


CentOS7.9部署vLLM,运行DeepSeek大模型
前提:已成功安装Nvidia显卡驱动
1、安装openssl 1.1.1
mkdir /usr/local/openssl cd /softwares/openssl-1.1.1n ./config --prefix=/usr/local/openssl make && make install ln -s /usr/local/openssl/lib/libssl.so.1.1 /usr/lib64/libssl.so.1.1 ln -s /usr/local/openssl/lib/libcrypto.so.1.1 /usr/lib64/libcrypto.so.1.1 mv /usr/bin/openssl /usr/bin/openssl.old ln -sv /usr/local/openssl/bin/openssl /usr/bin/openssl vim ~/.bash_profile,文件结尾添加如下内容 export PATH=/usr/local/openssl/bin:$PATH export LD_LIBRARY_PATH=/usr/local/openssl/lib 保存后运行source ~/.bash_profile openssl version #查看openssl版本
2、安装bison
yum -y install bison #安装glibc2.28需要
3、升级make到v4版本
wget http://ftp.gnu.org/gnu/make/make-4.3.tar.gz tar -xf make-4.3.tar.gz cd make-4.3 ./configure --prefix=/usr/local/make make && make install cd /usr/bin && mv make make.bak ln -sv /usr/local/make/bin/make /usr/bin/make #检查make版本 make --version
4、安装gcc 9.3版本
#访问清华园镜像网站(https://mirrors.tuna.tsinghua.edu.cn/gnu),下载gcc9.3 wget https://mirrors.tuna.tsinghua.edu.cn/gnu/gcc/gcc-9.3.0/gcc-9.3.0.tar.gz #安装gcc的依赖包 yum -y install gcc-c++ bzip2 #解压、编译安装 tar -zxf gcc-9.3.0.tar.gz cd gcc-9.3.0 #下载编译所需要的依赖包 ./contrib/download_prerequisites #编译安装 mkdir /usr/local/gcc930 mkdir build && cd build #指定安装目录 指定支持的开发语言 关闭32位支持(不关闭如果缺相关的库会报错,一般用不到,直接关闭即可) ../configure --prefix=/usr/local/gcc930 --enable-languages=c,c++,go --disable-multilib make -j32 make install #查看gcc、g++版本 /usr/local/gcc930/bin/gcc --version /usr/local/gcc930/bin/g++ --version #建立gcc新版本软链接 mv /usr/bin/gcc /usr/bin/gcc485 mv /usr/bin/g++ /usr/bin/g++485 ln -s /usr/local/gcc930/bin/gcc /usr/bin/gcc ln -s /usr/local/gcc930/bin/g++ /usr/bin/g++ #查看gcc、g++版本: gcc --version g++ --version #添加LD_LIBRARY_PATH环境变量 vim ~/.bash_profile ,添加以下内容: export LD_LIBRARY_PATH=/usr/local/gcc-9.3.0/lib source ~/.bash_profile
5、安装glibc-2.28
wget http://ftp.gnu.org/gnu/glibc/glibc-2.28.tar.gz tar -xf glibc-2.28.tar.gz cd glibc-2.28 && mkdir build && cd build ../configure --prefix=/usr --disable-profile --enable-add-ons --with-headers=/usr/include --with-binutils=/usr/bin --disable-werror #make报错的话,加上 --disable-werror参数即可解决。 make && make install#最后的error信息可忽略 #验证glibc-2.28是否安装成功 strings /lib64/libc.so.6 |grep GLIBC |more #或 ldd --version
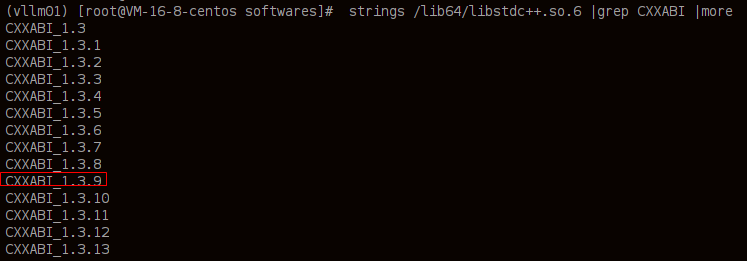
#通过以下命令查看是否包含CXXABI_1.3.9,没有的话则对 /lib64/libstdc++.so.6 进行替换
strings /lib64/libstdc++.so.6 |grep CXXABI |more mv /lib64/libstdc++.so.6 /lib64/libstdc++.so.6.bak
cp /usr/local/gcc930/lib64/libstdc++.so.6 /lib64/ #将gcc930下的文件拷贝过去
6、安装Python3.10
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel #gcc make cd /softwares/Python-3.10.0 mkdir /usr/local/python310 ./configure --with-openssl=/usr/local/openssl/ --prefix=/usr/local/python310/ --with-system-ffi make make install make clean #删除源码包 #配置环境变量: vim ~/.bash_profile #添加如下内容: export PYTHON_HOME=/usr/local/python310 export PATH=$PYTHON_HOME/bin:$PATH #保存后生效: source ~/.bash_profile
7、在Python下创建虚拟环境安装torch、vllm
#新建虚拟环境,安装pip包 mkdir /pyenv cd /pyenv python3 -m venv vllm03 source vllm03/bin/activate
8、安装Pytorch
pip3 install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu121 #通过指定目录安装 pip3 install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --no-index --find-links=/data/softwares/pip_packages/torch-2.5.1+cu121 #如果直接指定安装目录为vllm-0.7.3,则安装后的torch是2.5.1版本,不是2.5.1+cu121,import torch会报错
安装完成后,进入python3命令行下,测试Torch及CUDA可用性:
import torch import torchvision #import numpy #显示torch版本 print(torch.__version__) #显示torchvision版本 print(torchvision.__version__) #显示显卡算力cuda的兼容性,输出结果为7.5 print(torch.cuda.get_device_capability()) #显示cuda是否可用,返回True print(torch.cuda.is_available()) #显示GPU名称 print(torch.cuda.get_device_name(0)) #查看torch所在位置 python3 -c "import torch; print(torch.__file__)"
安装xformers==0.0.28.post3
#从本地离线安装xformers pip3 install xformers==0.0.28.post3 --no-index --find-links=/data/softwares/pip_packages/xformers-0.0.28.post3 #查看xformers是否安装成功 python3 -m xformers.info #不能出现warning才算安装成功。如果未安装glibc2.28版本,则会出现warning
9、安装vLLM
pip3 install vllm #默认安装版本0.6.3.post1 pip3 install vllm==0.7.3 #该版本支持多模态大模型 #通过本地离线安装vllm pip3 install vllm==0.7.3 --no-index --find-links=/data/softwares/pip_packages/vllm-0.7.3
1、pip3安装xgrammar-0.1.11失败,解决办法:
#拷贝在其他机器上已经安装好的xgrammar-0.1.11包到该机器上
tar -zxf xgrammar-0.1.11.tar.gz
cp -r xgrammar-0.1.11/* /data1/pyenv/vllm01/lib/python3.10/site-packages/
2、pip3安装xformers-0.0.28失败,参考如下:
先按照glibc 2.28,然后再 pip3 install xformers==0.0.28.post3 -i https://pypi.tuna.tsinghua.edu.cn/simple
3、pip3安装pyzmq==26.4.0,指定源可以安装成功
pip3 install pyzmq==26.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
#Shell直接运行,使用默认端口 vllm serve /llm/deepseek/deepSeek-R1-Distill-Qwen-1d5B --enforce-eager --dtype=half #前台运行14b,指定端口,使用2张显卡,指定模型最大长度 vllm serve /data/llm/deepseek/14b --trust-remote-code --enforce-eager --tensor-parallel-size 2 --max-model-len 61360 --port 8000 #后台运行14b,禁用日志请求和日志统计显示 nohup vllm serve /data/llm/deepseek/14b --trust-remote-code --enforce-eager --tensor-parallel-size 2 --max-model-len 61360 --port 8000 --disable-log-requests --disable-log-stats & #运行32b模型,启用量化fp8 vllm serve /data/llm/deepseek/32b --trust-remote-code --enforce-eager --quantization fp8 --port 8000 --tensor-parallel-size 2 --max-model-len 61360 #运行qwq32bawq模型: vllm serve /data/llm/qwq32bawq --trust-remote-code --enforce-eager --tensor-parallel-size 2 #添加api-key认证: vllm serve /data/llm/deepseek/14b --trust-remote-code --enforce-eager --tensor-parallel-size 2 --max-model-len 61360 --port 8000 --api-key 9527
#后台运行,禁止输出
nohup /data/ocr02/bin/vllm serve /data/llm/deepseek/14b --trust-remote-code --enforce-eager --tensor-parallel-size 2 --max-model-len 60000 --port 8000 --disable-log-requests --disable-log-stats --api-key 9527123 >/dev/null 2>&1 &
通过Python运行大模型:
#通过Python运行 python3 -m vllm.entrypoints.openai.api_server --model /llm/deepseek/deepSeek-R1-Distill-Qwen-1d5B/ --dtype=half #model:就是模型的路径 --gpu-memory-utilization:就是gpu显存使用率 --tensor-parallel-size:推理并行卡数 python -m vllm.entrypoints.openai.api_server \ --model /mnt/models/models/Meta-Llama-3-70B-Instruct \ --gpu-memory-utilization 0.7 \ --tensor-parallel-size 6
#查看帮助
python3 -m vllm.entrypoints.openai.api_server --help
11、客户端访问大模型:
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/llm/deepseek/deepSeek-R1-Distill-Qwen-1d5B", "max_tokens":6, "messages": [ { "role": "user", "content": "你是谁?" } ] }'
curl http://192.168.192.66:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/llm/deepseek/deepSeek-R1-Distill-Qwen-1d5B", "max_tokens":150, "temperature":0.7, "prompt":"请告诉我元宇宙的起源" }'
通过Python脚本访问api
import requests # 设置API的基本URL api_base_url = "http://localhost:8000/v1" # 准备请求头 headers = { "Content-Type": "application/json", } # 构造请求体 data = { "model": "/llm/deepseek/deepSeek-R1-Distill-Qwen-1d5B", # 确保这里的模型名称与实际部署的一致 "prompt": "请告诉我宇宙的起源是什么?", "max_tokens": 150, "temperature": 0.7, # 控制输出随机性,值越高越随机 } # 发送POST请求 response = requests.post(f"{api_base_url}/completions", headers=headers, json=data) # 检查响应状态码 if response.status_code == 200: # 解析并打印回复 result = response.json() print("Generated Text:", result['choices'][0]['text']) else: print(f"Error: {response.status_code}, Response: {response.text}")
1、vLLM安装完成后,发送post请求的时候,服务端出现报错 “/tmp/tmplh8j__rh/main.c:6:23: 致命错误:stdatomic.h:没有那个文件或目录”
解决办法:原因为gcc版本过低,需要安装gcc9及其以上版本
2、pip3安装包的时候提示错误“pip urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:997)”,解决办法:
下载后手动拷贝到相应目录下
wget https://github.com/vllm-project/vllm-nccl/releases/download/v0.1.0/cu11-libnccl.so.2.18.1 cp libnccl.so.2.18.1 /root/.config/vllm/nccl/cu11/libnccl.so.2.18.1
4、安装NCCL
下载地址:https://developer.nvidia.com/nccl/nccl-legacy-downloads
yum-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.repo yum install libnccl-2.13.4-1+cuda11.7 libnccl-devel-2.13.4-1+cuda11.7 libnccl-static-2.13.4-1+cuda11.7
使用Tesla V100-SXM2-32GB显卡,已通过vllm 0.7.3版本启动deepseek r1 14b大模型,命令如下:
/data/pyenv/vllm01/bin/python3 /data/pyenv/vllm01/bin/vllm serve /data/llm/deepseek/14b --trust-remote-code --enforce-eager --tensor-parallel-size 2 --max-model-len 60000 --port 80 --dtype=half --gpu_memory_utilization 0.8
服务器正常启动后,调用接口进行提问
curl http://127.0.0.1:80/v1/completions -H "Content-Type: application/json" -d '{ "model": "/data/llm/deepseek/14b", "max_tokens":150, "temperature":0.7, "prompt":"请告诉我元宇宙的起源" }'
会出现以下报错
python3: /project/lib/Analysis/Allocation.cpp:47: std::pair<llvm::SmallVector<unsigned int>, llvm::SmallVector<unsigned int> > mlir::triton::getCvtOrder(mlir::Attribute, mlir::Attribute): Assertion `!(srcMmaLayout && dstMmaLayout && !srcMmaLayout.isAmpere()) && "mma -> mma layout conversion is only supported on Ampere"' failed. ERROR 09-09 10:48:30 client.py:301] RuntimeError('Engine process (pid 31669) died.')
原因:
代码(或 vLLM 内部)试图进行 MMA(Matrix Multiply Accumulate)布局之间的转换
Tesla V100 属于 Volta 架构,不支持这种特定的 MMA 布局转换操作,这种转换目前只支持在 NVIDIA Ampere 架构(如 A100、A40、RTX 30xx 系列)上执行。
解决办法:
通过在vllm运行命令中添加参数“--enable-chunked-prefill=False”可解决该问题
/data/pyenv/vllm01/bin/python3 /data/pyenv/vllm01/bin/vllm serve /data/llm/deepseek/14b --trust-remote-code --enforce-eager --tensor-parallel-size 2 --max-model-len 60000 --port 80 --dtype=half --gpu_memory_utilization 0.8 --enable-chunked-prefill=False

 浙公网安备 33010602011771号
浙公网安备 33010602011771号