container start or run + prepareRootfs + linuxStandardInit.Init
https://blog.csdn.net/zhonglinzhang/article/details/101212033
https://blog.csdn.net/zhonglinzhang/article/details/101212033

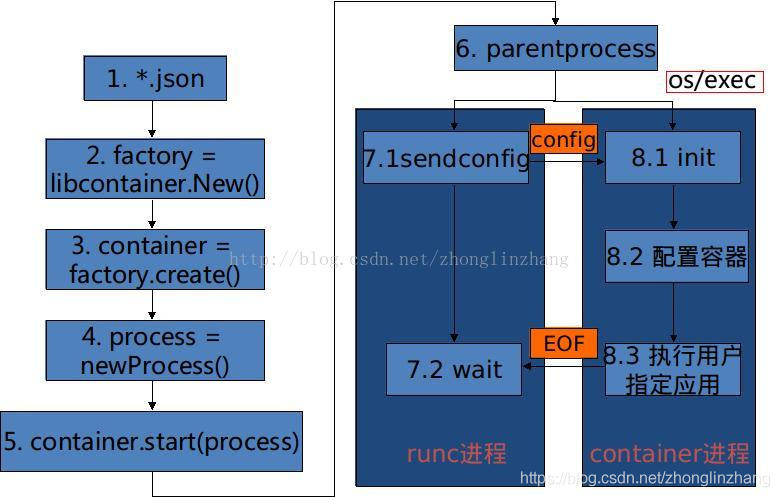
- 在Libcontainer中,p.cmd.Start创建子进程,就进入了pipe wait等待父写入pipe,p.cmd.Start创建了新的Namespace,这时子进程就已经在新的Namespace里了。
- daemon线程在执行p.manager.Apply,创建新的Cgroup,并把子进程放到新的Cgroup中。
- daemon线程做一些网络配置,会把容器的配置信息通过管道发给子进程。同时让子进程继续往下执行。
- daemon线程则进入pipe wait阶段,容器剩下的初始化由子进程完成了。
- rootfs的切换在setupRootfs函数中。(首先子进程会根据config,把host上的相关目录mount到容器的rootfs中,或挂载到一些虚拟文件系统上,这些挂载信息可能是-v指定的volume、容器的Cgroup信息、proc文件系统等)。
- 完成文件系统操作,就执行syscall.PivotRoot把容器的根文件系统切换rootfs
- 再做一些hostname及安全配置,就可以调用syscall.Exec执行容器中的init进程了
- 容器完成创建和运行操作,同时通知了父进程,此时,daemon线程会回到Docker的函数中,执行等待容器进程结束的操作,整个过程完成
Process 对象
Process 主要分为两类,一类在源码中就叫Process,用于容器内进程的配置和 IO 的管理;另一类在源码中叫ParentProcess,负责处理容器启动工作,与 Container 对象直接进行接触,启动完成后作为Process的一部分,执行等待、发信号、获得pid等管理工作。
ParentProcess 对象,主要包含以下六个函数,而根据”需要新建容器”和“在已经存在的容器中执行”的不同方式,具体的实现也有所不同。
-
已有容器中执行命令
- pid(): 启动容器进程后通过管道从容器进程中获得,因为容器已经存在,与Docker Deamon 在不同的 pid namespace 中,从进程所在的 namespace 获得的进程号才有意义。
- start(): 初始化容器中的执行进程。在已有容器中执行命令一般由
docker exec调用,在 execdriver 包中,执行exec时会引入nsenter包,从而调用其中的 C 语言代码,执行nsexec()函数,该函数会读取配置文件,使用setns()加入到相应的 namespace,然后通过clone()在该 namespace 中生成一个子进程,并把子进程通过管道传递出去,使用setns()以后并没有进入 pid namespace,所以还需要通过加上clone()系统调用。- 开始执行进程,首先会运行
C代码,通过管道获得进程 pid,最后等待C代码执行完毕。 - 通过获得的 pid 把 cmd 中的 Process 替换成新生成的子进程。
- 把子进程加入 cgroup 中。
- 通过管道传配置文件给子进程。
- 等待初始化完成或出错返回,结束。
- 开始执行进程,首先会运行
-
新建容器执行命令
- pid():启动容器进程后通过
exec.Cmd自带的pid()函数即可获得。 - start():初始化及执行容器命令。
- 开始运行进程。
- 把进程 pid 加入到 cgroup 中管理。
- 初始化容器网络。(本部分内容丰富,将从本系列的后续文章中深入讲解)
- 通过管道发送配置文件给子进程。
- 等待初始化完成或出错返回,结束。
- pid():启动容器进程后通过
-
实现方式类似的一些函数
- terminate() :发送
SIGKILL信号结束进程。 - startTime() :获取进程的启动时间。
- signal():发送信号给进程。
- wait():等待程序执行结束,返回结束的程序状态。
- terminate() :发送
Process 对象,主要描述了容器内进程的配置以及 IO。包括参数Args,环境变量Env,用户User(由于 uid、gid 映射),工作目录Cwd,标准输入输出及错误输入,控制终端路径consolePath,容器权限Capabilities以及上述提到的 ParentProcess 对象ops(拥有上面的一些操作函数,可以直接管理进程)。
// New returns a linux based container factory based in the root directory and // configures the factory with the provided option funcs. func New(root string, options ...func(*LinuxFactory) error) (Factory, error) { if root != "" { if err := os.MkdirAll(root, 0700); err != nil { return nil, newGenericError(err, SystemError) } } l := &LinuxFactory{ Root: root, InitPath: "/proc/self/exe", InitArgs: []string{os.Args[0], "init"}, Validator: validate.New(), CriuPath: "criu", } Cgroupfs(l) for _, opt := range options { if opt == nil { continue } if err := opt(l); err != nil { return nil, err } } return l, nil }
func (l *LinuxFactory) Create(id string, config *configs.Config) (Container, error) { if l.Root == "" { return nil, newGenericError(fmt.Errorf("invalid root"), ConfigInvalid) } if err := l.validateID(id); err != nil { return nil, err } if err := l.Validator.Validate(config); err != nil { return nil, newGenericError(err, ConfigInvalid) } containerRoot, err := securejoin.SecureJoin(l.Root, id) if err != nil { return nil, err } if _, err := os.Stat(containerRoot); err == nil { return nil, newGenericError(fmt.Errorf("container with id exists: %v", id), IdInUse) } else if !os.IsNotExist(err) { return nil, newGenericError(err, SystemError) } if err := os.MkdirAll(containerRoot, 0711); err != nil { return nil, newGenericError(err, SystemError) } if err := os.Chown(containerRoot, unix.Geteuid(), unix.Getegid()); err != nil { return nil, newGenericError(err, SystemError) } c := &linuxContainer{ id: id, root: containerRoot, config: config, initPath: l.InitPath, initArgs: l.InitArgs, criuPath: l.CriuPath, newuidmapPath: l.NewuidmapPath, newgidmapPath: l.NewgidmapPath, cgroupManager: l.NewCgroupsManager(config.Cgroups, nil), } if intelrdt.IsCatEnabled() || intelrdt.IsMbaEnabled() { c.intelRdtManager = l.NewIntelRdtManager(config, id, "") } c.state = &stoppedState{c: c} return c, nil }
libcontainer.New(containerPath, libcontainer.Cgroupfs) + factory.Create
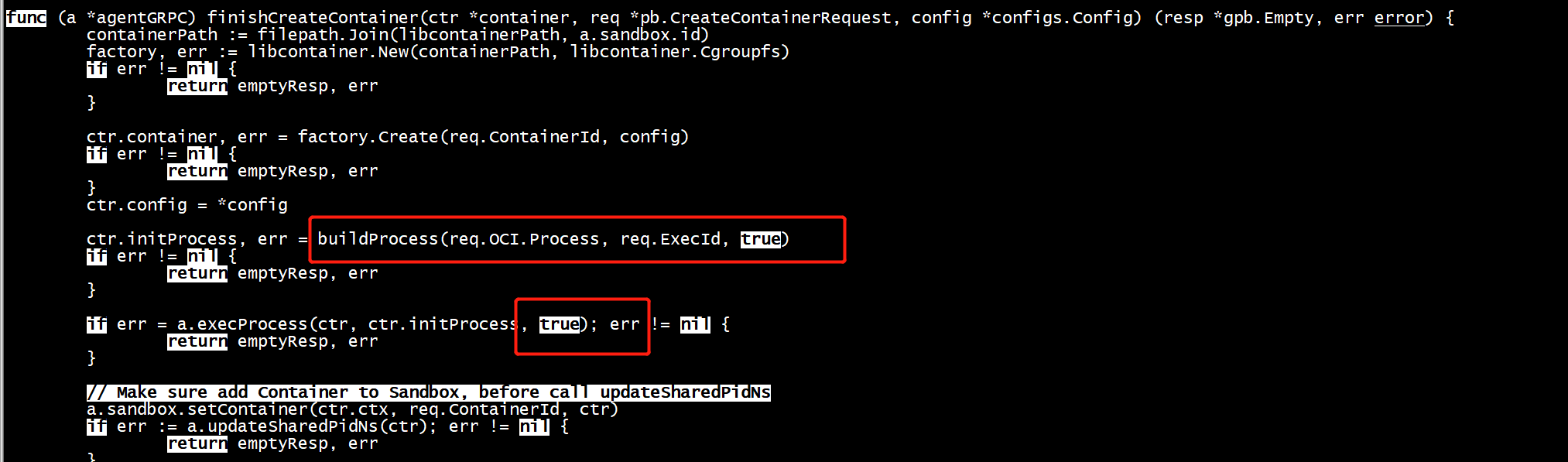
func (a *agentGRPC) finishCreateContainer(ctr *container, req *pb.CreateContainerRequest, config *configs.Config) (resp *gpb.Empty, err error) { containerPath := filepath.Join(libcontainerPath, a.sandbox.id) factory, err := libcontainer.New(containerPath, libcontainer.Cgroupfs) ---------- if err != nil { return emptyResp, err } ctr.container, err = factory.Create(req.ContainerId, config)
func (l *LinuxFactory) Create(id string, config *configs.Config) (Container, error) { if l.Root == "" { return nil, newGenericError(fmt.Errorf("invalid root"), ConfigInvalid) } if err := l.validateID(id); err != nil { return nil, err } if err := l.Validator.Validate(config); err != nil { return nil, newGenericError(err, ConfigInvalid) } containerRoot, err := securejoin.SecureJoin(l.Root, id) if err != nil { return nil, err } if _, err := os.Stat(containerRoot); err == nil { return nil, newGenericError(fmt.Errorf("container with id exists: %v", id), IdInUse) } else if !os.IsNotExist(err) { return nil, newGenericError(err, SystemError) } if err := os.MkdirAll(containerRoot, 0711); err != nil { return nil, newGenericError(err, SystemError) } if err := os.Chown(containerRoot, unix.Geteuid(), unix.Getegid()); err != nil { return nil, newGenericError(err, SystemError) } c := &linuxContainer{ id: id, root: containerRoot, config: config, initPath: l.InitPath, initArgs: l.InitArgs, criuPath: l.CriuPath, newuidmapPath: l.NewuidmapPath, newgidmapPath: l.NewgidmapPath, cgroupManager: l.NewCgroupsManager(config.Cgroups, nil), } if intelrdt.IsCatEnabled() || intelrdt.IsMbaEnabled() { c.intelRdtManager = l.NewIntelRdtManager(config, id, "") } c.state = &stoppedState{c: c} return c, nil }
func (a *agentGRPC) ExecProcess(ctx context.Context, req *pb.ExecProcessRequest) (*gpb.Empty, error) { ctr, err := a.getContainer(req.ContainerId) if err != nil { return emptyResp, err } status, err := ctr.container.Status() if err != nil { return nil, err } if status == libcontainer.Stopped { return nil, grpcStatus.Errorf(codes.FailedPrecondition, "Cannot exec in stopped container %s", req.ContainerId) } proc, err := buildProcess(req.Process, req.ExecId, false) if err != nil { return emptyResp, err } if err := a.execProcess(ctr, proc, false); err != nil { return emptyResp, err } return emptyResp, a.postExecProcess(ctr, proc) }
// Shared function between CreateContainer and ExecProcess, because those expect // a process to be run. func (a *agentGRPC) execProcess(ctr *container, proc *process, createContainer bool) (err error) { if ctr == nil { return grpcStatus.Error(codes.InvalidArgument, "Container cannot be nil") } if proc == nil { return grpcStatus.Error(codes.InvalidArgument, "Process cannot be nil") } // This lock is very important to avoid any race with reaper.reap(). // Indeed, if we don't lock this here, we could potentially get the // SIGCHLD signal before the channel has been created, meaning we will // miss the opportunity to get the exit code, leading WaitProcess() to // wait forever on the new channel. // This lock has to be taken before we run the new process. a.sandbox.subreaper.lock() defer a.sandbox.subreaper.unlock() if createContainer { err = ctr.container.Start(&proc.process) } else { err = ctr.container.Run(&(proc.process)) } if err != nil { return grpcStatus.Errorf(codes.Internal, "Could not run process: %v", err) } // Get process PID pid, err := proc.process.Pid() if err != nil { return err } proc.exitCodeCh = make(chan int, 1) // Create process channel to allow WaitProcess to wait on it. // This channel is buffered so that reaper.reap() will not // block until WaitProcess listen onto this channel. a.sandbox.subreaper.setExitCodeCh(pid, proc.exitCodeCh) return nil }
func _AgentService_ExecProcess_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc1.UnaryServerInterceptor) (interface{}, error) { in := new(ExecProcessRequest) if err := dec(in); err != nil { return nil, err } if interceptor == nil { return srv.(AgentServiceServer).ExecProcess(ctx, in) } info := &grpc1.UnaryServerInfo{ Server: srv, FullMethod: "/grpc.AgentService/ExecProcess", } handler := func(ctx context.Context, req interface{}) (interface{}, error) { return srv.(AgentServiceServer).ExecProcess(ctx, req.(*ExecProcessRequest)) } return interceptor(ctx, in, info, handler) }
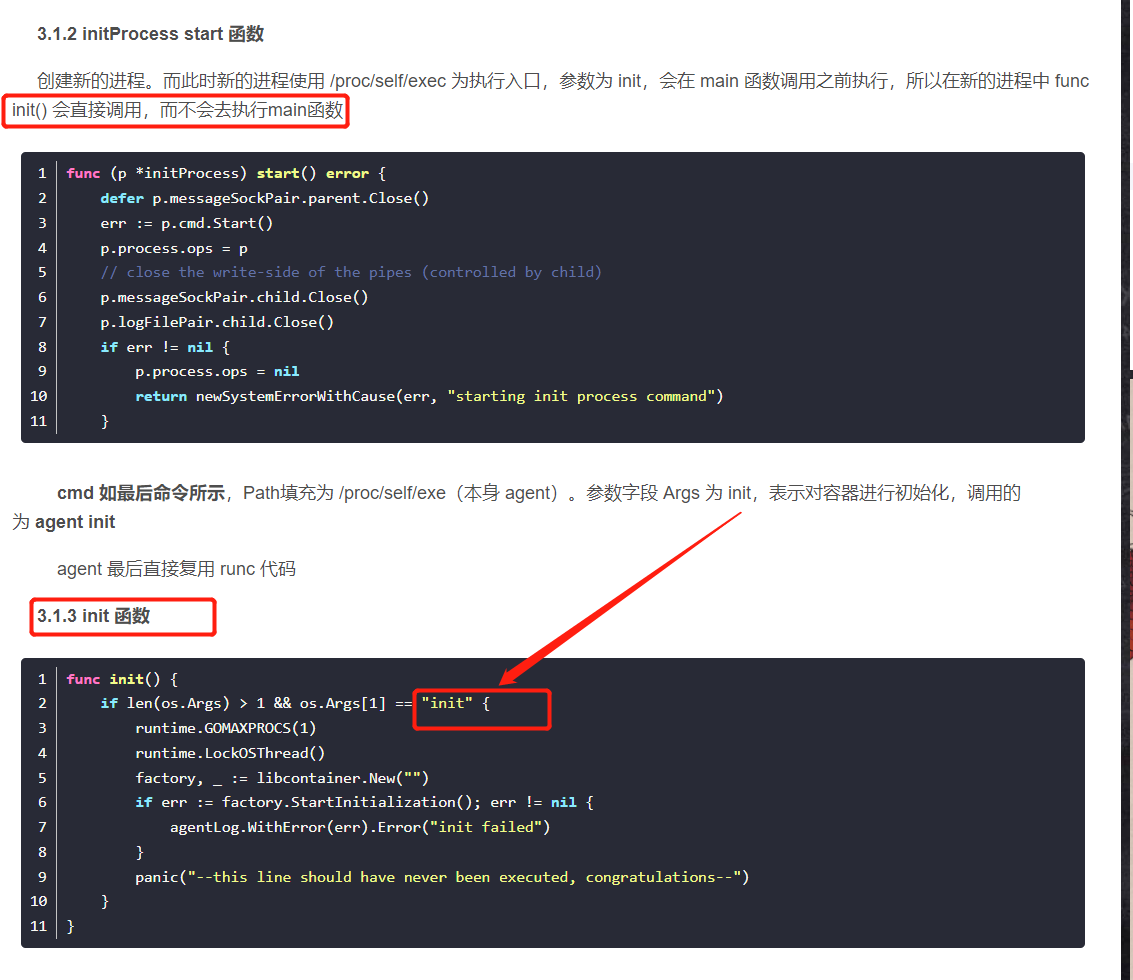
不去调用 (l *LinuxFactory) Create
libcontainer.New("")
agent.go
func init() { if len(os.Args) > 1 && os.Args[1] == "init" { runtime.GOMAXPROCS(1) runtime.LockOSThread() factory, _ := libcontainer.New("") if err := factory.StartInitialization(); err != nil { agentLog.WithError(err).Error("init failed") } panic("--this line should have never been executed, congratulations--") } }
func (a *agentGRPC) execProcess(ctr *container, proc *process, createContainer bool) (err error) { if ctr == nil { return grpcStatus.Error(codes.InvalidArgument, "Container cannot be nil") } if proc == nil { return grpcStatus.Error(codes.InvalidArgument, "Process cannot be nil") } // This lock is very important to avoid any race with reaper.reap(). // Indeed, if we don't lock this here, we could potentially get the // SIGCHLD signal before the channel has been created, meaning we will // miss the opportunity to get the exit code, leading WaitProcess() to // wait forever on the new channel. // This lock has to be taken before we run the new process. a.sandbox.subreaper.lock() defer a.sandbox.subreaper.unlock() if createContainer { err = ctr.container.Start(&proc.process) } else { err = ctr.container.Run(&(proc.process)) } if err != nil { return grpcStatus.Errorf(codes.Internal, "Could not run process: %v", err) } // Get process PID pid, err := proc.process.Pid() if err != nil { return err } proc.exitCodeCh = make(chan int, 1) // Create process channel to allow WaitProcess to wait on it. // This channel is buffered so that reaper.reap() will not // block until WaitProcess listen onto this channel. a.sandbox.subreaper.setExitCodeCh(pid, proc.exitCodeCh) return nil }
vendor/github.com/opencontainers/runc/libcontainer/container_linux.go
func (c *linuxContainer) Start(process *Process) error { c.m.Lock() defer c.m.Unlock() if process.Init { if err := c.createExecFifo(); err != nil { return err } } if err := c.start(process); err != nil { if process.Init { c.deleteExecFifo() } return err } return nil } func (c *linuxContainer) Run(process *Process) error { if err := c.Start(process); err != nil { return err } if process.Init { return c.exec() } return nil }
// mount initializes the console inside the rootfs mounting with the specified mount label // and applying the correct ownership of the console. func mountConsole(slavePath string) error { oldMask := unix.Umask(0000) defer unix.Umask(oldMask) f, err := os.Create("/dev/console") if err != nil && !os.IsExist(err) { return err } if f != nil { f.Close() } return unix.Mount(slavePath, "/dev/console", "bind", unix.MS_BIND, "") }
func mountToRootfs(m *configs.Mount, rootfs, mountLabel string, enableCgroupns bool) error { var ( dest = m.Destination ) if !strings.HasPrefix(dest, rootfs) { dest = filepath.Join(rootfs, dest) } switch m.Device { case "proc", "sysfs": // If the destination already exists and is not a directory, we bail // out This is to avoid mounting through a symlink or similar -- which // has been a "fun" attack scenario in the past. // TODO: This won't be necessary once we switch to libpathrs and we can // stop all of these symlink-exchange attacks. if fi, err := os.Lstat(dest); err != nil { if !os.IsNotExist(err) { return err } } else if fi.Mode()&os.ModeDir == 0 { return fmt.Errorf("filesystem %q must be mounted on ordinary directory", m.Device) } if err := os.MkdirAll(dest, 0755); err != nil { return err } // Selinux kernels do not support labeling of /proc or /sys return mountPropagate(m, rootfs, "") case "mqueue": if err := os.MkdirAll(dest, 0755); err != nil { return err } if err := mountPropagate(m, rootfs, mountLabel); err != nil { // older kernels do not support labeling of /dev/mqueue if err := mountPropagate(m, rootfs, ""); err != nil { return err } return label.SetFileLabel(dest, mountLabel) } return nil case "tmpfs": copyUp := m.Extensions&configs.EXT_COPYUP == configs.EXT_COPYUP tmpDir := "" stat, err := os.Stat(dest) if err != nil { if err := os.MkdirAll(dest, 0755); err != nil { return err } } if copyUp { tmpdir, err := prepareTmp("/tmp") if err != nil { return newSystemErrorWithCause(err, "tmpcopyup: failed to setup tmpdir") } defer cleanupTmp(tmpdir) tmpDir, err = ioutil.TempDir(tmpdir, "runctmpdir") if err != nil { return newSystemErrorWithCause(err, "tmpcopyup: failed to create tmpdir") } defer os.RemoveAll(tmpDir) m.Destination = tmpDir } if err := mountPropagate(m, rootfs, mountLabel); err != nil { return err } if copyUp { if err := fileutils.CopyDirectory(dest, tmpDir); err != nil { errMsg := fmt.Errorf("tmpcopyup: failed to copy %s to %s: %v", dest, tmpDir, err) if err1 := unix.Unmount(tmpDir, unix.MNT_DETACH); err1 != nil { return newSystemErrorWithCausef(err1, "tmpcopyup: %v: failed to unmount", errMsg) } return errMsg } if err := unix.Mount(tmpDir, dest, "", unix.MS_MOVE, ""); err != nil { errMsg := fmt.Errorf("tmpcopyup: failed to move mount %s to %s: %v", tmpDir, dest, err) if err1 := unix.Unmount(tmpDir, unix.MNT_DETACH); err1 != nil { return newSystemErrorWithCausef(err1, "tmpcopyup: %v: failed to unmount", errMsg) } return errMsg } } if stat != nil { if err = os.Chmod(dest, stat.Mode()); err != nil { return err } } return nil case "bind": if err := prepareBindMount(m, rootfs); err != nil { return err } if err := mountPropagate(m, rootfs, mountLabel); err != nil { return err } // bind mount won't change mount options, we need remount to make mount options effective. // first check that we have non-default options required before attempting a remount if m.Flags&^(unix.MS_REC|unix.MS_REMOUNT|unix.MS_BIND) != 0 { // only remount if unique mount options are set if err := remount(m, rootfs); err != nil { return err } } if m.Relabel != "" { if err := label.Validate(m.Relabel); err != nil { return err } shared := label.IsShared(m.Relabel) if err := label.Relabel(m.Source, mountLabel, shared); err != nil { return err } } case "cgroup": if cgroups.IsCgroup2UnifiedMode() { if err := mountCgroupV2(m, rootfs, mountLabel, enableCgroupns); err != nil { return err } } else { if err := mountCgroupV1(m, rootfs, mountLabel, enableCgroupns); err != nil { return err } } if m.Flags&unix.MS_RDONLY != 0 { // remount cgroup root as readonly mcgrouproot := &configs.Mount{ Source: m.Destination, Device: "bind", Destination: m.Destination, Flags: defaultMountFlags | unix.MS_RDONLY | unix.MS_BIND, } if err := remount(mcgrouproot, rootfs); err != nil { return err } } default: // ensure that the destination of the mount is resolved of symlinks at mount time because // any previous mounts can invalidate the next mount's destination. // this can happen when a user specifies mounts within other mounts to cause breakouts or other // evil stuff to try to escape the container's rootfs. var err error if dest, err = securejoin.SecureJoin(rootfs, m.Destination); err != nil { return err } if err := checkProcMount(rootfs, dest, m.Source); err != nil { return err } // update the mount with the correct dest after symlinks are resolved. m.Destination = dest if err := os.MkdirAll(dest, 0755); err != nil { return err } return mountPropagate(m, rootfs, mountLabel) } return nil }
// StartInitialization loads a container by opening the pipe fd from the parent to read the configuration and state // This is a low level implementation detail of the reexec and should not be consumed externally func (l *LinuxFactory) StartInitialization() (err error) { var ( pipefd, fifofd int consoleSocket *os.File envInitPipe = os.Getenv("_LIBCONTAINER_INITPIPE") envFifoFd = os.Getenv("_LIBCONTAINER_FIFOFD") envConsole = os.Getenv("_LIBCONTAINER_CONSOLE") ) // Get the INITPIPE. pipefd, err = strconv.Atoi(envInitPipe) if err != nil { return fmt.Errorf("unable to convert _LIBCONTAINER_INITPIPE=%s to int: %s", envInitPipe, err) } var ( pipe = os.NewFile(uintptr(pipefd), "pipe") it = initType(os.Getenv("_LIBCONTAINER_INITTYPE")) ) defer pipe.Close() // Only init processes have FIFOFD. fifofd = -1 if it == initStandard { if fifofd, err = strconv.Atoi(envFifoFd); err != nil { return fmt.Errorf("unable to convert _LIBCONTAINER_FIFOFD=%s to int: %s", envFifoFd, err) } } if envConsole != "" { console, err := strconv.Atoi(envConsole) if err != nil { return fmt.Errorf("unable to convert _LIBCONTAINER_CONSOLE=%s to int: %s", envConsole, err) } consoleSocket = os.NewFile(uintptr(console), "console-socket") defer consoleSocket.Close() } // clear the current process's environment to clean any libcontainer // specific env vars. os.Clearenv() defer func() { // We have an error during the initialization of the container's init, // send it back to the parent process in the form of an initError. if werr := utils.WriteJSON(pipe, syncT{procError}); werr != nil { fmt.Fprintln(os.Stderr, err) return } if werr := utils.WriteJSON(pipe, newSystemError(err)); werr != nil { fmt.Fprintln(os.Stderr, err) return } }() defer func() { if e := recover(); e != nil { err = fmt.Errorf("panic from initialization: %v, %v", e, string(debug.Stack())) } }() i, err := newContainerInit(it, pipe, consoleSocket, fifofd) if err != nil { return err } // If Init succeeds, syscall.Exec will not return, hence none of the defers will be called. return i.Init() }
func (l *linuxStandardInit) Init() error { runtime.LockOSThread() defer runtime.UnlockOSThread() if !l.config.Config.NoNewKeyring { if err := label.SetKeyLabel(l.config.ProcessLabel); err != nil { return err } defer label.SetKeyLabel("") ringname, keepperms, newperms := l.getSessionRingParams() // Do not inherit the parent's session keyring. if sessKeyId, err := keys.JoinSessionKeyring(ringname); err != nil { // If keyrings aren't supported then it is likely we are on an // older kernel (or inside an LXC container). While we could bail, // the security feature we are using here is best-effort (it only // really provides marginal protection since VFS credentials are // the only significant protection of keyrings). // // TODO(cyphar): Log this so people know what's going on, once we // have proper logging in 'runc init'. if errors.Cause(err) != unix.ENOSYS { return errors.Wrap(err, "join session keyring") } } else { // Make session keyring searcheable. If we've gotten this far we // bail on any error -- we don't want to have a keyring with bad // permissions. if err := keys.ModKeyringPerm(sessKeyId, keepperms, newperms); err != nil { return errors.Wrap(err, "mod keyring permissions") } } } if err := setupNetwork(l.config); err != nil { return err } if err := setupRoute(l.config.Config); err != nil { return err } label.Init() if err := prepareRootfs(l.pipe, l.config); err != nil { return err }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号