iommu_dma_mmap + mmap
https://www.codeleading.com/article/67454397455/
https://blog.csdn.net/weixin_43503508/article/details/107924027
static const struct dma_map_ops iommu_dma_ops = { .alloc = iommu_dma_alloc, .free = iommu_dma_free, .mmap = iommu_dma_mmap, .get_sgtable = iommu_dma_get_sgtable, .map_page = iommu_dma_map_page, .unmap_page = iommu_dma_unmap_page, .map_sg = iommu_dma_map_sg, .unmap_sg = iommu_dma_unmap_sg, .sync_single_for_cpu = iommu_dma_sync_single_for_cpu, .sync_single_for_device = iommu_dma_sync_single_for_device, .sync_sg_for_cpu = iommu_dma_sync_sg_for_cpu, .sync_sg_for_device = iommu_dma_sync_sg_for_device, .map_resource = iommu_dma_map_resource, .unmap_resource = iommu_dma_unmap_resource, .get_merge_boundary = iommu_dma_get_merge_boundary, };
static int iommu_dma_mmap(struct device *dev, struct vm_area_struct *vma, void *cpu_addr, dma_addr_t dma_addr, size_t size, unsigned long attrs) { unsigned long nr_pages = PAGE_ALIGN(size) >> PAGE_SHIFT; unsigned long pfn, off = vma->vm_pgoff; int ret; vma->vm_page_prot = dma_pgprot(dev, vma->vm_page_prot, attrs); if (dma_mmap_from_dev_coherent(dev, vma, cpu_addr, size, &ret)) return ret; if (off >= nr_pages || vma_pages(vma) > nr_pages - off) return -ENXIO; if (IS_ENABLED(CONFIG_DMA_REMAP) && is_vmalloc_addr(cpu_addr)) { struct page **pages = dma_common_find_pages(cpu_addr); if (pages) return __iommu_dma_mmap(pages, size, vma); pfn = vmalloc_to_pfn(cpu_addr); } else { pfn = page_to_pfn(virt_to_page(cpu_addr)); } return remap_pfn_range(vma, vma->vm_start, pfn + off, vma->vm_end - vma->vm_start, vma->vm_page_prot); }
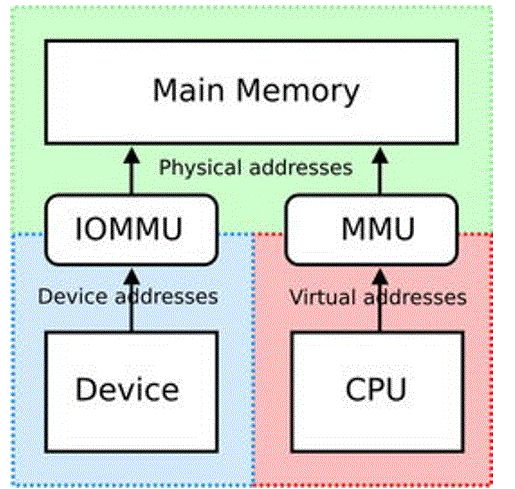
IOMMU核心框架层
IOMMU核心框架是管理IOMMU设备的一个通过框架,IOMMU设备通过实现特定的回调函数并将自身注册到IOMMU核心框架中,以此通过IOMMU核心框架提供的API向整个内核提供IOMMU功能。所有的IOMMU设备都嵌入了一个struct iommu_device,iommu的核心代码只会操作这个结构体。可以看到,我们唯一需要关心的就是ops,这是iommu驱动注册到core中的回调函数。:
struct iommu_device {
struct list_head list;
const struct iommu_ops *ops;
struct fwnode_handle *fwnode;
struct device *dev;
};
/**
* struct iommu_ops - iommu ops and capabilities
* @capable: check capability
* @domain_alloc: allocate iommu domain
* @domain_free: free iommu domain
* @attach_dev: attach device to an iommu domain
* @detach_dev: detach device from an iommu domain
* @map: map a physically contiguous memory region to an iommu domain
* @unmap: unmap a physically contiguous memory region from an iommu domain
* @flush_tlb_all: Synchronously flush all hardware TLBs for this domain
* @tlb_range_add: Add a given iova range to the flush queue for this domain
* @tlb_sync: Flush all queued ranges from the hardware TLBs and empty flush
* queue
* @iova_to_phys: translate iova to physical address
* @add_device: add device to iommu grouping
* @remove_device: remove device from iommu grouping
* @device_group: find iommu group for a particular device
* @domain_get_attr: Query domain attributes
* @domain_set_attr: Change domain attributes
* @get_resv_regions: Request list of reserved regions for a device
* @put_resv_regions: Free list of reserved regions for a device
* @apply_resv_region: Temporary helper call-back for iova reserved ranges
* @domain_window_enable: Configure and enable a particular window for a domain
* @domain_window_disable: Disable a particular window for a domain
* @domain_set_windows: Set the number of windows for a domain
* @domain_get_windows: Return the number of windows for a domain
* @of_xlate: add OF master IDs to iommu grouping
* @pgsize_bitmap: bitmap of all possible supported page sizes
*/
iommu中的核心代码在drivers/iommu/iommu.c中实现,下面从一些基本的方面分析核心层提供的功能。由于一个运行的系统中只会同时存在几个iommu设备,因此设备管理实现比较简单,是由链表实现的。
static LIST_HEAD(iommu_device_list);
static DEFINE_SPINLOCK(iommu_device_lock);
注册和注销设备实质上就是操作这个链表。iommu向外提供的API不多,后面主要分析:
- iommu_map && iommu_unmap
- iommu_domain_alloc && iommu_domain_free
- iommu_attach_device && iommu_detach_device
iommu_domain_alloc
在我的理解中,domain这个词是从intel的VT-d文档中继承下来的,其他平台有各自的叫法如ARM下叫context。一个domain应该是指一个独立的iommu映射上下文。处于同一个domain中的设备使用同一套映射做地址转换(对于mmio来说就是独立的页表)。core层中使用struct iommu_domain表示一个domain:
struct iommu_domain {
unsigned type;
const struct iommu_ops *ops;
unsigned long pgsize_bitmap; /* Bitmap of page sizes in use */
iommu_fault_handler_t handler;
void *handler_token;
struct iommu_domain_geometry geometry;
void *iova_cookie;
};
后面分析各个字段的含义。注释中提到了内核支持的domain类型:
/*
* This are the possible domain-types
*
* IOMMU_DOMAIN_BLOCKED - All DMA is blocked, can be used to isolate
* devices
* IOMMU_DOMAIN_IDENTITY - DMA addresses are system physical addresses
* IOMMU_DOMAIN_UNMANAGED - DMA mappings managed by IOMMU-API user, used
* for VMs
* IOMMU_DOMAIN_DMA - Internally used for DMA-API implementations.
* This flag allows IOMMU drivers to implement
* certain optimizations for these domain
*/
这个函数仅仅就是调用ops中驱动注册的domain_alloc回调函数分配一个iommu_domain,从这里看书每个驱动也是要提供自己的domain类型并把struct iommu_domain嵌入进取的。
iommu_attach_device
int iommu_attach_device(struct iommu_domain *domain, struct device *dev);
从函数原型中可以看出该函数的操作对象是一个domain和一个设备,联想函数名称可以认为该函数是将一个设备添加到一个domain中。但事实上还是有些偏差的,该函数实际上将设备所在的Group与该domain绑定。值得一提的是,如果函数发现设备存在的Group中存在多个设备,则不进行绑定操作。总结下来,该操作针对独立设备(即所在Group里只有自己),将设备所在Group与domain进行绑定。
if (iommu_group_device_count(group) != 1)
goto out_unlock;
ret = __iommu_attach_group(domain, group);
__iommu_attach_group遍历Group中所有的设备,并调用__iommu_attach_device。该函数首先通过domain->ops中的is_attach_deffered检查是否延后进行attach操作。然后调用ops中的attach_dev函数将设备绑定到该domain中去。这里需要注意区分Group中default_domain和domain的概念:domain指group当前所在的domain,而default_domain指Group默认应该在的domain。进行attach操作时,会检查default_domain是否与domain相同,以此判断该Group是否已经attach到别的domain上了,在该情况下返回-EBUSY。
iommu_detach_device
该函数与上面的iommu_attach_device几乎完全相反,并且该函数也是操作独立设备。这里注意如果Group有自己的default_domain,那么该函数在detach完成之后会重新attach到default_domain上。
iommu_map
int iommu_map(struct iommu_domain *domain, unsigned long iova,
phys_addr_t paddr, size_t size, int prot);
函数原型上可以看出来是用于映射domain内的iova,将长度为size以iova为起始地址的iova区域映射到以paddr为起始地址的物理地址。该函数只能用于UNMANAGED类型和DMA类型的domain。domain->pgsize_bitmap是一个bitmap,用于记录domain支持的最小page大小。iommu_map函数进行操作时,是以page为单位的,page大小不固定可以根据需要使用不同大小的page,在同一次iommu_map操作中也不要求page大小一致。最终一个page的映射是调用iommu->ops中的map回调函数实现的。
iommu_iova_to_phys
该函数调用domain->ops中提供的iova_to_phys回调函数将iova转换成物理地址。
TODO dma integration
IOMMU Group
啃了两天PCIE协议,对IOMMU的Group概念也有了一定的理解。从内核角度来看Group是一组设备,是IOMMU可以辨别的最小单位,即IOMMU无法区分出一个Group中的设备。区分标准是什么呢,IO地址空间。以PCIE总线来举一个例子,我们知道PCIE是一个点对点的协议,如果一个多function设备挂到了一个不支持ACS的bridge下,那么这两个function可以通过该bridge进行通信。这样的通信直接由bridge进行转发而无需通过Root Complex,自然也就无需通过IOMMU。这种情况下,这两个function的IOVA无法完全通过IOMMU隔离开,所以他们需要分到同一个Group中。同一个Group的设备应该是公用一个domain的。
struct iommu_group {
struct kobject kobj;
struct kobject *devices_kobj;
struct list_head devices;
struct mutex mutex;
struct blocking_notifier_head notifier;
void *iommu_data;
void (*iommu_data_release)(void *iommu_data);
char *name;
int id;
struct iommu_domain *default_domain;
struct iommu_domain *domain;
};
从iommu_group的结构中可以发现,devices列表保存group中设备。一个group需要关联两个iommu_domain,除此之外支持内核中其他组件向该group中注册listener。default_domain保存的是默认该设备应该位于的domain,而domain字段保存设备当前所在的domain。
iommu_group_add_device
该函数将一个设备加入一个Group,函数的主要操作如下:
- 处理sysfs相关的事项,如建立iommu_group符号链接
- 将设备的iommu_group字段设置为这个Group
- 调用iommu_group_create_direct_mappings建立设备的iova映射
- 将设备加入到Group内的list里
- 通知所有注册到Group里的listener有设备加入
TODO: iommu_group_create_direct_mappings
iommu_group_get_for_dev
该函数获取一个设备所在的Group,如果设备不属于任何一个Group,则调用IOMMU驱动提供的device_group回调函数尝试进行获取。
group = iommu_group_get(dev);
if (group)
return group;
if (!ops)
return ERR_PTR(-EINVAL);
group = ops->device_group(dev);
随后,为获取的Group设置domain,最后将设备加入Group。
if (!group->default_domain) {
struct iommu_domain *dom;
dom = __iommu_domain_alloc(dev->bus, iommu_def_domain_type);
if (!dom && iommu_def_domain_type != IOMMU_DOMAIN_DMA) {
dev_warn(dev,
"failed to allocate default IOMMU domain of type %u; falling back to IOMMU_DOMAIN_DMA",
iommu_def_domain_type);
dom = __iommu_domain_alloc(dev->bus, IOMMU_DOMAIN_DMA);
}
group->default_domain = dom;
if (!group->domain)
group->domain = dom;
}
Bus integration
每一个struct device中保存了一个struct iommu_group的指针,用以获取该设备处于的group。除此之外,内核需要其他方式将iommu功能集成到总线中。很明显,一个iommu设备是作用于一个或者多个总线上的,那么就需要一个自然的方式管理与iommu相关的功能。首先明确struct bus中存在一个iommu_ops用于保存当前bus上生效的iommu驱动注册的iommu_ops。同时可以根据这个指针是否为NULL确认这个bus中是否支持iommu功能。
iommu核心框架中提供了bus_set_iommu函数,该函数可以被iommu驱动调用,用以将自身挂入到 对应总线中。函数中除了设置iommu_ops指针之外,还进行了两个工作:
- 向bus中注册一个listener:对于bus上设备的插入与移除的设备,调用iommu_ops中对应的add_device和remove_device回调函数。对于bus接收到的其他设备事件(如bind,unbind等),则将其传播给该设备所处于的group中。
- 对于bus中已经存在的设备,则挨个调用
add_device将其纳入iommu的管辖,并设置其group
iommu_fwspec
struct iommu_fwspec {
const struct iommu_ops *ops;
struct fwnode_handle *iommu_fwnode;
void *iommu_priv;
unsigned int num_ids;
u32 ids[1];
};
IOMMU Domain
每一个domain即代表一个iommu映射地址空间,即一个page table。一个Group逻辑上是需要与domain进行绑定的,即一个Group中的所有设备都位于一个domain中。
struct iommu_domain {
unsigned type;
const struct iommu_ops *ops;
unsigned long pgsize_bitmap; /* Bitmap of page sizes in use */
iommu_fault_handler_t handler;
void *handler_token;
struct iommu_domain_geometry geometry;
void *iova_cookie;
};
SMMU硬件及驱动分析
看代码要点:
- 一定要看文档,SMMU是一个比较简单的设备,他的Spec只有300页
- fault分为global和context,global基本上就是smmu本身的一些fault,而context是smmu在进行地址转换时出现的fault
开始分析代码,我认为需要从中断处理入手,这也是错误信息的入口。先看context fault的处理函数,代码不贴了基本就是打出相关的寄存器信息,没有什么参考意义。我认为有意义的地方是这个中断是怎么注册的,即驱动是如何管理io domain的。这就涉及通用的IOMMU框架代码了。
可以发现arm_smmu_attach_dev函数中将一个设备添加到一个特定的iommu domain中。函数中调用arm_smmu_init_domain_context函数注册了这个中断。对于每一个struct device,其内部有一个iommu_group字段保存其所在的Group。
static struct iommu_ops arm_smmu_ops = {
.capable = arm_smmu_capable,
.domain_alloc = arm_smmu_domain_alloc,
.domain_free = arm_smmu_domain_free,
.attach_dev = arm_smmu_attach_dev,
.map = arm_smmu_map,
.unmap = arm_smmu_unmap,
.flush_iotlb_all = arm_smmu_iotlb_sync,
.iotlb_sync = arm_smmu_iotlb_sync,
.iova_to_phys = arm_smmu_iova_to_phys,
.add_device = arm_smmu_add_device,
.remove_device = arm_smmu_remove_device,
.device_group = arm_smmu_device_group,
.domain_get_attr = arm_smmu_domain_get_attr,
.domain_set_attr = arm_smmu_domain_set_attr,
.of_xlate = arm_smmu_of_xlate,
.get_resv_regions = arm_smmu_get_resv_regions,
.put_resv_regions = arm_smmu_put_resv_regions,
.pgsize_bitmap = -1UL, /* Restricted during device attach */
};
由于前面已经分析了IOMMU核心框架,熟悉了IOMMU核心框架如何与IOMMU驱动如何互动。这里分析流程即为以一个设备的IOMMU操作周期为基准分析SMMU驱动向IOMMU核心框架注册回调函数。
Stream Mapping管理
首先提及一些Spec中定义的名词:
- Steam翻译成中文是流的意思。在SMMU中特指Master设备向SMMU发起的请求流。StreamID即为SMMU用以辨别不同Stream用的编号,注意Stream和设备不是一一对应的关系。
- Stream Mapping在Spec中特指将StreamID映射到Stream Context(接近domain的概念)这一操作行为。
代码中SME应该是Stream Mapping Entry的缩写。Spec中提及到三种Stream Mapping的方式,这里主要提及Stream Indexing和Stream Matching`两种。
arm_smmu_add_device
这个函数即为add_device回调函数。回忆前面的分析,IOMMU核心框架向bus中注册listener,每当bus中新增设备时,即会调用该函数。从这里看,该函数的主要功能就是将一个设备纳入到IOMMU驱动的管理中。该函数的核心参数就是被传入的struct device结构体中保存的struct iommu_fwspec。
/**
* struct iommu_fwspec - per-device IOMMU instance data
* @ops: ops for this device's IOMMU
* @iommu_fwnode: firmware handle for this device's IOMMU
* @iommu_priv: IOMMU driver private data for this device
* @num_ids: number of associated device IDs
* @ids: IDs which this device may present to the IOMMU
*/
struct iommu_fwspec {
const struct iommu_ops *ops;
struct fwnode_handle *iommu_fwnode;
void *iommu_priv;
unsigned int num_ids;
u32 ids[1];
};
该参数是从ACPI或者设备树中得到的,用以描述设备绑定的IOMMU及拓扑关系。这里需要注意该关系必须遵循硬件设计,不然很明显是无法正常工作的。函数为设备内分配了一个arm_smmu_master_cfg结构体,如下:
struct arm_smmu_master_cfg {
struct arm_smmu_device *smmu;
s16 smendx[];
};
并保存在iommu_fwspec中的iommu_priv指针中。该结构体从名字上就能看出是Master设备的配置,Master这个名词在Spec中是指Bus Master,即可以发起总线请求的设备。函数的核心操作由arm_smmu_master_alloc_smes完成,从名字可以看出是为设备分配Stream Mapping中的表项。对于每一个与设备关联的StreamID,都需要分配一个Stream Mapping中的表项:
ret = arm_smmu_find_sme(smmu, sid, mask);
if (ret < 0)
goto out_err;
idx = ret;
if (smrs && smmu->s2crs[idx].count == 0) {
smrs[idx].id = sid;
smrs[idx].mask = mask;
smrs[idx].valid = true;
}
smmu->s2crs[idx].count++;
cfg->smendx[i] = (s16)idx;
这里的操作简明易懂,唯一需要注意的就是表项的分配方式。首先搜索整个表中是否存在完全匹配(即集合意义上的包含)的表项,如果存在则使用该表项,否则使用表中第一个发现的空表项。到这里可以发现arm_smmu_master_cfg中的smendx即为保存该Master设备对应的Stream Mapping表项。表项申请完毕后,其实质上还是没有写入到SMMU的mmio空间去的,写入的话这个表项应该就生效了。但是软件上还是没有准备完毕的,这个设备没有加入任何Group或者domain。这里可以看到:
group = iommu_group_get_for_dev(dev);
这个函数是IOMMU核心框架提供的函数,函数最终还是会调用到device_group回调函数。这里我们只需要明确这个函数确定设备属于哪一个Group。最后,为了使表项立马生效,将其写入到S2CR寄存器中:
for_each_cfg_sme(fwspec, i, idx) {
arm_smmu_write_sme(smmu, idx);
smmu->s2crs[idx].group = group;
}
arm_smmu_device_group
该函数为device_group回调函数,目的是获取一个设备的Group。函数的操作也比较简单:
- sanity check:检查设备所有SME是否都位于同一个Group
- 如果设备已经有一个Group,那么返回该Group
- 设备没有Group的情况下,则需为设备分配一个Group。对于PCI设备调用
pci_device_group,对于其他设备则为generic_device_group
arm_smmu_domain_alloc
该函数为domain_alloc回调函数,其目的是申请一个domain。SMMU驱动只支持三种domain:
if (type != IOMMU_DOMAIN_UNMANAGED &&
type != IOMMU_DOMAIN_DMA &&
type != IOMMU_DOMAIN_IDENTITY)
return NULL;
剩下的就是申请内存,初始化一些数据结构了,貌似有一些看着比较关键的字段是空着的。后面可以看到这个时候申请的domain仅仅是占位用的,没有什么实际意义。在调用attach_dev时,会初始化domain context。驱动通过struct arm_smmu_domain里的smmu字段判断context是否已经初始化。
arm_smmu_attach_dev
这里的实现细节是,一个设备的绑定的SMMU与其Stream Mappings已经在add_device回调函数中确定好了。attach_dev的实际操作就是根据设备保存的这些信息初始化domain。初始化domain context由arm_smmu_init_domain_context函数完成,该函数满满的硬件细节,后续需要专门讨论。一个domain在SMMU硬件中实际对应的概念就是Context Bank,在使用Stream Matching的情况下,一共存在三层映射:StreamID && Mask -> S2CR寄存器 -> Context Bank。因此,初始化完domain(即Context Bank)后需要设置当前设备在Stream Mapping中对应的S2CR寄存器,使其指向该domain对应的Context Bank。
先说下iommu几个名词
iommu_group:代表共享同一个streamid的一组device,也就是多个device可以在同个group
domain :代表一个具体的设备使用iommu的详细spec
Kernel has DMA mapping API fromorigin. ARM defines IOMMU which can be used to connect scattered physicalmemory as a continuous region for devices which needs continue address towork(e.g: DMA). So IOMMU implementations & CMA should work behind kernelDMA mapping API. E.g: dma_alloc_from_contiguous can be implemented by CMA;dma_alloc_coherent can be implemented by IOMMU or by the normal case(just call__get_free_pages). So for device drivers need dma buffers, we should use dmamapping APIs, not call iommu api directly
说明cma可以实现函数dma_alloc_from_contiguous,iommu可以实现dma_alloc_coherent
iommu是实现在dma mapping api下层的驱动,所以我们只需要使用dma mapping的相关api,不需要直接调用iommu接口。
IOMMU,Input-Output Memory Management Unit
网上有些关于使用iommu的好处。
但是我感觉最终要的是用于将物理上分散的内存页映射成 cif、isp可见的连续内存,如果没有iommu需要在kernel预留比较大的cma内存
在rk芯片,所有模块的iommu公用一个驱动
kernel\drivers\iommu\rockchip-iommu.c
kernel\drivers\iommu\rk-iommu.h
定义iommu的结构:
struct rk_iommu_domain {
struct list_head iommus;
struct platform_device *pdev;
u32 *dt; /* page directory table */
dma_addr_t dt_dma;
struct mutex iommus_lock; /* lock for iommus list */
struct mutex dt_lock; /* lock for modifying page directory table */
struct iommu_domain domain;
};
struct rk_iommu {
struct device *dev;
void __iomem **bases;
int num_mmu;
int *irq;
int num_irq;
bool reset_disabled; /* isp iommu reset operation would failed */
bool skip_read; /* rk3126/rk3128 can't read vop iommu registers */
struct list_head node; /* entry in rk_iommu_domain.iommus */
struct iommu_domain *domain; /* domain to which iommu is attached */
struct clk *aclk; /* aclock belong to master */
struct clk *hclk; /* hclock belong to master */
struct clk *sclk; /* sclock belong to master */
struct list_head dev_node;
};
在模块加载的时候调用
static int __init rk_iommu_init(void)
{
struct device_node *np;
int ret;
np = of_find_matching_node(NULL, rk_iommu_dt_ids);
if (!np)
return 0;
of_node_put(np);
//初始化iommu bus
ret = bus_set_iommu(&platform_bus_type, &rk_iommu_ops);
if (ret)
return ret;
ret = platform_driver_register(&rk_iommu_domain_driver);
if (ret)
return ret;
//注册两个驱动
ret = platform_driver_register(&rk_iommu_driver);
if (ret)
platform_driver_unregister(&rk_iommu_domain_driver);
return ret;
}
其中
bus_set_iommu
iommu_bus_init
err = bus_for_each_dev(bus, NULL, &cb, add_iommu_group);
添加到group后的回调
add_iommu_group
ops->add_device
调用了.add_device = rk_iommu_add_device
两个probe函数
1.rk_iommu_domain_probe
调用
/* Set dma_ops for dev, otherwise it would be dummy_dma_ops */
arch_setup_dma_ops(dev, 0, DMA_BIT_MASK(32), NULL, false);
这样设置dma_ops的操作函数
common_iommu_setup_dma_ops
do_iommu_attach
arch_set_dma_ops(dev, &iommu_dma_ops);
设置dma操作函数为iommu_dma_ops,这里面有使用iommu分配内存
思想是,分配许多页,可能连续,也可能不连续。然后申请iova,最后用iova去匹配物理page,这样就生成了table。(在dts中没有定义关键字,不走买这个过程在后面的do_iommu_attach执行)
2.rockchip_iommu_probe
里面先获取寄存器资源,ioremap过来,获取中断,并申请中断
之后调用
在rockchip-iommu.c里有
static const struct iommu_ops rk_iommu_ops = {
.domain_alloc = rk_iommu_domain_alloc,
.domain_free = rk_iommu_domain_free,
.attach_dev = rk_iommu_attach_device,
.detach_dev = rk_iommu_detach_device,
.map = rk_iommu_map,
.unmap = rk_iommu_unmap,
.map_sg = rk_iommu_map_sg,
.add_device = rk_iommu_add_device,
.remove_device = rk_iommu_remove_device,
.iova_to_phys = rk_iommu_iova_to_phys,
.pgsize_bitmap = RK_IOMMU_PGSIZE_BITMAP,
};
rk_iommu_domain_alloc是初始化rk_iommu_domain结构,返回的是该结构下的iommu_domain结构体。
结合isp驱动看iommu是如何使用的
在dev.c有
if (is_iommu_enable(dev)) {
rkisp1_iommu_init(isp_dev);
}
static int rkisp1_iommu_init(struct rkisp1_device *rkisp1_dev)
{
……//最终会调用到domain_alloc,申请domain
rkisp1_dev->domain = iommu_domain_alloc(&platform_bus_type);//1
……//分配iova_domain结构保存在domain->iova_cookie
iommu_get_dma_cookie(rkisp1_dev->domain);
……//获取group,为了保证多个device绑定iommu不至于混乱
group = iommu_group_get(rkisp1_dev->dev);
……//isp设备绑定domain
ret = iommu_attach_device(domain, dev);//2
……
//设置dma相关操作函数, iommu_dma_ops,以及地址空间,
// iommu_dma_ops应该是在开启iommu的时候,dma相关操作函数就是执行iommu的相关函数,如果没开启,dma应该是其他函数。也就是说dma的对外操作函数是一致的,只是执行到dma函数的时候调用其中的ops是iommu的。这样dma就可以执行分段操作。后续操作dma的时候会调用到iommu的map和ova_to_phys函数
0x10000000:IOVA可映射地址空间的起始位置
SZ_2G:IOVA空间大小
do_iommu_attach调用domain->ops = ops;和arch_set_dma_ops(dev, &iommu_dma_ops);绑定两组ops
if (!common_iommu_setup_dma_ops(dev, 0x10000000, SZ_2G, domain->ops)) {
……
}
1.static struct iommu_domain *rk_iommu_domain_alloc(unsigned type)
{
……//alloc rk_domain结构
rk_domain = devm_kzalloc(&pdev->dev, sizeof(*rk_domain), GFP_KERNEL);
……//申请内存页来保存dt
rk_domain->dt = (u32 *)get_zeroed_page(GFP_KERNEL | GFP_DMA32);
……//dt做dma映射
rk_domain->dt_dma = dma_map_single(iommu_dev, rk_domain->dt, SPAGE_SIZE, DMA_TO_DEVICE);
……//初始化参数,和iommu的ops
rk_domain->domain.geometry.aperture_start = 0;
rk_domain->domain.geometry.aperture_end = DMA_BIT_MASK(32);
rk_domain->domain.geometry.force_aperture = true;
rk_domain->domain.ops = &rk_iommu_ops;
}
- iommu_attach_device 先获取group,然后调用
__iommu_attach_group
iommu_group_do_attach_device
__iommu_attach_device
domain->ops->attach_dev(domain, dev);
这样就跑到.attach_dev = rk_iommu_attach_device
函数里
static int rk_iommu_attach_device(struct iommu_domain *domain,
struct device *dev)
{
……//获取设备iommu
iommu = rk_iommu_from_dev(dev);
……//其实是设置clk
rk_iommu_power_on(iommu);
……//中间是打开stall模式和复位
iommu->domain = domain; //绑定之后
……//申请中断
ret = devm_request_irq(iommu->dev, iommu->irq[i], rk_iommu_irq,
IRQF_SHARED, dev_name(dev), iommu);
……设置mmu的寄存器和mask中断等
for (i = 0; i < iommu->num_mmu; i++) {
rk_iommu_write(iommu->bases[i], RK_MMU_DTE_ADDR,rk_domain->dt_dma);
rk_iommu_base_command(iommu->bases[i], RK_MMU_CMD_ZAP_CACHE);
rk_iommu_write(iommu->bases[i], RK_MMU_INT_MASK, RK_MMU_IRQ_MASK);
}
ret = rk_iommu_enable_paging(iommu);
…...
}
Dma map函数会调用iommu的map函数,用申请好的地址,设置iommu的映射表
static int rk_iommu_map(struct iommu_domain *domain, unsigned long _iova,
phys_addr_t paddr, size_t size, int prot)
{
……//为pt申请一个page
page_table = rk_dte_get_page_table(rk_domain, iova);
……
dte_index = rk_domain->dt[rk_iova_dte_index(iova)];
pte_index = rk_iova_pte_index(iova);
pte_addr = &page_table[pte_index];//pte表的首地址
pte_dma = rk_dte_pt_address(dte_index) + pte_index * sizeof(u32);
//物理地址存放到iommu的映射表中
ret = rk_iommu_map_iova(rk_domain, pte_addr, pte_dma, iova,
paddr, size, prot);
}
static size_t rk_iommu_map_sg(struct iommu_domain *domain, unsigned long iova,
struct scatterlist *sg, unsigned int nents, int prot)
{
……//应该是找到最小的size 为4k
min_pagesz = 1 << __ffs(domain->ops->pgsize_bitmap);
//
for_each_sg(sg, s, nents, i) {
phys_addr_t phys = page_to_phys(sg_page(s)) + s->offset;
//这个函数应该是可以把不同几段物理地址映射到连续地址,
//里面调用domain->ops->map,其实就是做多次map
ret = iommu_map(domain, iova + mapped, phys, s->length,
prot | IOMMU_INV_TLB_ENTIRE);
mapped += s->length;
}
rk_iommu_zap_tlb(domain);
}
这个结构描述的是分散的内存
struct scatterlist {
#ifdef CONFIG_DEBUG_SG
unsigned long sg_magic;
#endif
unsigned long page_link;// 指示该内存块所在的页面。要求page最低4字节对齐
unsigned int offset;// 指示该内存块在页面中的偏移
unsigned int length;// 该内存块的长度
dma_addr_t dma_address;// 该内存块实际的起始地址
#ifdef CONFIG_NEED_SG_DMA_LENGTH
unsigned int dma_length;//相应信息长度
#endif
};
看这个要求,所有的地址和长度都有4k对齐要求,在iommu_map里面有体现。
rk_iommu_iova_to_phys这个函数其实就是在操作dma里的dma_map_ops函数时候会调用。关于前面调用情况,仔细去了解dma
看看
static phys_addr_t rk_iommu_iova_to_phys(struct iommu_domain *domain,
dma_addr_t iova)
{
struct rk_iommu_domain *rk_domain = to_rk_domain(domain);
phys_addr_t pt_phys, phys = 0;
u32 dte, pte;
u32 *page_table;
mutex_lock(&rk_domain->dt_lock);
dte = rk_domain->dt[rk_iova_dte_index(iova)];// //找到对应的目录
if (!rk_dte_is_pt_valid(dte))
goto out;
//(iova & RK_IOVA_PTE_MASK) >> RK_IOVA_PTE_SHIFT;
pt_phys = rk_dte_pt_address(dte);// //找到页码表对应的物理地址
page_table = (u32 *)phys_to_virt(pt_phys);// //找到页码表虚拟地址
pte = page_table[rk_iova_pte_index(iova)];// 找页也码的虚拟地址
if (!rk_pte_is_page_valid(pte))
goto out;
//页码的物理地址+偏移量
phys = rk_pte_page_address(pte) + rk_iova_page_offset(iova);
mutex_unlock(&rk_domain->dt_lock);
return phys;
}
这样看函数的意思是一个dt对应申请一个1024个pt,一组pt为1024*4k,就是4M
如果看不动注释,得懂这个函数就要弄懂地址结构
下面简述rk iommu存储结构
第一个寄存器MMU_DTE_ADDR存放的是DTE表的首地址,初始化驱动代码会调用get_zeroed_page申请一个4k页作为DTE表,DTE表有1024个单位,每个占4Byte.
然后调用dma_map_single将这个地址虚拟地址映射到总线地址(后面有总线地址介绍)。然后把这个地址放到MMU_DTE_ADDR寄存器中。其中每个DTE指向一个PTE表的首地址(注意是PTE表的物理地址)。PTE表的页是在rk_iommu_map中申请,先将这个物理地址虚化(我认为一般是线性的吧)。这地址里面的内容指向实际的页表的物理地址,然后再加上偏移量就是实际页的物理地址。(内存映射都是以页为单位的,找物理地址实际是找的页的物理地址)。
所以这样指地址,那么iova连续的情况,实际的物理地址可以不连续,dma搬运在有iommu的时候传入的是iova(总线地址)。Iommu可以实现转换。
iommu总线地址如下
所以,可以看的出来mmu的地址是由dte,pte,po组成。然后申请了专门的目录表 pte和po的内存,每个有对下一级的指向,就知道物理地址。
小结:仅个人观点
其实iommu都是由dma去申请内存,可能连续,也可能几段离散的,但是地址总线是连续的,申请好之后,需调用dma的map函数,map函数会调用到iommu函数里面分配页表,这样,dma就可以操作分段内存,因为有iommu的映射。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号