

学习进度(1)
今年过年真的是一点年味都没有了。因为疫情形势比较严峻,我们这里要求不要出去走亲访友。其实这样也好,不出去又安全又省事,在家里待着就能为国家做贡献。
昨天和今天看了点python,然后试着做了做爬取北京市政百姓信件的实验。
北京市政百姓信件列表的官网已经改变,用实验要求里给的网站只会显示无法打开该网页,后来百度才找到新的官网:http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.flow。实验要求里爬取信件用的是java,我要用的是python,所以只能自己慢慢琢磨了。
首先,在信件列表分页浏览区域点击下一页,发现顶层页面并未刷新,可能是使用了<iframe>元素或者Ajax技术。
其次,在某个信件链接上右键选择审查元素查看元素(Elements),或者F12打开开发者工具。定位到信件列表后发现父元素全是<div>,所以页面数据更新应该是使用了Ajax技术。
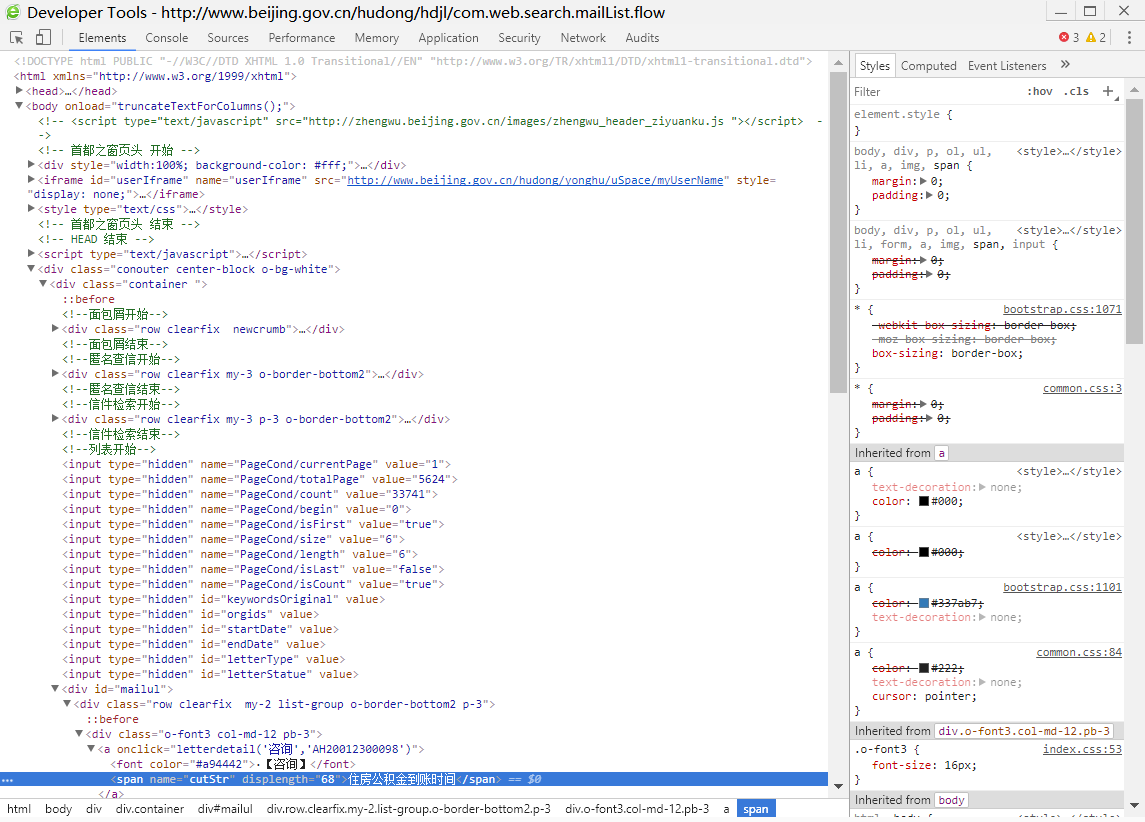
然后,开始寻找发送Ajax请求的脚本。终于在最下边的<script>元素里找到了分页函数。到这里还有些问题,这个Ajax请求发送的数据和接受的数据都是什么?点击开发者工具里的Network,在信件分页浏览处点击下一页,返回开发者工具,发现已经有了几条数据交换。根据找到的分页函数里Ajax请求地址,点击com.web.search.mailList.mailList.biz.ext这一项查看详情。Headers里是发送的数据,Response里是接收的数据。
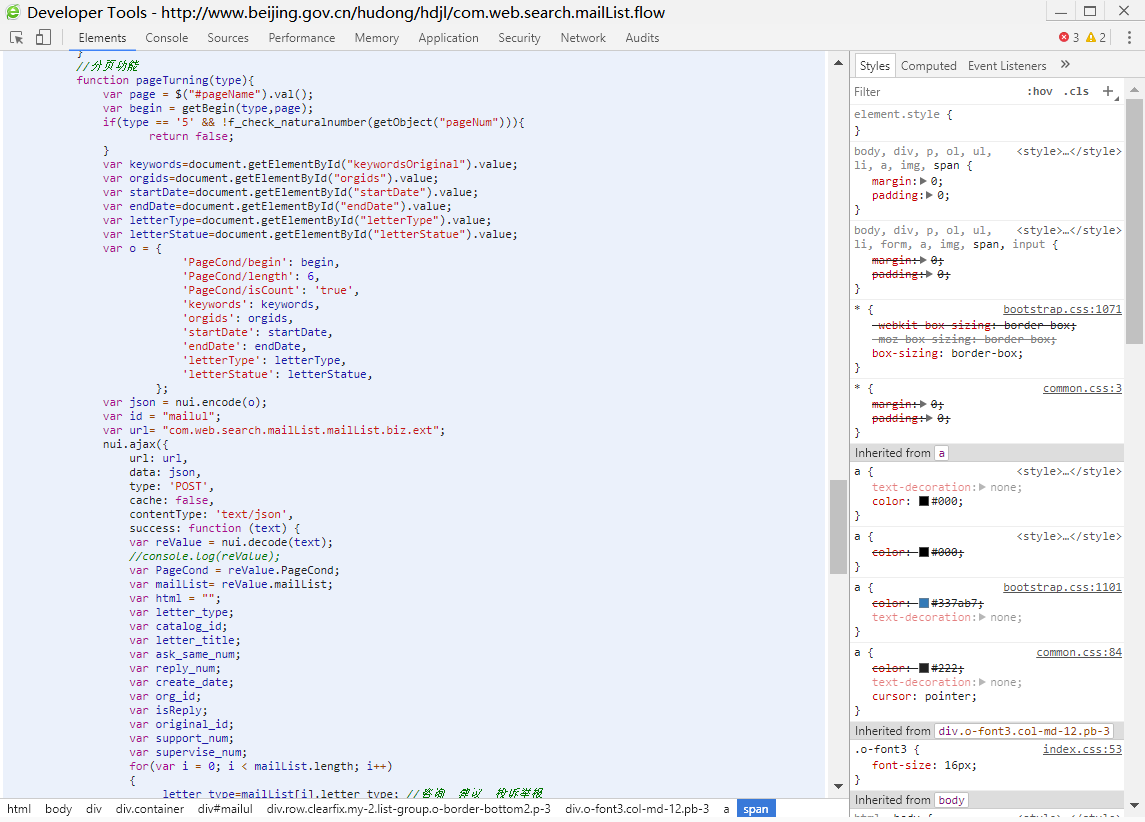
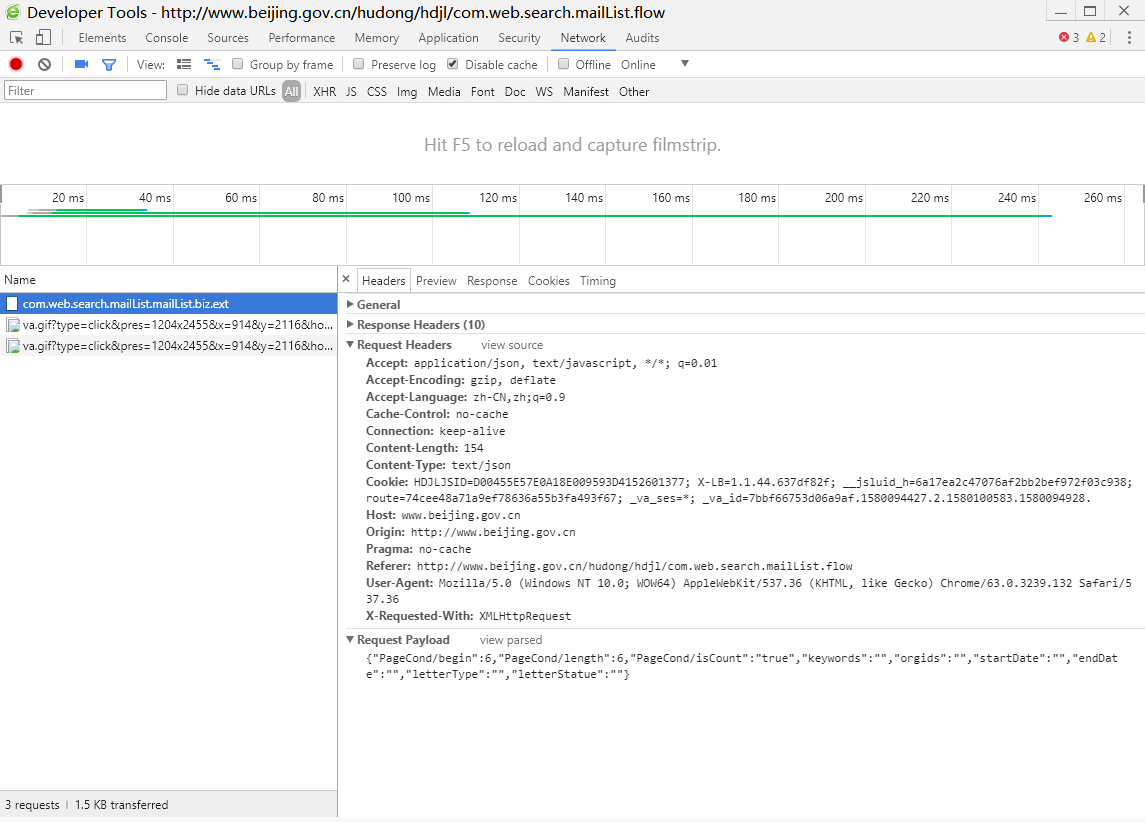
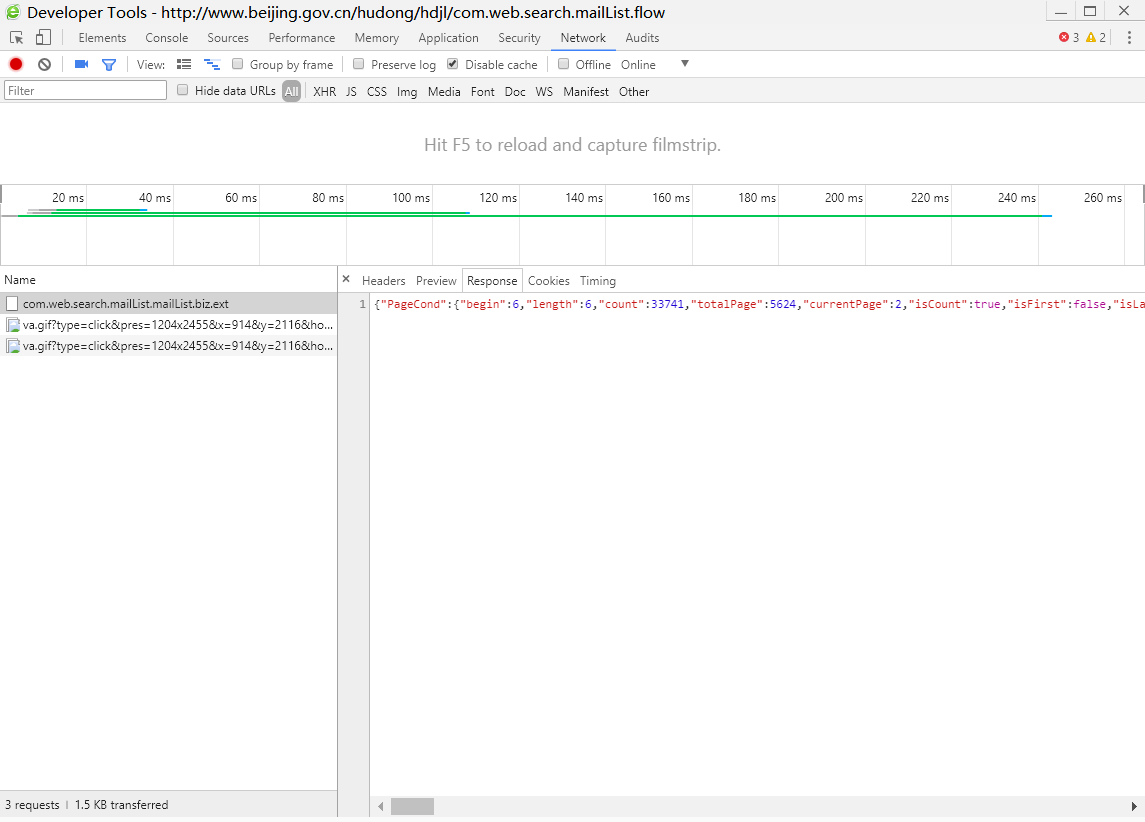
最后,使用python模拟Ajax请求,将这些信件全部爬取出来。多点击几次下一页,可以发现发送的数据中,begin是信件起始序号,length是获取的信件数量;接收的数据中,count是信件总数量,mailList是获取信件的概述。可以根据这些特点使用python脚本爬取所有信件。(这里爬取的信件是指标题,关键字,时间这些,具体内容需要另外爬取)
# -*- coding: utf-8 -*- """ Created on Mon Jan 26 9:35:00 2020 @author: 星辰° """ import json import requests import time def getContent(begin,length): url = 'http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.mailList.biz.ext' headers = { "Host": "www.beijing.gov.cn", "Connection": "keep-alive", "Content-Length": "155", "Pragma": "no-cache", "Cache-Control": "no-cache", "Accept": "application/json, text/javascript, */*; q=0.01", "Origin": "http://www.beijing.gov.cn", "X-Requested-With": "XMLHttpRequest", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36", "Content-Type": "text/json", "Referer": "http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.flow", "Accept-Encoding": "gzip, deflate", "Accept-Language": "zh-CN,zh;q=0.9", "Cookie": "HDJLJSID=88D9174C76DD6101B765BC08EBCC0042; __jsluid_h=5bf544c63ba671436f7a72dbea4f2107; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216fb37e42d93f-05d6c08984c92b-3c604504-2073600-16fb37e42db11e%22%7D; X-LB=1.1.44.637df82f; route=a2cec3cb28b0d59d32db7b39f74f56a5; _va_ref=%5B%22%22%2C%22%22%2C1579688489%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3D_YgZhWCf_Bktk-Qmd0FW46ZrmtOPvEAUxLo3-rLKpBuJ4lAGvTZ1-MNDKfbQzyA3%26wd%3D%26eqid%3Dbf36854b000546f7000000025e21a840%22%5D; _va_ses=*; _va_id=953201576463cf85.1579264069.4.1579691692.1579688489." } #即使定义的时候格式为json标准格式,python也会认为这是python字典,自动将双引号改成单引号 data = { "PageCond/begin":begin, "PageCond/length":length, "PageCond/isCount":"true", "keywords":"", "orgids":"", "startDate":"", "endDate":"", "letterType":"", "letterStatue":"" } #print(type(data)) #print(data) #print(type(json.dumps(data))) #print(json.dumps(data)) #模拟Ajax,data数据必须格式化为标准json数据格式,否则结果会是<Response [500]> #headers不能格式化,必须用dist类型 res = requests.post(url, data=json.dumps(data), headers=headers) return res.text if __name__ == '__main__': count = json.loads(getContent(0,1))["PageCond"]["count"] print(f"count:{count}") f = open("data.txt","w",encoding="utf-8") f.write("letter_type;original_id;catalog_id;letter_title;create_date;org_id;keywords;letter_status;ask_same_num;reply_num;support_num;supervise_num;isReply") f.write("\r\n") begin = 0 length = 1000 while begin < count: if(begin + length > count): length = count - begin start = time.time() mailList = json.loads(getContent(begin,length))["mailList"] for mail in mailList: string = json.dumps(mail["letter_type"],ensure_ascii=False) + ";" string += json.dumps(mail["original_id"],ensure_ascii=False) + ";" string += json.dumps(mail["catalog_id"],ensure_ascii=False) + ";" string += json.dumps(mail["letter_title"],ensure_ascii=False) + ";" string += json.dumps(mail["create_date"],ensure_ascii=False) + ";" string += json.dumps(mail["org_id"],ensure_ascii=False) + ";" string += json.dumps(mail["keywords"],ensure_ascii=False) + ";" string += json.dumps(mail["letter_status"],ensure_ascii=False) + ";" string += json.dumps(mail["ask_same_num"],ensure_ascii=False) + ";" string += json.dumps(mail["reply_num"],ensure_ascii=False) + ";" string += json.dumps(mail["support_num"],ensure_ascii=False) + ";" string += json.dumps(mail["supervise_num"],ensure_ascii=False) + ";" string += json.dumps(mail["isReply"],ensure_ascii=False) string += "\r\n" string = string.replace('"','') f.write(string) spend_time = time.time() - start print(f"begin:{begin},length:{length},spend time:{spend_time}s") begin += length f.close()
运行结果:
感觉这样按顺序爬取很浪费时间,这才爬了3万多条数据,而且每条数据内容又很少,都用了2分钟左右。如果数据更复杂更繁多,就会浪费更多时间。这两天琢磨一下python多线程的内容,争取使用多线程来实现爬取信件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号