【算法】CRF(条件随机场)
CRF(条件随机场)
基本概念
- 场是什么
场就是一个联合概率分布。比如有3个变量,y1,y2,y3, 取值范围是{0,1}。联合概率分布就是{P(y2=0|y1=0,y3=0), P(y3=0|y1=0,y2=0), P(y2=0|y1=1,y3=0), P(y3=0|y1=1,y2=0), ...}
下图就是一个场的简单示意图。
![]()
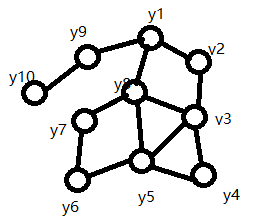
也就是变量间取值的概率分布。
2. 马尔科夫随机场
如果场中的变量只受相邻变量的影响,而与其他变量无关。则这样的场叫做马尔科夫随机场。
如下图,绿色点变量的取值只受周围相邻的红色点变量影响,与其他变量无关。
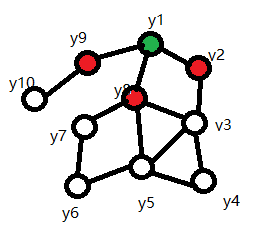
-
条件随机场
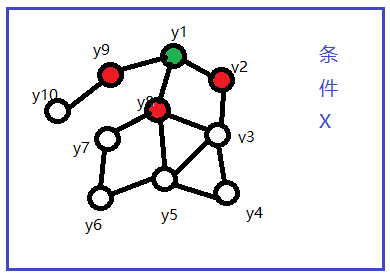
有随机变量X(x1,x2,...), Y(y1,y2,...), 在给定X的条件下Y的概率分布是P(Y|X)。如果该分布满足马尔科夫性,即只和相邻变量有关,则称为条件随机场。
如下图,与马尔科夫随机场的区别是多了条件X。
![]()
-
线性链条件随机场
随机变量Y成线性,即每个变量只和前后变量相关。
当条件X与变量Y的形式相同时,就是如下图所示的线性链条件随机场。该形式也是最常使用的,广泛用于词性标注,命名实体识别等问题。
![]()
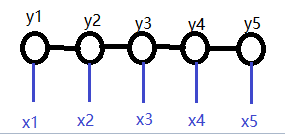
对于词性标注来说,x就是输入语句的每一个字,y就是输出的每个字的词性。
线性链条件随机场的表示
设\(P(Y|X)\)是线性链条件随机场,则在给定\(X\)的取值\(x\)的情况下,随机变量\(Y\)取值为\(y\)的条件概率可以表达为:
\(i\): 表示当前位置下标
\(t_k()\):表示相邻两个输出间的关系,是转移特征函数。取值{0,1},即满足特征和不满足特征
\(s_l()\): 表示当前位置的特征,是状态特征函数。取值{0,1}。
\(k\): 表示转移特征\(t\)的个数
\(l\): 表示状态特征\(s\)的个数
非规范化概率:\(P(Y|X)\)的分子部分
从定义角度来分析这个公式: 由于是条件随机场,即受条件影响,所以每一个\(t_k\)和\(s_k\)都有\(x\)的影响。同时,由于满足马尔科夫性,\(t_k\)只受\(y_i\)和\(y_{i-1}\)影响,即只受相邻变量影响。
从实际含义角度分析这个公式: 对于\(s_l\),比如输入汉字\(x\)为"门",对应位置\(y_i\)标注是名词n,则满足条件,取1。每一个\(s_l\)就是输入对输出词性的影响。对于\(t_k\),比如\(y_{i-1}\)是动词v,\(y_i\)是名词n则认为满足标记,取值1。也就是\(t_k\)表明了相邻输出间的约束关系。
条件随机场的化简形式和矩阵形式
为什么需要知道条件随机场的化简形式和矩阵形式?无他,仅仅是因为后面求解问题时用到了相关的数学表达而已。看公式的感觉很痛苦,一堆符号也不知道是什么,很烦。大家可能都有这样的感受。但是想真正理解条件随机场,这一步跳不过去啊。
条件随机场的化简形式
设有\(K_1\)个转移特征,\(K_2\)个状态特征,记
对所有位置\(i\)求和,记作
用\(\omega_k\)表示特征\(f_k(y,x)\)的权值,即
那么,条件随机场就可以用如下公式表示:
用\(\omega\)表示权值向量,即
用\(F(y,x)\)表示全局特征向量,即
则
条件随机场的矩阵形式
设\(y\)一共有\(m\)种取值,则定义一个\(m\times m\)的矩阵
\(M_i(y_{i-1},y_i|x)\)中的\(y\)取值是固定的,\(M_i(x)\)则是合并了所有可能的\(y\)取值,在矩阵表示下条件概率可以表达为\(P_\omega(y|x)\)
CRF涉及的三个问题
- 条件随机场的概率计算问题
- 条件随机场的学习算法
- 条件随机场的预测算法
条件随机场的概率计算问题
该问题是指,在已知条件随机场分布情况下,得出每个位置输出结果的可能性。
比如有一个长度为3的输入序列{1,2,3},每一个输出的取值范围是{0,1}。概率计算问题就是求出P(y1=0|X={1,2,3}),P(y1=1|X={1,2,3}),...。也就是求每个位置y取各个值得概率。
最开始我看这个问题的时候一直有一个困惑,什么叫做给定条件随机场。后来明白,给定条件随机场是指给定所有的约束条件,即给定所有的\(t_k\)和\(s_l\)函数以及相关权重。
这个概率计算问题在实际算法求解中并不常使用。但作为三个基本问题还是介绍一下处理的思路。
基本的处理思路是动态规划,借助了前向和后向向量。
前向向量:\(\alpha_i(y|x)\)表示,即不管从位置0到位置\(i-1\)部分\(y\)的取值,位置\(i\)取值为\(y\)的非规范化概率。
后向向量:\(\beta_i(y|x)\)表示,即不管从位置\(i+1\)到位置\(n\)部分\(y\)的取值,位置\(i\)取值为\(y\)的非规范化概率。
这样通过前向和后向向量就可以得出相关的概率计算问题解:
上面公式的详细推导可以参看李航的《统计学习方法》,这里只给出结果。很容易理解,因为前向向量隐藏了当前位置之前的取值细节,而后向向量隐藏了当前位置之后的取值细节,所以只需要关注当前位置取值就可以了。
条件随机场的学习算法
假设已经有一批输入和输出数据,已知所有可能的\(t_k\)和\(s_l\)函数,目标是求解合适的权重\(\omega_k\),使得训练样本出现的可能性最大。记住,目标是求权重\(\omega\)。为了实现这个目标,需要先定义目标函数,可以采用极大似然估计,用对数极大似然函数作为目标函数。
设输入样本为\((x=(1,2),y=(1,2)),(x=(1,3),y=(1,1)),(x=(2,3),y=(2,1))\)
设经验概率分布为\(\tilde{P}(X,Y)\),含义就是在输入样本中\(X,Y\)出现的频率,对于上面例子,\(\tilde{P}(X=(1,2),Y=(1,2))=\frac{1}{3}\)
那么对应的极大似然函数为:
相应的对数似然函数为:
使得\(L(\omega)\)取值最大的\(\omega\)就是我们要求的结果。
目标有了,后面就是数学的优化方法,梯度下降,牛顿法,改进的迭代尺度法,拟牛顿法都可以用。李航的书上重点介绍了改进的迭代尺度法和拟牛顿法。大家对细节感兴趣的可以仔细看看P88-P92以及P202-P205页。公式挺难的,我仅仅可以做到对着书上的公式知道它在做什么。
简单记录一下这两种方法的思路:
改进的迭代尺度法:思路是确立下界,并不断提升下界实现求解(PS:这个思路看着跟EM算法有点像)。首先根据\(-log\alpha\geq1-\alpha\)确立一个紧的下界。但该下界每次更新时需要调整所有的\(\omega_k\),不好求解。所以再根据凸函数的琴声不等式,确立一个相对不紧的下界,调整该下界每次只需更新一个\(\omega_k\)。这样通过不断迭代可以求得最优解。
拟牛顿法:利用二阶导数,用变量模拟海森矩阵,简化求解。
条件随机场的预测算法
条件随机场的预测算法是指给定条件随机场和输入序列,求最可能出现的输出序列。采用维特比算法,这也是一种动态规划算法。
目标是找到使下式最大化的\(y\),注意下式就是去掉了标准\(P(y|x)\)的分子\(Z(x)\)和分母上的\(exp\)函数部分,其最终结果是不受影响的。
其中,
维特比算法需要引入两个变量\(\delta_i(j)\)和\(\psi_i(l)\)
\(\delta_i(j)\),仅考虑从起始位置到到当前位置\(i\)这段序列,在位置\(i\)上,上面目标函数在\(y=j\)时取得的最大值
\(\psi_i(l)=j\),\(i\)表示当前位置,\(l\)表示当前位置\(y_i\)的取值,\(j\)是前一个位置\(y_{i-1}\)的取值。也就是记录最大值获取的路径。
递推公式:
上述公式之所以成立,也是因为满足马尔科夫性,所以每个位置的结果只受上一个位置结果的影响。
参考资料
- 李航《统计学习方法》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号