量达到520000。',
'answers': {
'日期': ['2023-01-10'],
'股票名称': ['古哥-D[EOOE]美股'],
'开盘价': ['100美元'],
'收盘价': ['102美元'],
'成交量': ['520000'],
}
}
]
}
# 定义init_prompts函数
def init_prompts():
"""
初始化前置prompt,便于模型做 incontext learning。
"""
ie_pre_history = [
(
"现在你需要帮助我完成信息抽取任务,当我给你一个句子时,你需要帮我抽取出句子中实体信息,并按照JSON的格式输出,上述句子中没有的信息用['原文中未提及']来表示,多个值之间用','分隔。",
'好的,请输入您的句子。'
)
]
for _type, example_list in ie_examples.items():
# print(f'_type-->{_type}')
# print(f'example_list-->{example_list}')
# print(f'*'*80)
for example in example_list:
sentence = example["content"]
properties_str = ', '.join(schema[_type])
# print(f'properties_str-->{properties_str}')
schema_str_list = f'"{_type}"({properties_str})'
# print(f'schema_str_list-->{schema_str_list}')
sentence_with_prompt = IE_PATTERN.format(sentence, schema_str_list)
# print(f'sentence_with_prompt-->{sentence_with_prompt}')
ie_pre_history.append((f"{sentence_with_prompt}",f"{json.dumps(example['answers'], ensure_ascii=False)}"))
# print(f'ie_pre_history-->{ie_pre_history}')
return {"ie_pre_history":ie_pre_history}
def clean_response(response: str):
"""
后处理模型输出。
Args:
response (str): _description_
"""
if '```json' in response:
res = re.findall(r'```json(.*?)```', response)
if len(res) and res[0]:
response = res[0]
response = response.replace('、', ',')
try:
return json.loads(response)
except:
return response
def inference(sentences: list,
custom_settings: dict):
"""
推理函数。
Args:
sentences (List[str]): 待抽取的句子。
custom_settings (dict): 初始设定,包含人为给定的 few-shot example。
"""
for sentence in sentences:
cls_res = "金融"
if cls_res not in schema:
print(f'The type model inferenced {cls_res} which is not in schema dict, exited.')
exit()
properties_str = ', '.join(schema[cls_res])
schema_str_list = f'"{cls_res}"({properties_str})'
sentence_with_ie_prompt = IE_PATTERN.format(sentence, schema_str_list)
# print(f'sentence_with_prompt-->{sentence_with_ie_prompt}')
ie_res, history = model.chat(tokenizer,
sentence_with_ie_prompt,
history=custom_settings["ie_pre_history"])
ie_res = clean_response(ie_res)
print(f'>>> [bold bright_red]sentence: {sentence}')
print(f'>>> [bold bright_green]inference answer:{ie_res} ')
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained(r"../pretrain/model/chatglm2-6b-int4/", trust_remote_code=True)
model = AutoModel.from_pretrained(r"../pretrain/model/chatglm2-6b-int4/", trust_remote_code=True).half().cuda()
model = model.eval()
# device = 'cpu'
# model = AutoModel.from_pretrained(r"D:\02-weights\chatglm2-6b-int4",
# trust_remote_code=True).float()
# model.to(device)
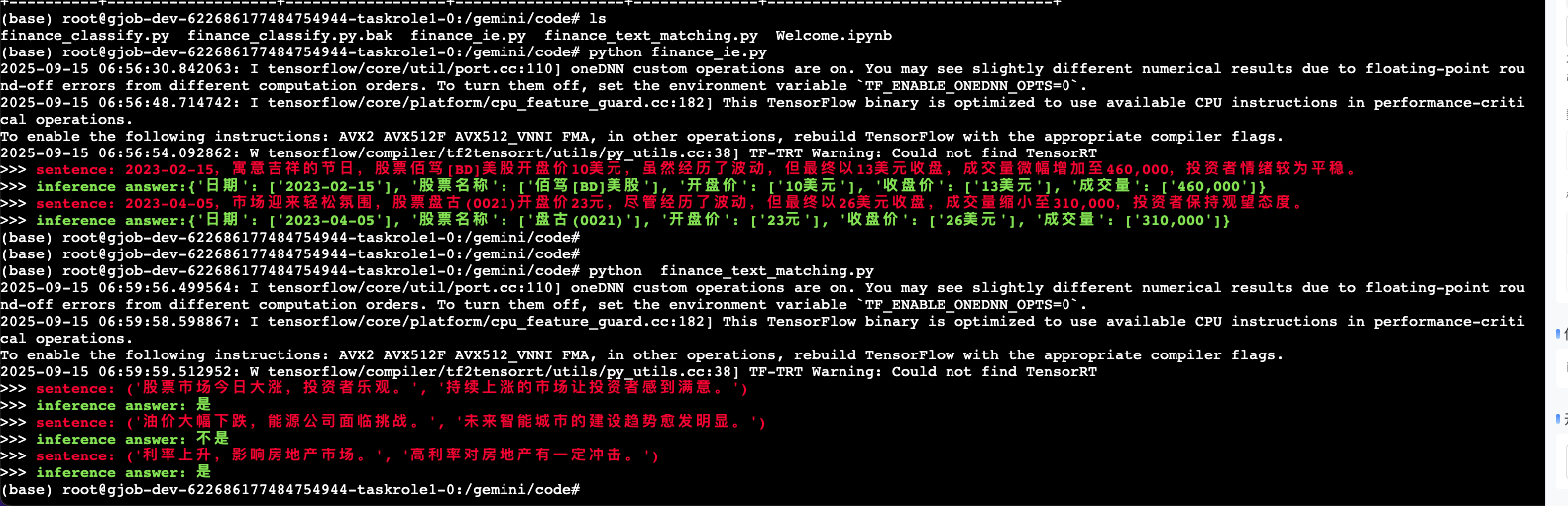
sentences = [
'2023-02-15,寓意吉祥的节日,股票佰笃[BD]美股开盘价10美元,虽然经历了波动,但最终以13美元收盘,成交量微幅增加至460,000,投资者情绪较为平稳。',
'2023-04-05,市场迎来轻松氛围,股票盘古(0021)开盘价23元,尽管经历了波动,但最终以26美元收盘,成交量缩小至310,000,投资者保持观望态度。',
]
custom_settings = init_prompts()
inference(
sentences,
custom_settings
)
from rich import print
from transformers import AutoTokenizer, AutoModel
# 提供相似,不相似的语义匹配例子
examples = {
'是': [
('公司ABC发布了季度财报,显示盈利增长。', '财报披露,公司ABC利润上升。'),
],
'不是': [
('黄金价格下跌,投资者抛售。', '外汇市场交易额创下新高。'),
('央行降息,刺激经济增长。', '新能源技术的创新。')
]
}
def init_prompts():
"""
初始化前置prompt,便于模型做 incontext learning。
"""
pre_history = [
(
'现在你需要帮助我完成文本匹配任务,当我给你两个句子时,你需要回答我这两句话语义是否相似。只需要回答是否相似,不要做多余的回答。',
'好的,我将只回答”是“或”不是“。'
)
]
for key, sentence_pairs in examples.items():
# print(f'key-->{key}')
# print(f'sentence_pairs-->{sentence_pairs}')
for sentence_pair in sentence_pairs:
sentence1, sentence2 = sentence_pair
# print(f'sentence1-->{sentence1}')
# print(f'sentence2-->{sentence2}')
pre_history.append((f'句子一:{sentence1}\n句子二:{sentence2}\n上面两句话是相似的语义吗?',
key))
return {"pre_history": pre_history}
def inference(
sentence_pairs: list,
custom_settings: dict
):
"""
推理函数。
Args:
model (transformers.AutoModel): Language Model 模型。
sentence_pairs (List[str]): 待推理的句子对。
custom_settings (dict): 初始设定,包含人为给定的 few-shot example。
"""
for sentence_pair in sentence_pairs:
sentence1, sentence2 = sentence_pair
sentence_with_prompt = f'句子一: {sentence1}\n句子二: {sentence2}\n上面两句话是相似的语义吗?'
response, history = model.chat(tokenizer, sentence_with_prompt, history=custom_settings['pre_history'])
print(f'>>> [bold bright_red]sentence: {sentence_pair}')
print(f'>>> [bold bright_green]inference answer: {response}')
# print(history)
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained(r"../pretrain/model/chatglm2-6b-int4/", trust_remote_code=True)
model = AutoModel.from_pretrained(r"../pretrain/model/chatglm2-6b-int4/", trust_remote_code=True).half().cuda()
model = model.eval()
# device = 'cpu'
# model = AutoModel.from_pretrained(r"D:\02-weights\chatglm2-6b-int4",
# trust_remote_code=True).float()
# model.to(device)
sentence_pairs = [
('股票市场今日大涨,投资者乐观。', '持续上涨的市场让投资者感到满意。'),
('油价大幅下跌,能源公司面临挑战。', '未来智能城市的建设趋势愈发明显。'),
('利率上升,影响房地产市场。', '高利率对房地产有一定冲击。'),
]
custom_settings = init_prompts()
inference(
sentence_pairs,
custom_settings
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号